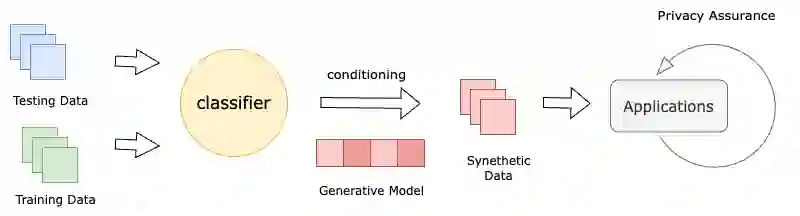
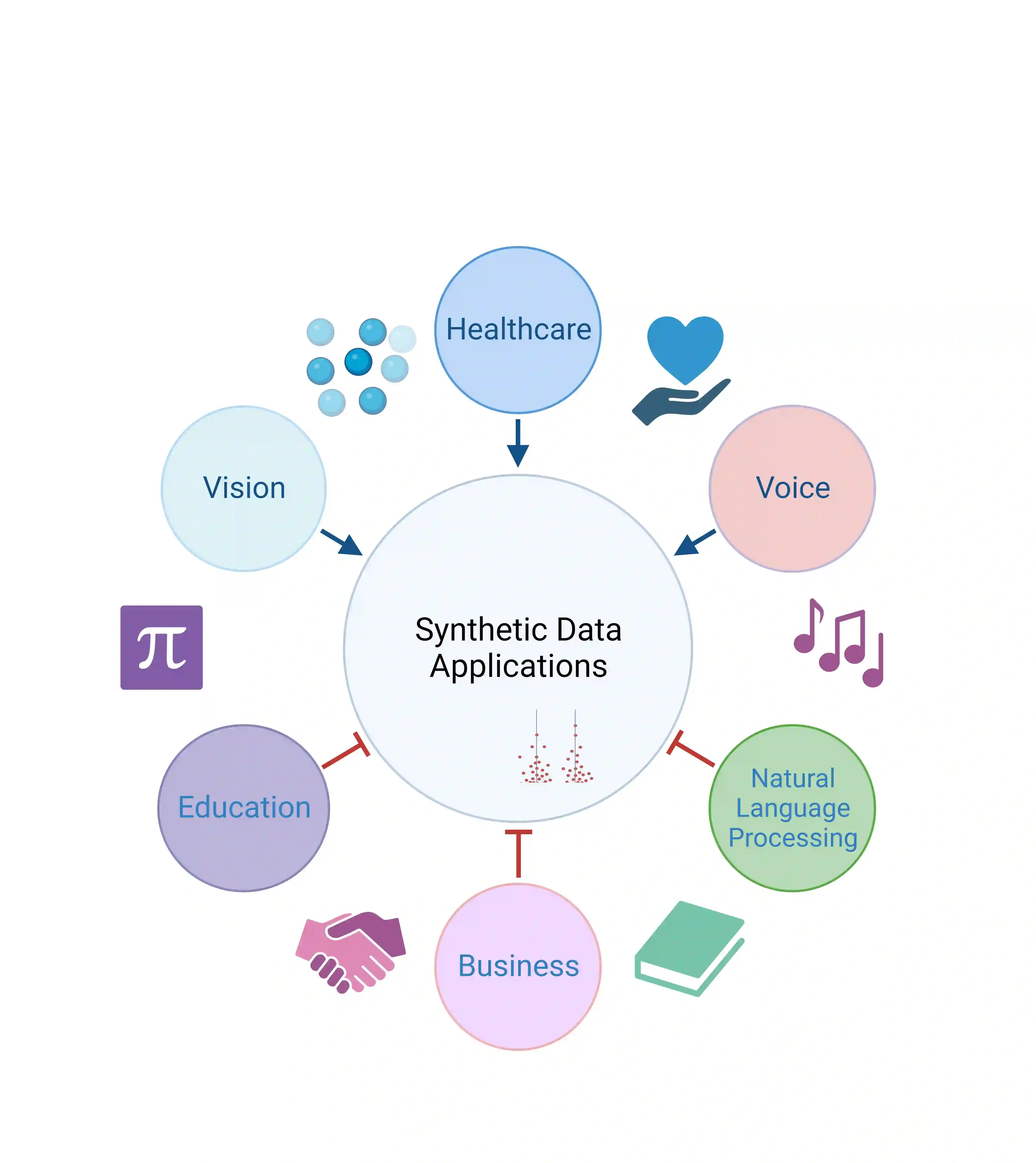
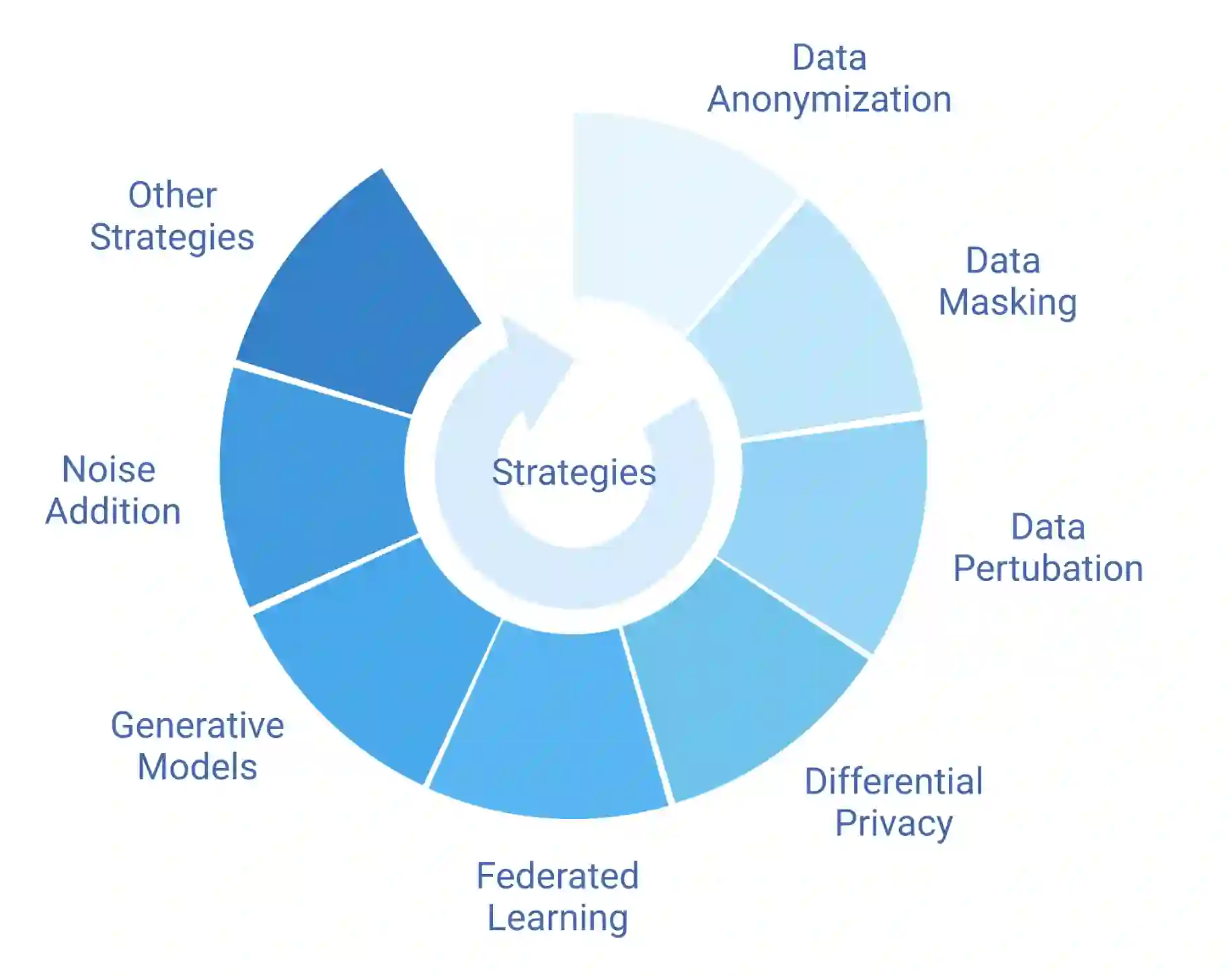
Machine learning heavily relies on data, but real-world applications often encounter various data-related issues. These include data of poor quality, insufficient data points leading to under-fitting of machine learning models, and difficulties in data access due to concerns surrounding privacy, safety, and regulations. In light of these challenges, the concept of synthetic data generation emerges as a promising alternative that allows for data sharing and utilization in ways that real-world data cannot facilitate. This paper presents a comprehensive systematic review of existing studies that employ machine learning models for the purpose of generating synthetic data. The review encompasses various perspectives, starting with the applications of synthetic data generation, spanning computer vision, speech, natural language processing, healthcare, and business