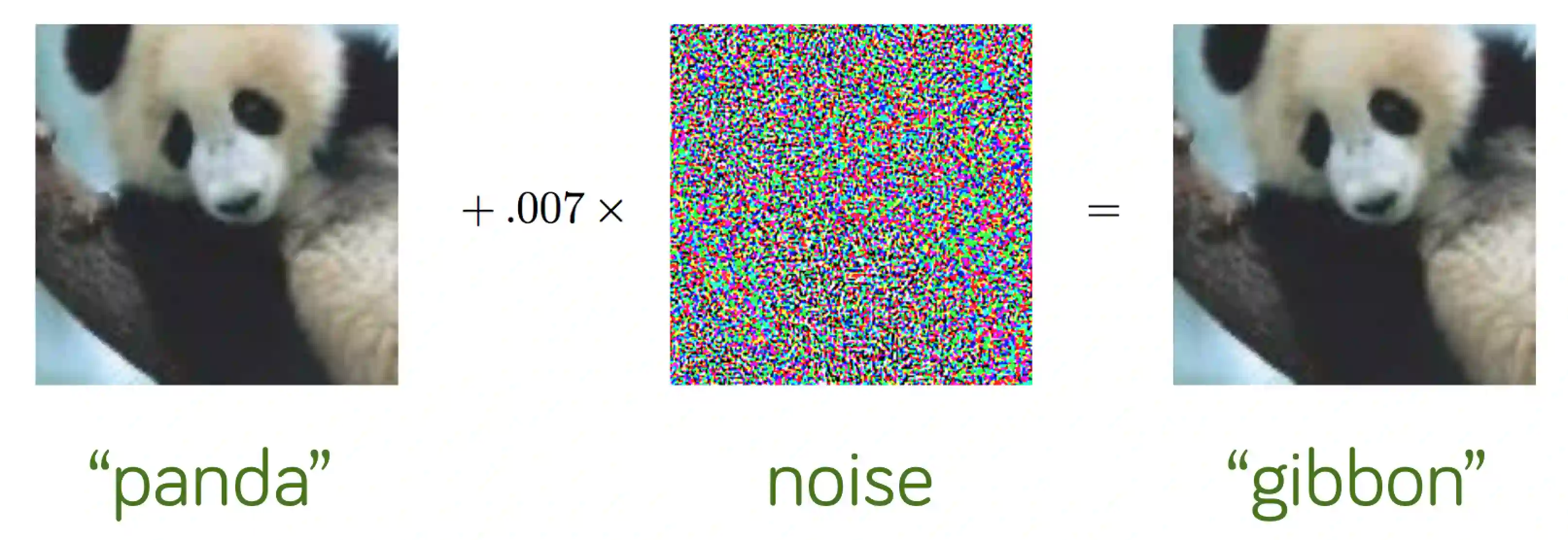
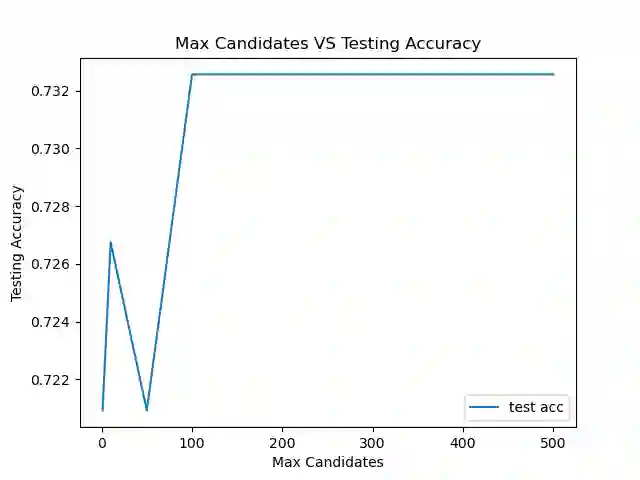
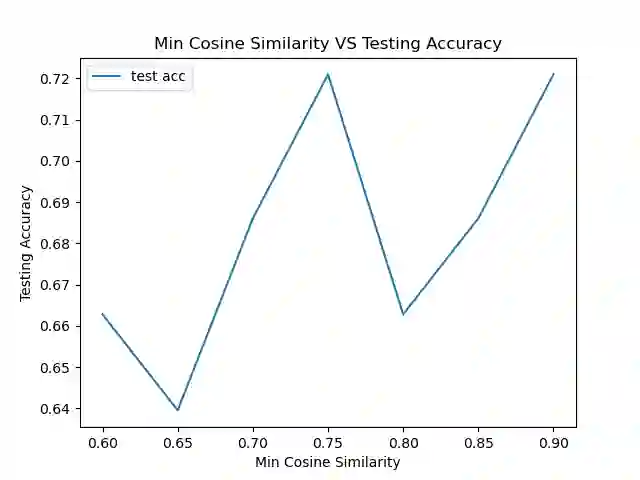
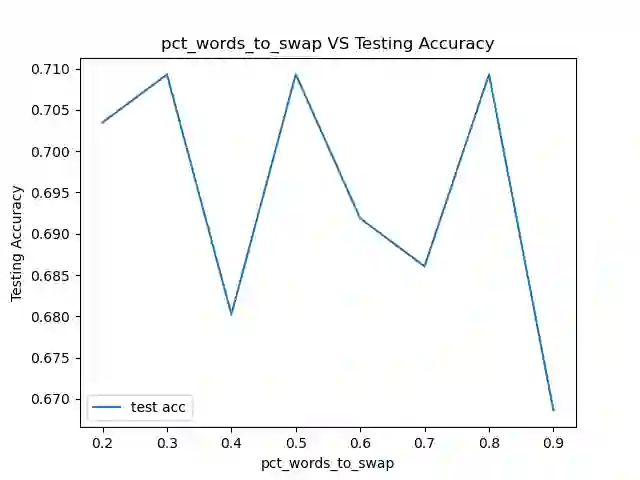
As the deployment of NLP systems in critical applications grows, ensuring the robustness of large language models (LLMs) against adversarial attacks becomes increasingly important. Large language models excel in various NLP tasks but remain vulnerable to low-cost adversarial attacks. Focusing on the domain of conversation entailment, where multi-turn dialogues serve as premises to verify hypotheses, we fine-tune a transformer model to accurately discern the truthfulness of these hypotheses. Adversaries manipulate hypotheses through synonym swapping, aiming to deceive the model into making incorrect predictions. To counteract these attacks, we implemented innovative fine-tuning techniques and introduced an embedding perturbation loss method to significantly bolster the model's robustness. Our findings not only emphasize the importance of defending against adversarial attacks in NLP but also highlight the real-world implications, suggesting that enhancing model robustness is critical for reliable NLP applications.
翻译:随着NLP系统在关键应用中的部署日益增多,确保大型语言模型(LLMs)对对抗攻击的鲁棒性变得愈发重要。大型语言模型在各种NLP任务中表现出色,但仍易受低成本对抗攻击的影响。聚焦于对话蕴含领域——其中多轮对话作为前提来验证假设,我们微调了一个基于Transformer的模型,以准确辨别这些假设的真伪。攻击者通过同义词替换操纵假设,试图欺骗模型做出错误预测。为抵御这些攻击,我们实施了创新的微调技术,并引入了一种嵌入扰动损失方法,显著增强了模型的鲁棒性。我们的研究结果不仅强调了在NLP中防御对抗攻击的重要性,还揭示了其现实意义,表明增强模型鲁棒性对于实现可靠的NLP应用至关重要。