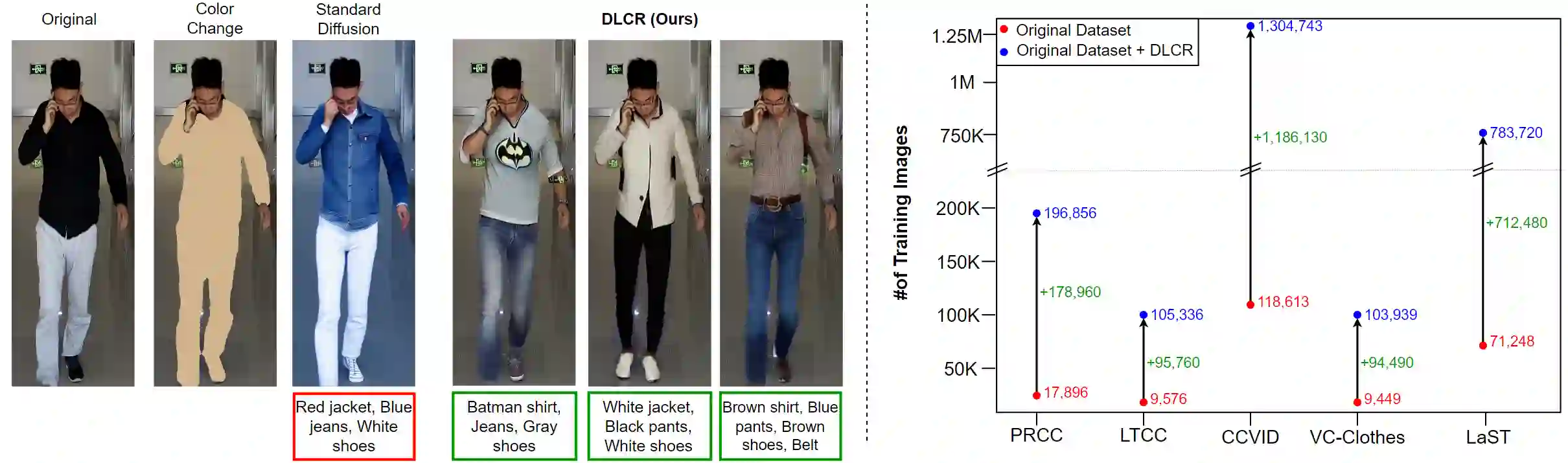
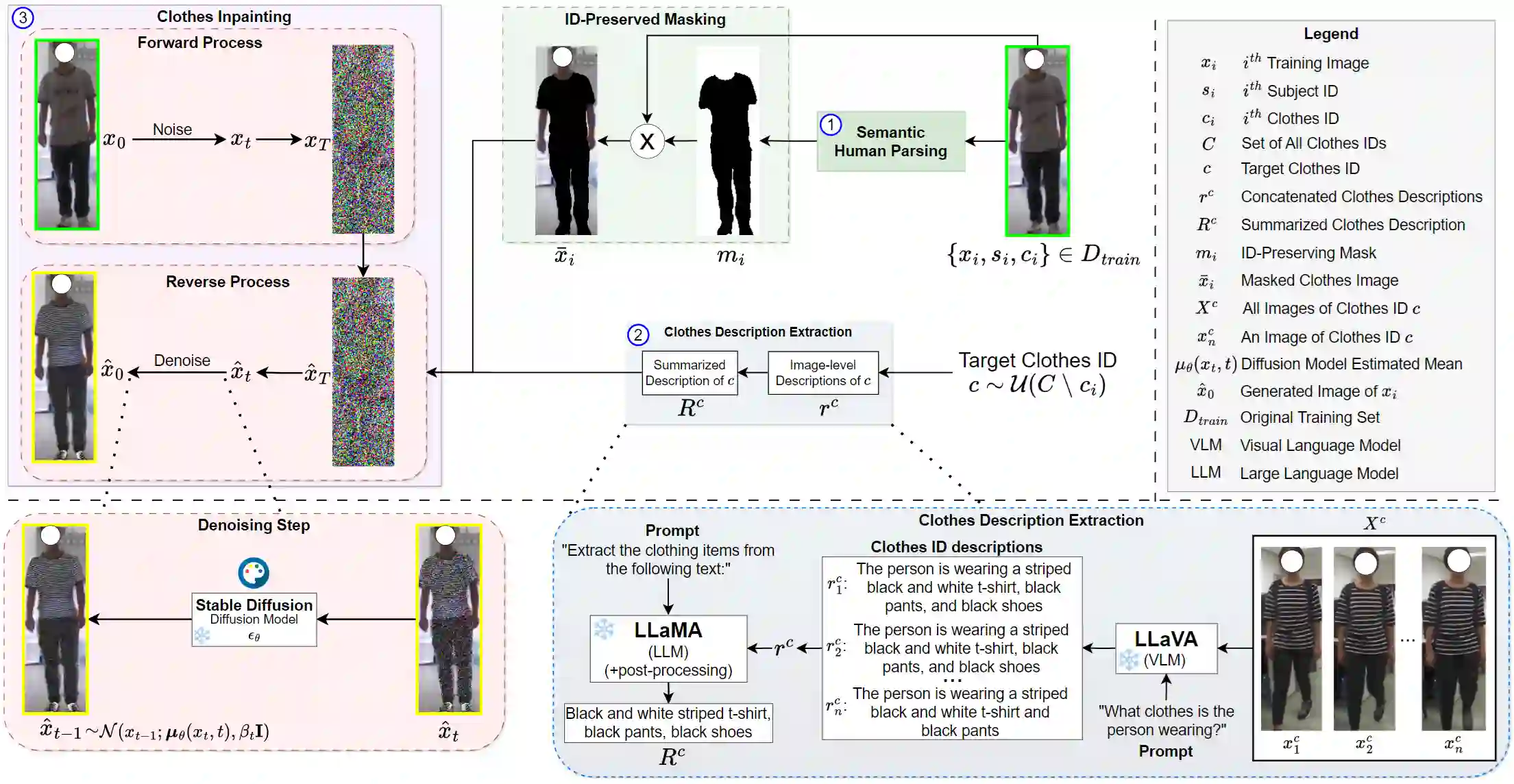
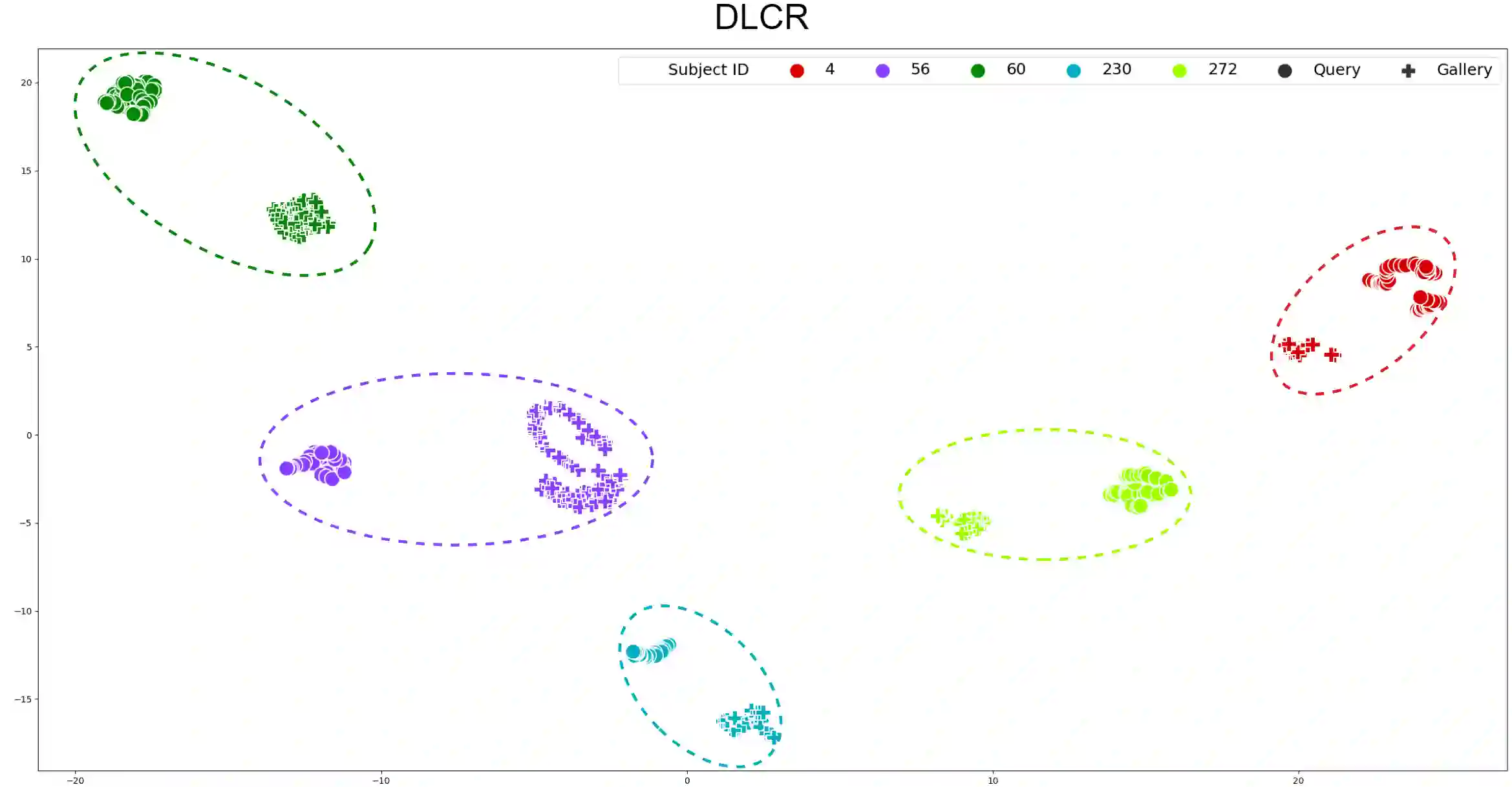
With the recent exhibited strength of generative diffusion models, an open research question is \textit{if images generated by these models can be used to learn better visual representations}. While this generative data expansion may suffice for easier visual tasks, we explore its efficacy on a more difficult discriminative task: clothes-changing person re-identification (CC-ReID). CC-ReID aims to match people appearing in non-overlapping cameras, even when they change their clothes across cameras. Not only are current CC-ReID models constrained by the limited diversity of clothing in current CC-ReID datasets, but generating additional data that retains important personal features for accurate identification is a current challenge. To address this issue we propose DLCR, a