domains. Additionally, it explores different machine learning methods, with particular emphasis on neural network architectures and deep generative models. The paper also addresses the crucial aspects of privacy and fairness concerns related to synthetic data generation. Furthermore, this study identifies the challenges and opportunities prevalent in this emerging field, shedding light on the potential avenues for future research. By delving into the intricacies of synthetic data generation, this paper aims to contribute to the advancement of knowledge and inspire further exploration in synthetic data generation.
翻译:机器学习严重依赖数据,但实际应用常面临多种数据相关问题。这些问题包括数据质量低下、数据点不足导致机器学习模型欠拟合,以及因隐私、安全和法规问题造成的数据获取困难。鉴于这些挑战,合成数据生成的概念应运而生,成为一种可行的替代方案,能够以真实数据无法实现的方式实现数据共享与利用。本文对现有利用机器学习模型生成合成数据的研究进行了全面的系统综述。该综述涵盖多个视角,首先探讨合成数据生成的应用领域,包括计算机视觉、语音、自然语言处理、医疗健康和商业领域。同时,本文考察了不同的机器学习方法,特别关注神经网络架构和深度生成模型。论文还阐述了与合成数据生成相关的隐私和公平性关键问题。此外,本研究识别了该新兴领域中存在的挑战与机遇,揭示了未来研究的潜在方向。通过深入剖析合成数据生成的复杂性,本文旨在促进该领域的知识进展,并激发对合成数据生成的进一步探索。