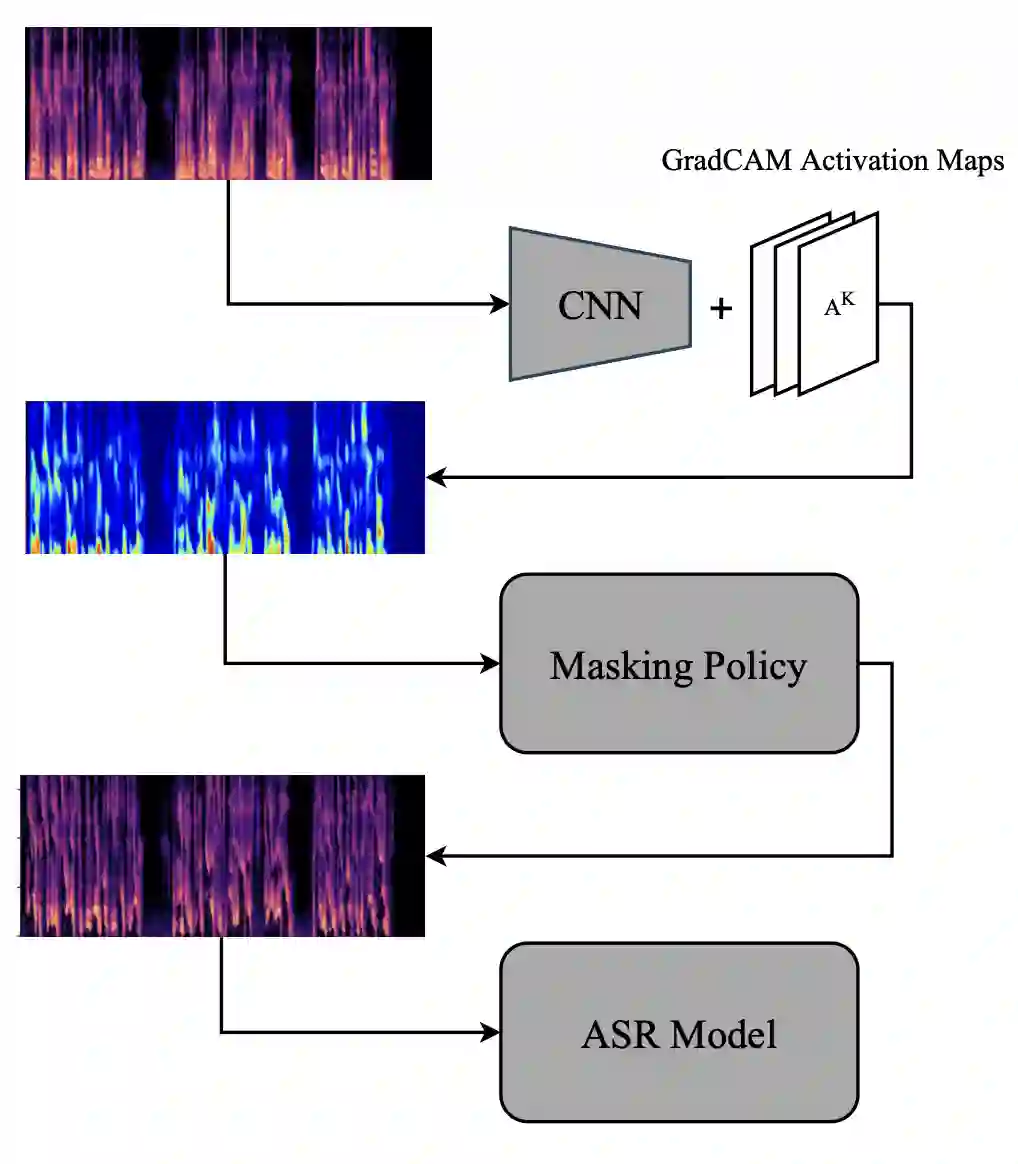
Pre-trained transformer-based models have significantly advanced automatic speech recognition (ASR), yet they remain sensitive to accent and dialectal variations, resulting in elevated word error rates (WER) in linguistically diverse languages such as English and Persian. To address this challenge, we propose an accent-invariant ASR framework that integrates accent and dialect classification into the recognition pipeline. Our approach involves training a spectrogram-based classifier to capture accent-specific cues, masking the regions most influential to its predictions, and using the masked spectrograms for data augmentation. This enhances the robustness of ASR models against accent variability. We evaluate the method using both English and Persian speech. For Persian, we introduce a newly collected dataset spanning multiple regional accents, establishing the first systematic benchmark for accent variation in Persian ASR that fills a critical gap in multilingual speech research and provides a foundation for future studies on low-resource, linguistically diverse languages. Experimental results with the Whisper model demonstrate that our masking and augmentation strategy yields substantial WER reductions in both English and Persian settings, confirming the effectiveness of the approach. This research advances the development of multilingual ASR systems that are resilient to accent and dialect diversity. Code and dataset are publicly available at: https://github.com/MH-Sameti/Accent_invariant_ASR
翻译:预训练的基于Transformer的模型已显著推进了自动语音识别(ASR)的发展,但它们仍对口音和方言变化敏感,导致在英语和波斯语等多语言中词错误率(WER)升高。为应对这一挑战,我们提出了一种口音不变的ASR框架,将口音和方言分类整合到识别流程中。我们的方法包括训练一个基于频谱图的分类器以捕捉口音特定线索,掩蔽对其预测影响最大的区域,并使用掩蔽后的频谱图进行数据增强。这增强了ASR模型对口音变化的鲁棒性。我们使用英语和波斯语语音对该方法进行评估。对于波斯语,我们引入了一个新收集的涵盖多个地区口音的数据集,建立了波斯语ASR中口音变化的第一个系统性基准,填补了多语言语音研究中的一个关键空白,并为未来关于低资源、语言多样性的研究奠定了基础。使用Whisper模型的实验结果表明,我们的掩蔽和增强策略在英语和波斯语设置中均实现了显著的WER降低,证实了该方法的有效性。这项研究推进了能够适应口音和方言多样性的多语言ASR系统的发展。代码和数据集公开于:https://github.com/MH-Sameti/Accent_invariant_ASR