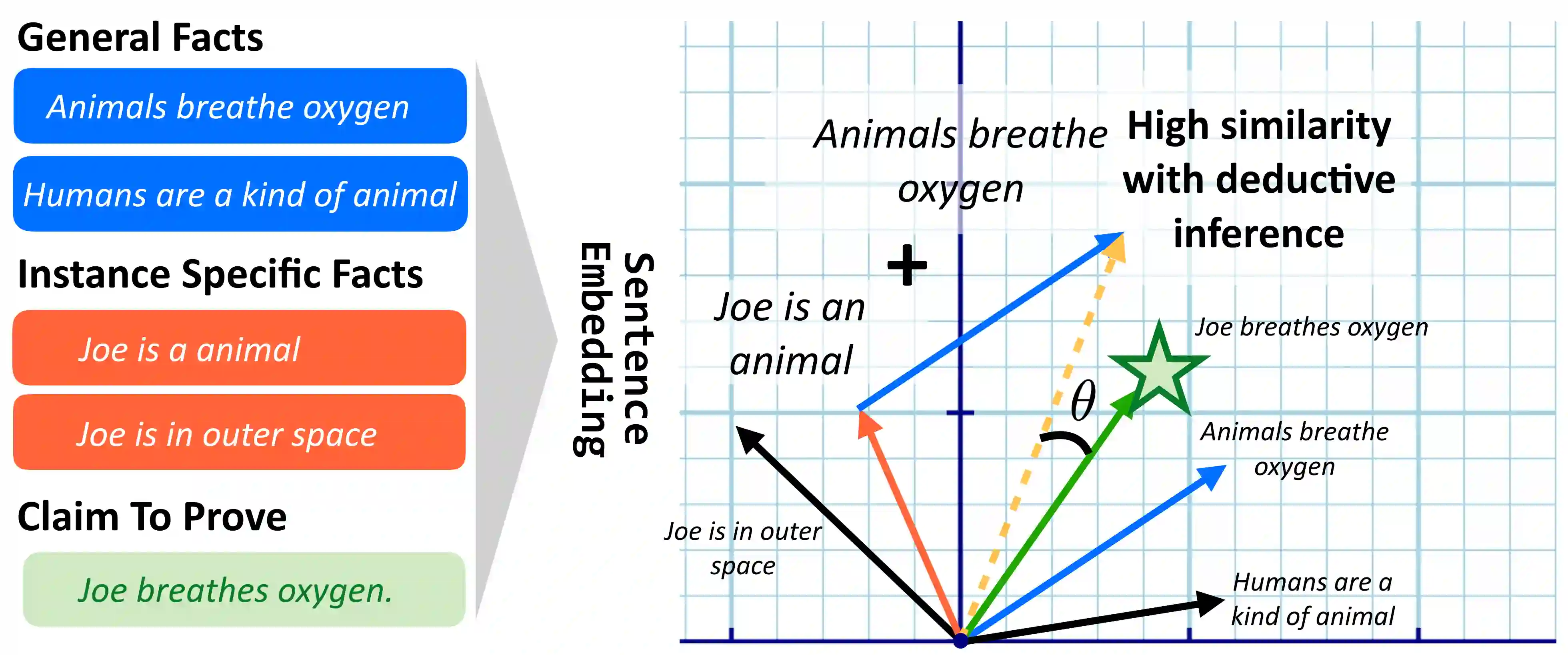
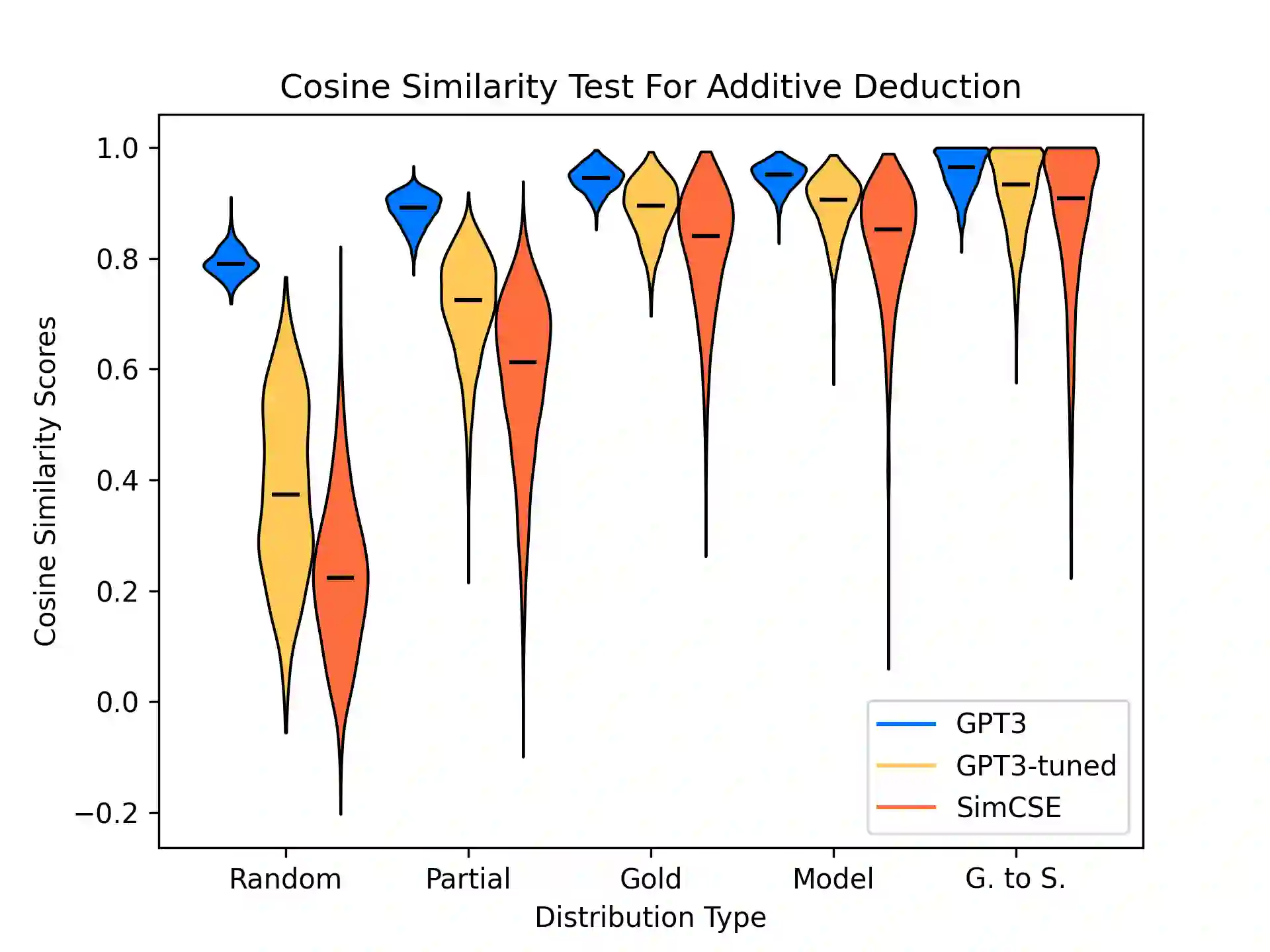
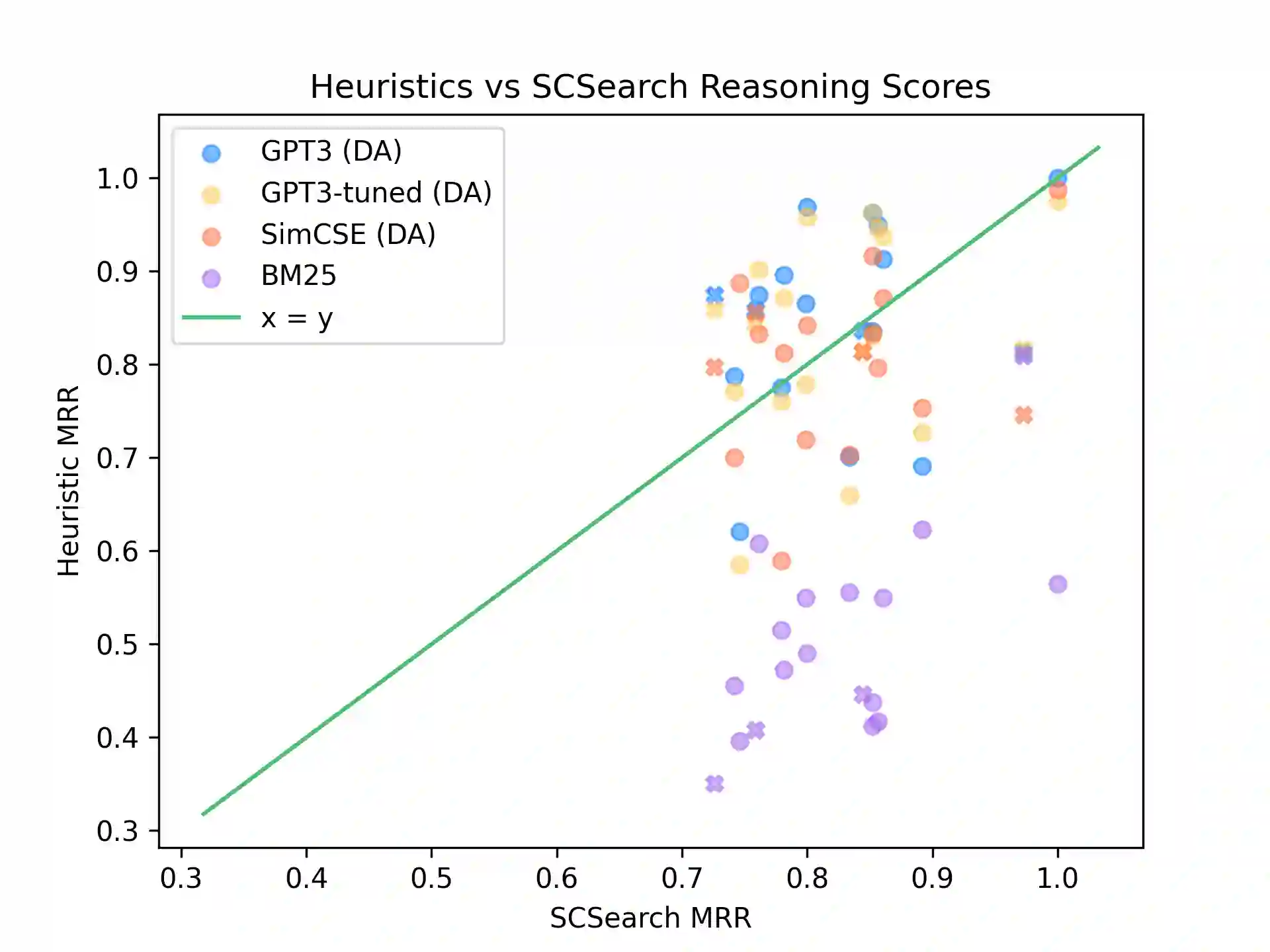
Current natural language systems designed for multi-step claim validation typically operate in two phases: retrieve a set of relevant premise statements using heuristics (planning), then generate novel conclusions from those statements using a large language model (deduction). The planning step often requires expensive Transformer operations and does not scale to arbitrary numbers of premise statements. In this paper, we investigate whether an efficient planning heuristic is possible via embedding spaces compatible with deductive