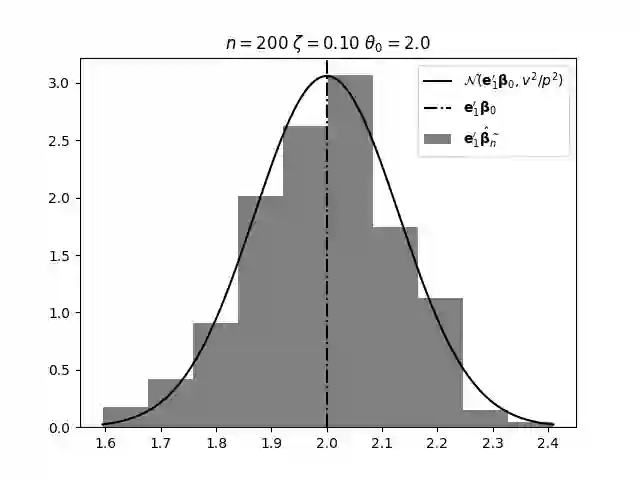
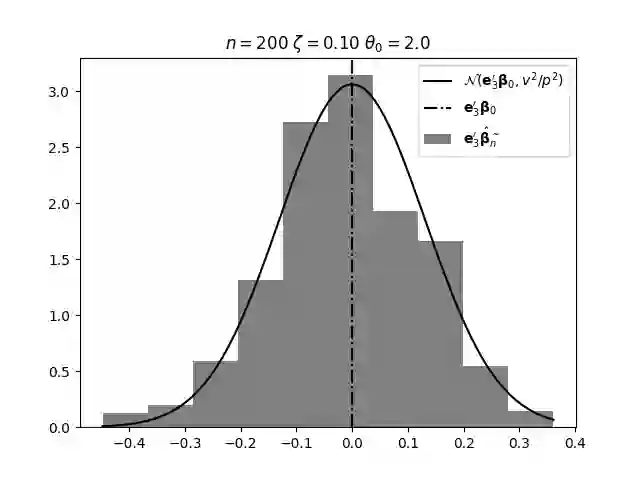
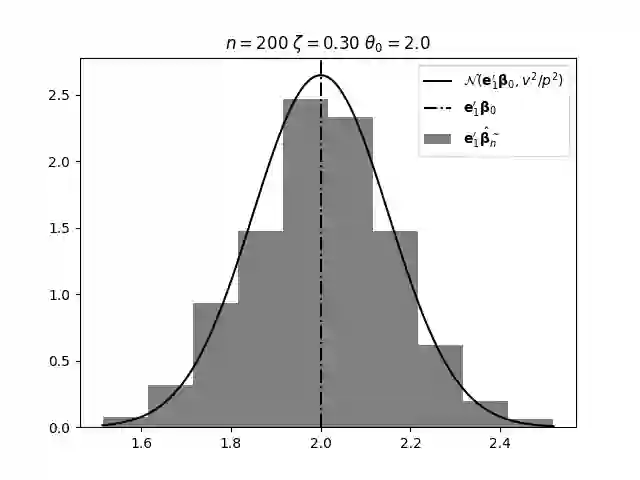
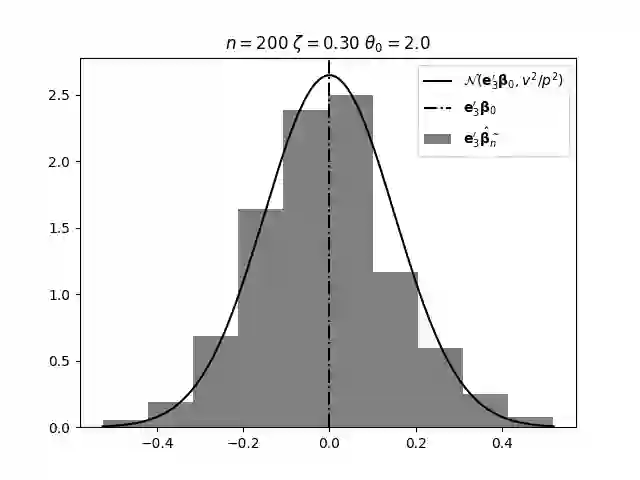
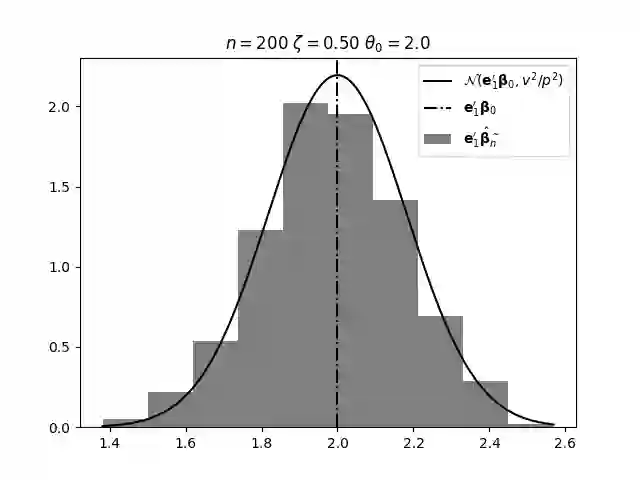
Regression analysis based on many covariates is becoming increasingly common. However, when the number of covariates $p$ is of the same order as the number of observations $n$, statistical protocols like maximum likelihood estimation of regression and nuisance parameters become unreliable due to overfitting. Overfitting typically leads to systematic estimation biases, and to increased estimator variances. It is crucial to be able to correctly quantify these effects, for inference and prediction purposes. In literature, several methods have been proposed to overcome overfitting bias or adjust estimates. The vast majority of these focus on the regression parameters only, either via empirical regularization methods or by expansion for small ratios $p/n$. This failure to correctly estimate also the nuisance parameters may lead to significant errors in outcome predictions. In this paper we use the leave one out method to derive the compact set of non-linear equations for the overfitting biases of maximum likelihood (ML) estimators in parametric regression models, as obtained previously using the replica method. We show that these equations enable one to correct regression and nuisance parameter estimators, and make them asymptotically unbiased. To illustrate the theory we performed simulation studies for multiple regression models. In all cases we find excellent agreement between theory and simulations.
翻译:基于大量协变量的回归分析正变得越来越普遍。然而,当协变量数量$p$与观测数量$n$处于同一数量级时,诸如回归参数和干扰参数的最大似然估计等统计方法会因过拟合而变得不可靠。过拟合通常会导致系统性估计偏差,并增大估计量的方差。为了进行推断和预测,正确量化这些效应至关重要。文献中已提出多种方法来克服过拟合偏差或调整估计值。这些方法绝大多数仅关注回归参数,要么通过经验正则化方法,要么通过小比率$p/n$下的展开式。未能正确估计干扰参数可能导致结果预测中的显著误差。本文利用留一法推导了参数回归模型中最大似然估计量过拟合偏差的紧凑非线性方程组,这些方程组此前是通过复制方法获得的。我们证明,这些方程能够校正回归参数和干扰参数估计量,并使其渐近无偏。为阐明这一理论,我们针对多个回归模型进行了模拟研究。在所有情况下,理论与模拟结果之间均表现出极好的一致性。