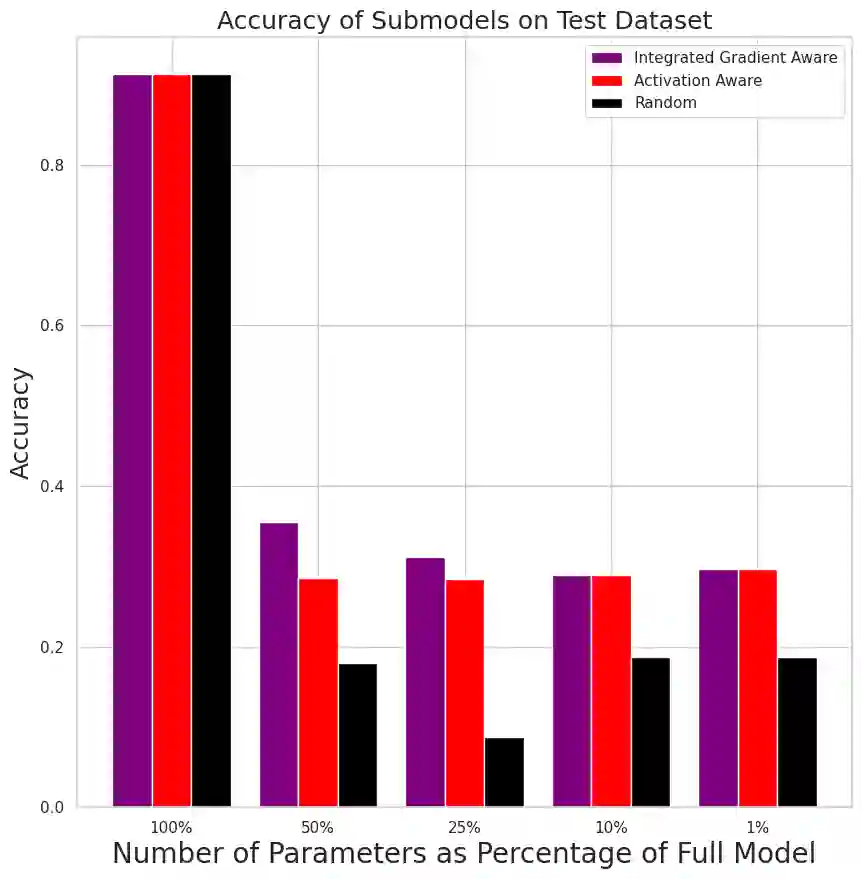
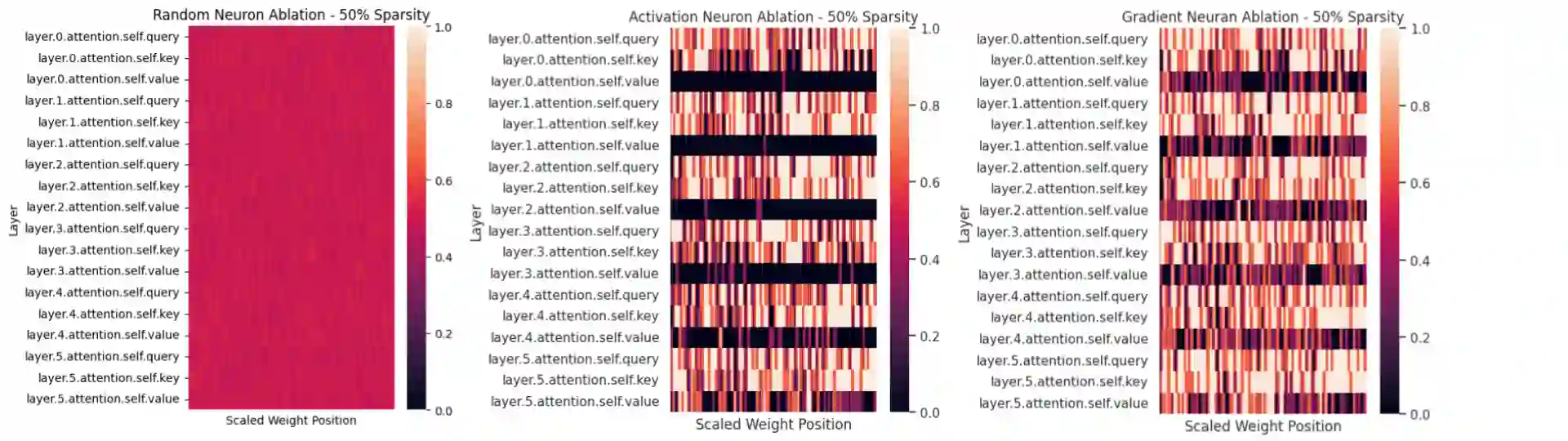
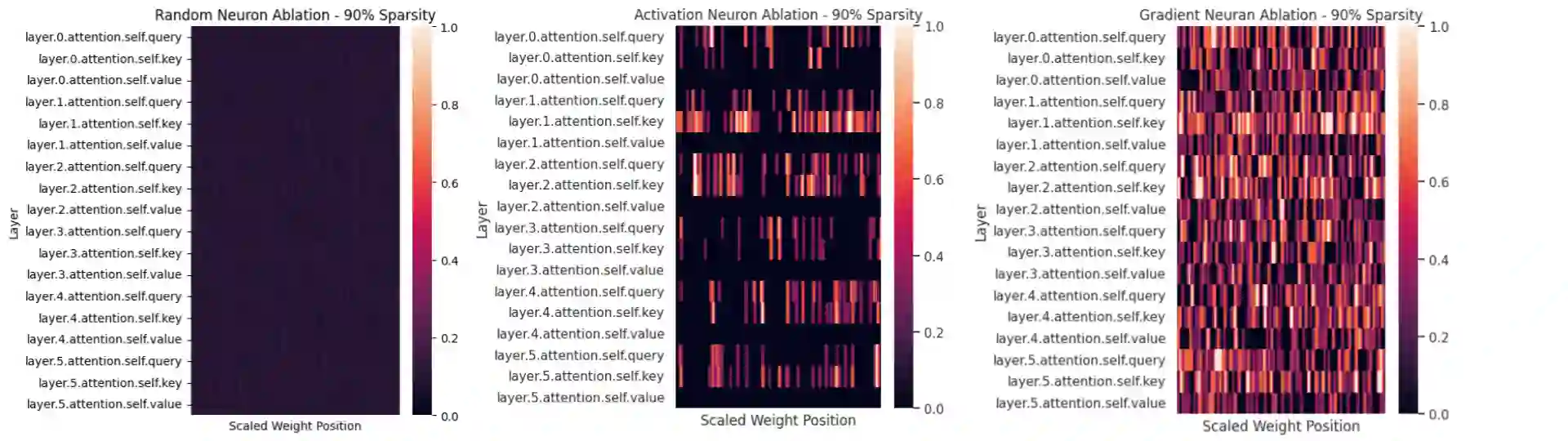
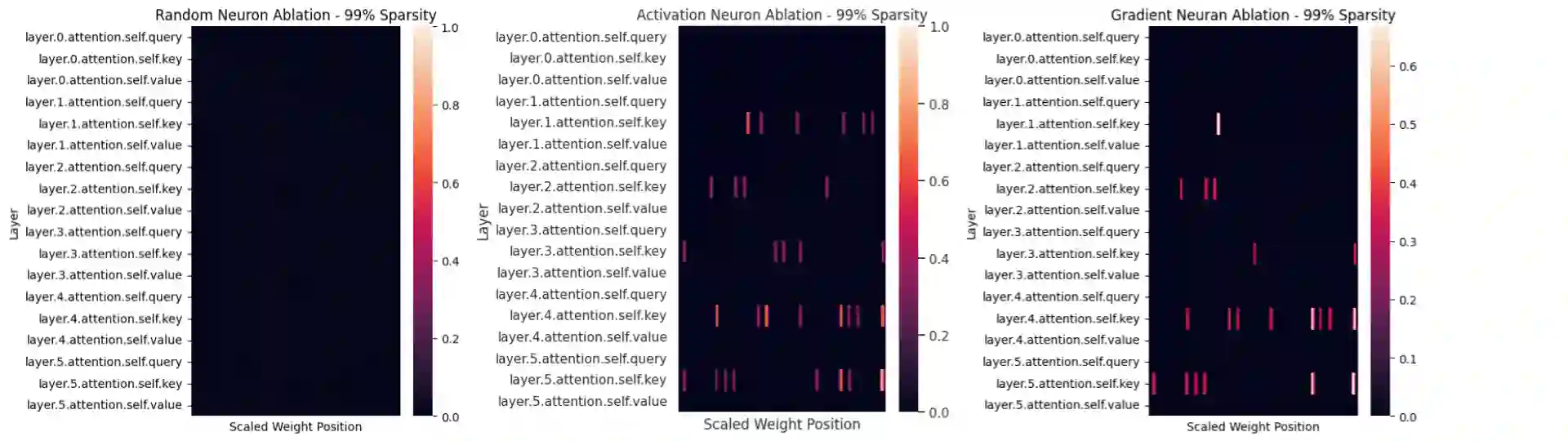
Neural language models have become powerful tools for learning complex representations of entities in natural language processing tasks. However, their interpretability remains a significant challenge, particularly in domains like computational biology where trust in model predictions is crucial. In this work, we aim to enhance the interpretability of protein language models, specifically the state-of-the-art ESM model, by identifying and characterizing knowledge neurons - components that express understanding of key information. After fine-tuning the ESM model for the task of enzyme sequence classification, we compare two knowledge neuron selection methods that preserve a subset of neurons from the original model. The two methods, activation-based and integrated gradient-based selection, consistently outperform a random baseline. In particular, these methods show that there is a high density of knowledge neurons in the key vector prediction networks of self-attention modules. Given that key vectors specialize in understanding different features of input sequences, these knowledge neurons could capture knowledge of different enzyme sequence motifs. In the future, the types of knowledge captured by each neuron could be characterized.
翻译:神经语言模型已成为自然语言处理任务中学习实体复杂表示的有力工具。然而,其可解释性仍面临重大挑战,尤其是在计算生物学等对模型预测可信度要求极高的领域。本研究旨在通过识别和表征表达关键信息理解能力的知识神经元,增强蛋白质语言模型(特别是当前最先进的ESM模型)的可解释性。在对ESM模型进行酶序列分类任务微调后,我们比较了两种从原始模型中保留部分神经元的知识神经元筛选方法。基于激活值和基于积分梯度的两种筛选方法均显著优于随机基线。特别值得注意的是,这些方法表明自注意力模块的关键向量预测网络中知识神经元密度较高。鉴于关键向量专门负责理解输入序列的不同特征,这些知识神经元可能捕获了不同酶序列基序的知识。未来可进一步表征每个神经元所捕获的知识类型。