novel data expansion framework that leverages pre-trained diffusion and large language models (LLMs) to accurately generate diverse images of individuals in varied attire. We generate additional data for five benchmark CC-ReID datasets (PRCC, CCVID, LaST, VC-Clothes, and LTCC) and \textbf{increase their clothing diversity by \boldmath{$10$}x, totaling over \boldmath{$2.1$}M images generated}. DLCR employs diffusion-based text-guided inpainting, conditioned on clothing prompts constructed using LLMs, to generate synthetic data that only modifies a subject's clothes while preserving their personally identifiable features. With this massive increase in data, we introduce two novel strategies - progressive learning and test-time prediction refinement - that respectively reduce training time and further boosts CC-ReID performance. On the PRCC dataset, we obtain a large top-1 accuracy improvement of $11.3\%$ by training CAL, a previous state of the art (SOTA) method, with DLCR-generated data. We publicly release our code and generated data for each dataset here: \url{https://github.com/CroitoruAlin/dlcr}.
翻译:随着生成式扩散模型近期展现的强大能力,一个开放的研究问题是:\textit{这些模型生成的图像能否用于学习更好的视觉表示?}虽然这种生成式数据扩展可能足以应对较简单的视觉任务,但我们探索了其在更具挑战性的判别性任务上的有效性:换装行人再识别(CC-ReID)。CC-ReID旨在匹配出现在非重叠摄像头中的人员,即使他们在不同摄像头间更换了服装。当前的CC-ReID模型不仅受限于现有CC-ReID数据集中服装多样性的不足,而且生成能够保留重要个人特征以进行准确识别的额外数据也是当前的挑战。为解决这一问题,我们提出了DLCR,一种新颖的数据扩展框架,利用预训练的扩散模型和大语言模型(LLMs)来准确生成穿着多样化服装的个体图像。我们为五个基准CC-ReID数据集(PRCC、CCVID、LaST、VC-Clothes和LTCC)生成了额外数据,\textbf{将其服装多样性提高了\boldmath{$10$}倍,总计生成超过\boldmath{$2.1$}M张图像}。DLCR采用基于扩散的文本引导修复技术,通过LLMs构建的服装提示进行条件控制,生成仅修改主体服装而保留其个人可识别特征的合成数据。借助数据量的大幅增加,我们引入了两种新颖策略——渐进式学习和测试时预测优化——分别减少了训练时间并进一步提升了CC-ReID性能。在PRCC数据集上,通过使用DLCR生成的数据训练先前的最先进方法CAL,我们获得了$11.3\%$的大幅top-1准确率提升。我们在此公开发布每个数据集的代码和生成数据:\url{https://github.com/CroitoruAlin/dlcr}。