reasoning. Specifically, we evaluate whether embedding spaces exhibit a property we call deductive additivity: the sum of premise statement embeddings should be close to embeddings of conclusions based on those premises. We explore multiple sources of off-the-shelf dense embeddings in addition to fine-tuned embeddings from GPT3 and sparse embeddings from BM25. We study embedding models both intrinsically, evaluating whether the property of deductive additivity holds, and extrinsically, using them to assist planning in natural language proof generation. Lastly, we create a dataset, Single-Step Reasoning Contrast (SSRC), to further probe performance on various reasoning types. Our findings suggest that while standard embedding methods frequently embed conclusions near the sums of their premises, they fall short of being effective heuristics and lack the ability to model certain categories of reasoning.
翻译:当前用于多步声明验证的自然语言系统通常分两阶段运行:首先利用启发式方法检索一组相关前提陈述(规划),然后使用大型语言模型从这些陈述中生成新结论(演绎)。规划步骤通常需要昂贵的Transformer操作,且难以扩展至任意数量的前提陈述。本文探究是否可能通过兼容演绎推理的嵌入空间实现高效的规划启发式方法。具体而言,我们评估嵌入空间是否具备一种我们称之为演绎可加性的性质:前提陈述嵌入的向量和应接近基于这些前提推导出的结论的嵌入。我们探索了多种现成密集嵌入来源,包括GPT3微调嵌入与BM25稀疏嵌入。我们对嵌入模型进行内在评估(检验演绎可加性是否成立)与外在评估(将其用于辅助自然语言证明生成中的规划)。最后,我们创建了单步推理对比数据集(SSRC)以进一步探测各类推理任务上的性能。研究结果表明:尽管标准嵌入方法常使结论嵌入接近其前提的嵌入和,但它们仍不足以成为有效的启发式方法,且缺乏对某些推理类别的建模能力。