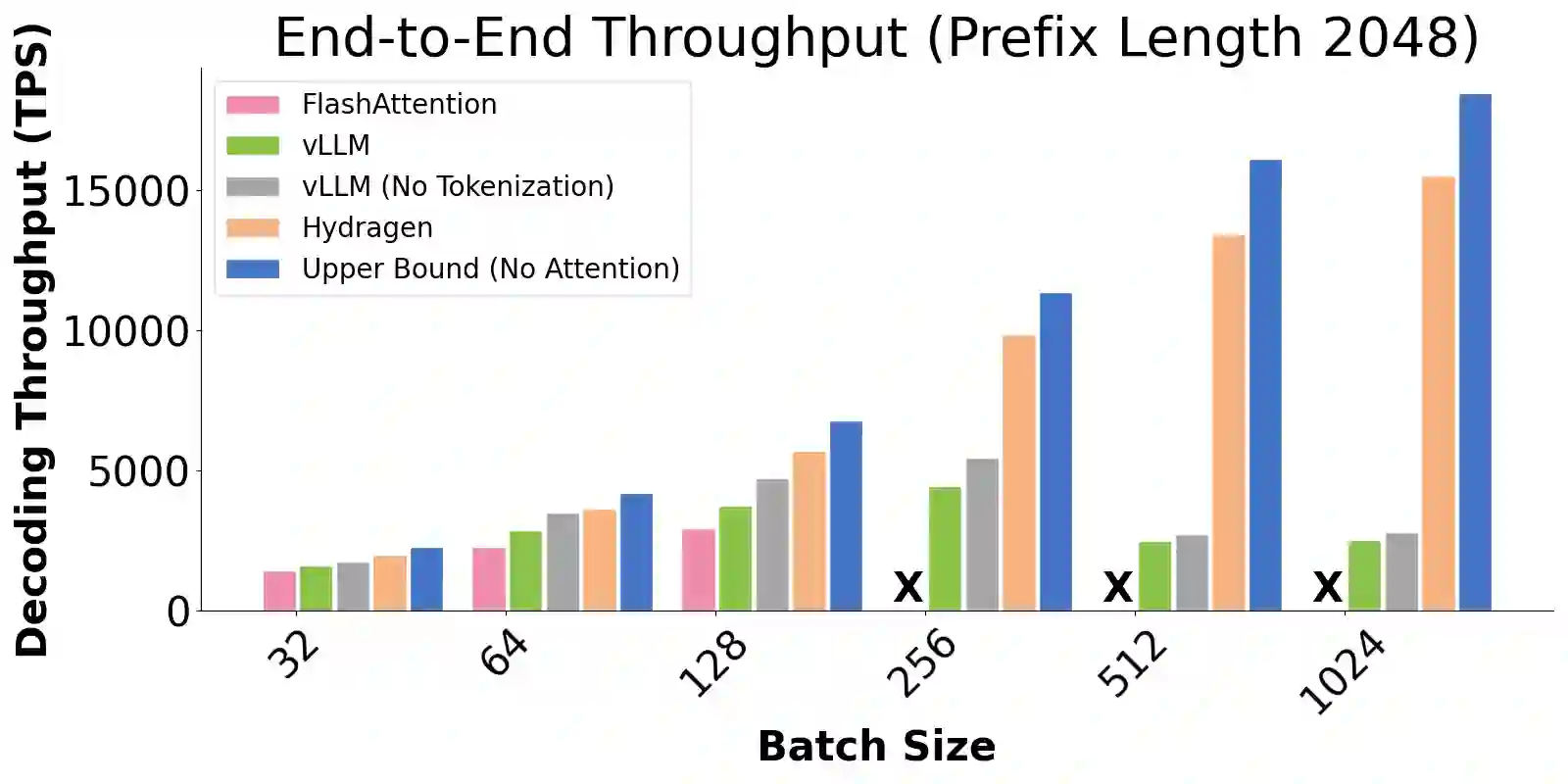
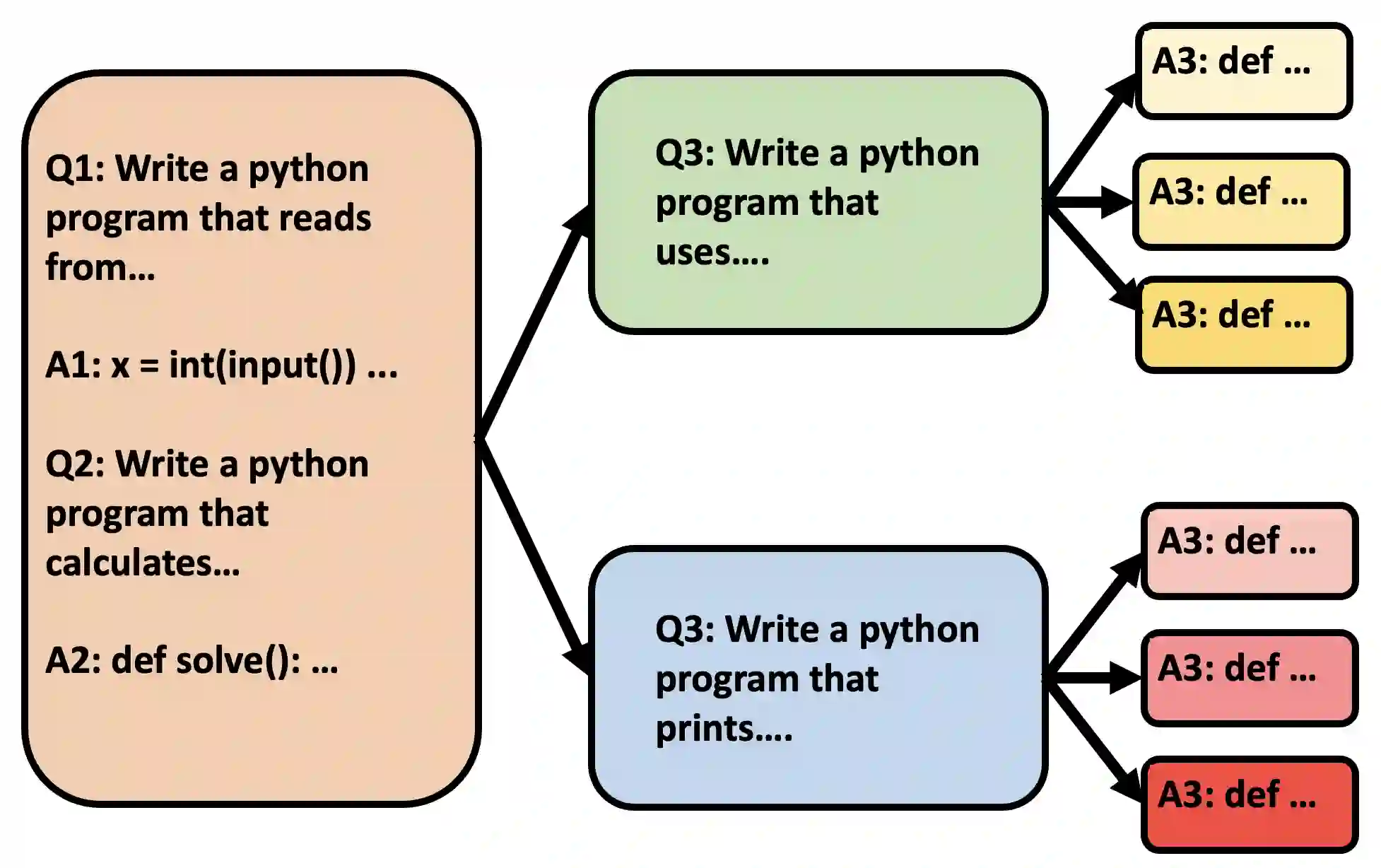
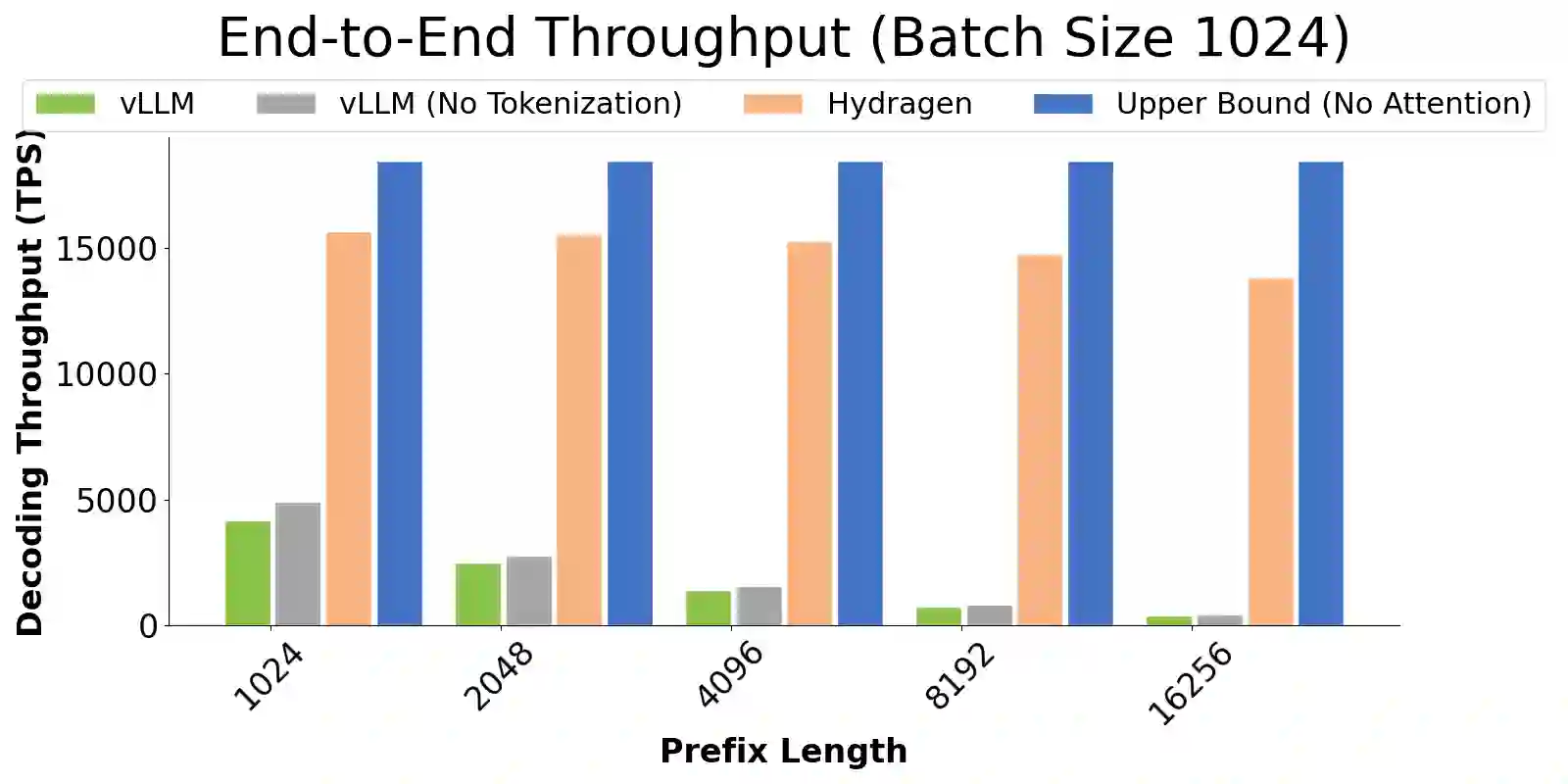
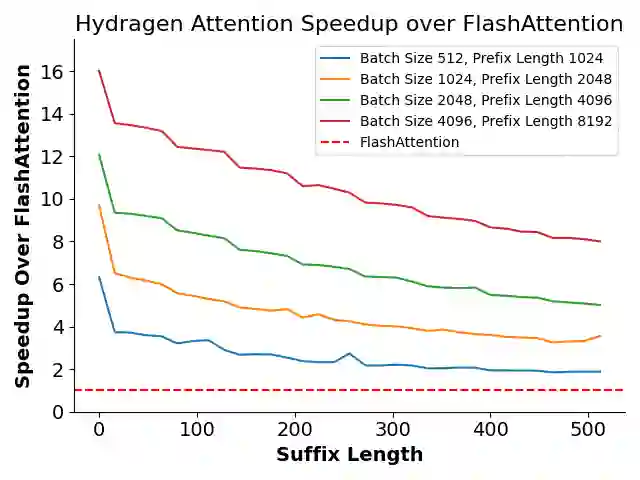
Transformer-based large language models (LLMs) are now deployed to hundreds of millions of users. LLM inference is commonly performed on batches of sequences that share a prefix, such as few-shot examples or a chatbot system prompt. Decoding in this large-batch setting can be bottlenecked by the attention operation, which reads large key-value (KV) caches from memory and computes inefficient matrix-vector products for every sequence in the batch. In this work, we introduce Hydragen, a hardware-aware exact implementation