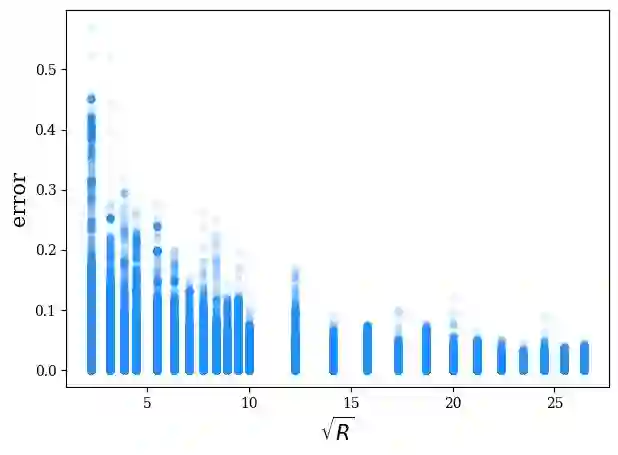
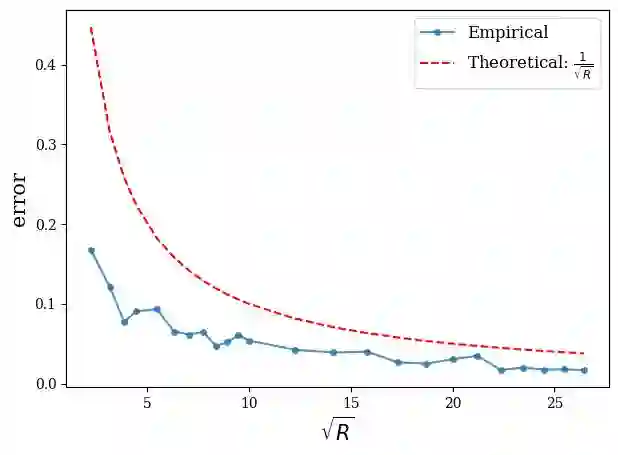
Data sampling is an effective method to improve the training speed of neural networks, with recent results demonstrating that it can even break the neural scaling laws. These results critically rely on high-quality scores to estimate the importance of an input to the network. We observe that there are two dominant strategies: static sampling, where the scores are determined before training, and dynamic sampling, where the scores can depend on the model weights. Static algorithms are computationally inexpensive but less effective than their dynamic counterparts, which can cause end-to-end slowdown due to their need to explicitly compute losses. To address this problem, we propose a novel sampling distribution based on nonparametric kernel regression that learns an effective importance score as the neural network trains. However, nonparametric regression models are too computationally expensive to accelerate end-to-end training. Therefore, we develop an efficient sketch-based approximation to the Nadaraya-Watson estimator. Using recent techniques from high-dimensional statistics and randomized algorithms, we prove that our Nadaraya-Watson sketch approximates the estimator with exponential convergence guarantees. Our sampling algorithm outperforms the baseline in terms of wall-clock time and accuracy on four datasets.
翻译:数据采样是提升神经网络训练速度的有效方法,近期研究表明其甚至能打破神经缩放定律。这些成果的关键在于依赖高质量评分来评估输入对网络的重要性。我们观察到存在两种主导策略:静态采样(训练前确定评分)和动态采样(评分可依赖于模型权重)。静态算法计算成本低但效果逊于动态算法,而动态算法因需显式计算损失可能导致端到端速度下降。为解决此问题,我们提出一种基于非参数核回归的新型采样分布,能随着神经网络训练过程学习有效的重要性评分。然而非参数回归模型计算成本过高,难以加速端到端训练。为此,我们开发了基于高效草图方法的Nadaraya-Watson估计量近似,利用高维统计与随机算法领域的最新成果,证明我们的Nadaraya-Watson草图能以指数级收敛保证逼近该估计量。在四个数据集上的实验表明,我们的采样算法在时钟时间和准确率指标上均优于基线方法。