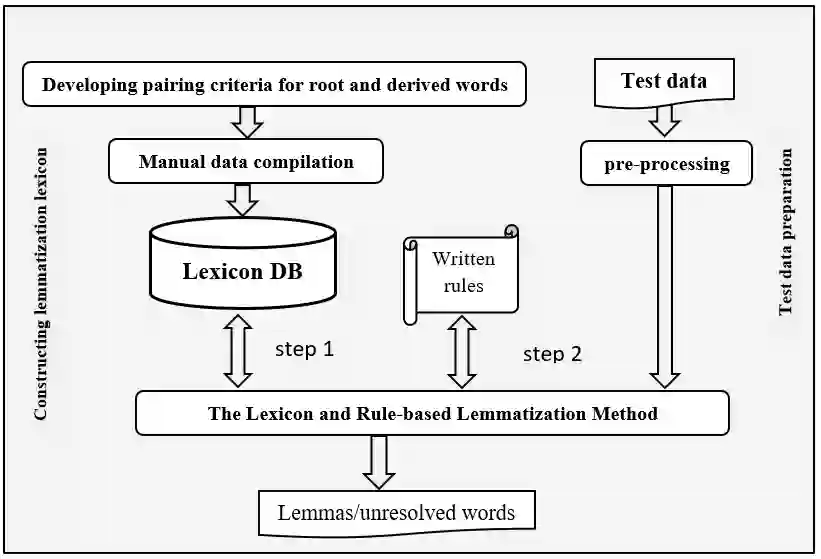
Lemmatization is a Natural Language Processing (NLP) technique used to normalize text by changing morphological derivations of words to their root forms. It is used as a core pre-processing step in many NLP tasks including text indexing, information retrieval, and machine learning for NLP, among others. This paper pioneers the development of text lemmatization for the Somali language, a low-resource language with very limited or no prior effective adoption of NLP methods and datasets. We especially develop a lexicon and rule-based lemmatizer for Somali text, which is a starting point for a full-fledged Somali lemmatization system for various NLP tasks. With consideration of the language morphological rules, we have developed an initial lexicon of 1247 root words and 7173 derivationally related terms enriched with rules for lemmatizing words not present in the lexicon. We have tested the algorithm on 120 documents of various lengths including news articles, social media posts, and text messages. Our initial results demonstrate that the algorithm achieves an accuracy of 57\% for relatively long documents (e.g. full news articles), 60.57\% for news article extracts, and high accuracy of 95.87\% for short texts such as social media messages.
翻译:词形还原是一种用于文本规范化的自然语言处理技术,通过将词的形态派生形式转换为其词根形式。该技术作为核心预处理步骤,广泛应用于文本索引、信息检索、面向自然语言处理的机器学习等任务中。本文首次探索了索马里语的文本词形还原方法——索马里语属于低资源语言,此前几乎没有或仅有极少数有效的自然语言处理方法与数据集的应用。我们特别针对索马里语文本,开发了一种基于词库和规则的词形还原器,这为构建适用于多种自然语言处理任务的完整索马里语词形还原系统奠定了基础。结合该语言的形态学规则,我们构建了初始词库,包含1247个词根词及7173个派生关联词,并辅以针对未收录词进行词形还原的规则。我们在120篇不同长度的文档上测试了该算法,包括新闻文章、社交媒体帖子和短信文本。初步结果表明,算法在较长文档(如完整新闻文章)中准确率为57%,在新闻文章摘录中为60.57%,而在短文本(如社交媒体消息)中准确率高达95.87%。