of attention with shared prefixes. Hydragen computes attention over the shared prefix and unique suffixes separately. This decomposition enables efficient prefix attention by batching queries together across sequences, reducing redundant memory reads and enabling the use of hardware-friendly matrix multiplications. Our method can improve end-to-end LLM throughput by up to 32x against competitive baselines, with speedup growing with the batch size and shared prefix length. Hydragen also enables the use of very long shared contexts: with a high batch size, increasing the prefix length from 1K to 16K tokens decreases Hydragen throughput by less than 15%, while the throughput of baselines drops by over 90%. Hydragen generalizes beyond simple prefix-suffix decomposition and can be applied to tree-based prompt sharing patterns, allowing us to further reduce inference time on competitive programming problems by 55%.
翻译:基于Transformer的大语言模型如今已服务于数亿用户。大语言模型推理通常处理共享前缀的序列批次,例如少样本示例或聊天机器人系统提示。在这种大批量解码场景中,注意力操作可能成为瓶颈——它需要从内存中读取大型键值缓存,并为批次中的每个序列计算低效的矩阵向量积。本文提出Hydragen,一种面向共享前缀的硬件感知精确注意力实现方法。Hydragen分别计算共享前缀与独立后缀的注意力。这种分解通过跨序列批量处理查询实现高效前缀注意力,既减少了冗余内存读取,又支持硬件友好的矩阵乘法操作。相较于竞争基线方法,本方法可实现端到端大语言模型吞吐量提升高达32倍,且加速效果随批次大小和共享前缀长度增加而增强。Hydragen还支持超长共享上下文:在高批次设置下,当前缀长度从1K令牌增至16K令牌时,Hydragen吞吐量降幅不足15%,而基线方法吞吐量下降超过90%。Hydragen可泛化至更复杂的树形提示共享模式,这使我们在编程竞赛问题上进一步减少了55%的推理时间。