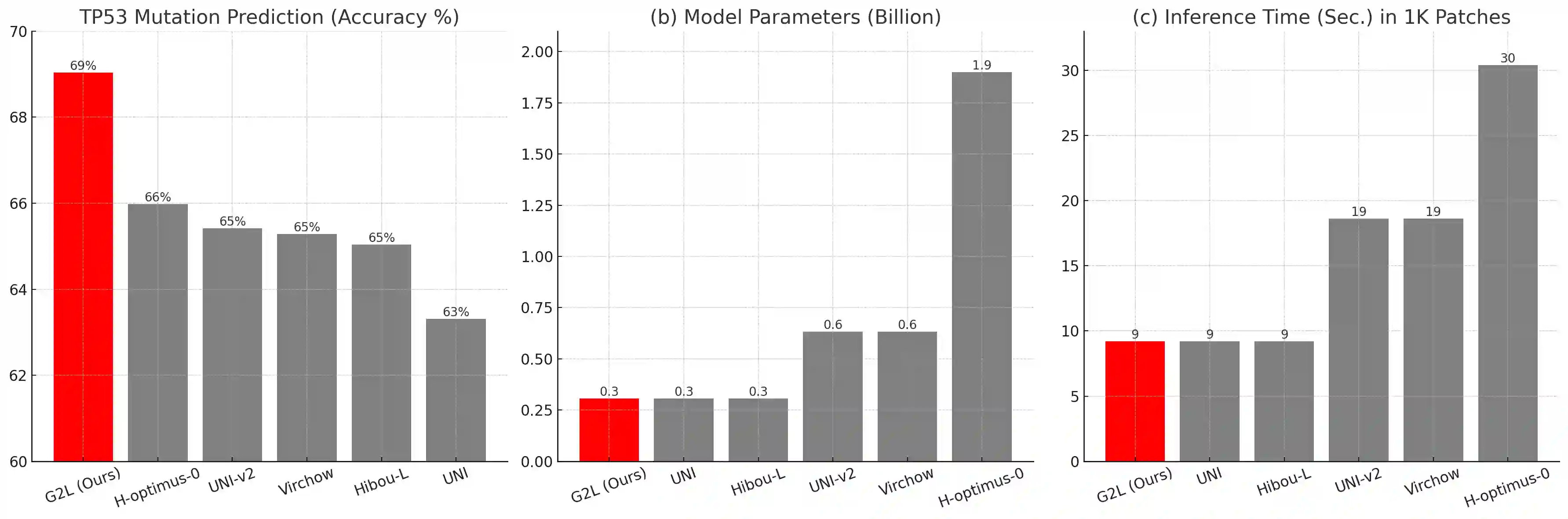
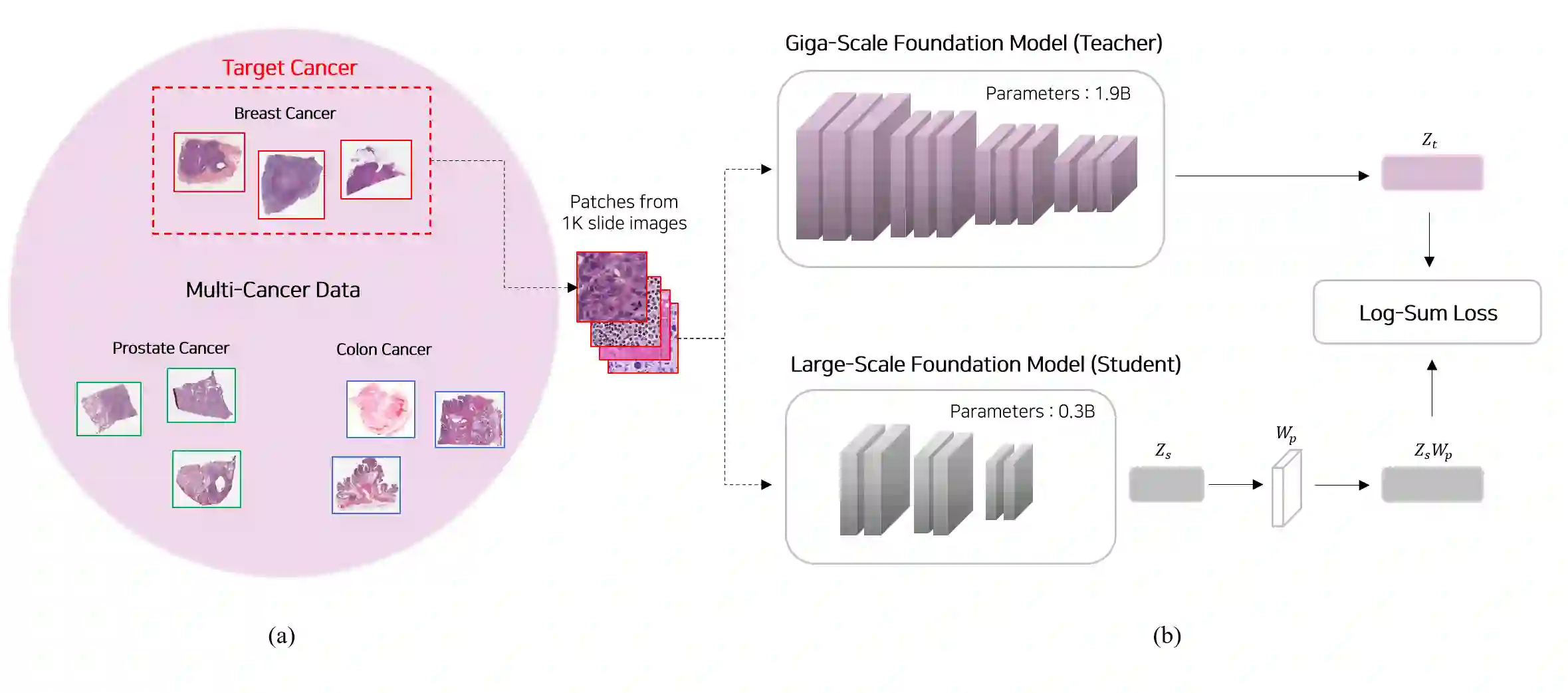
Recent studies in pathology foundation models have shown that scaling training data, diversifying cancer types, and increasing model size consistently improve their performance. However, giga-scale foundation models, which are trained on hundreds of thousands of slides covering tens of cancer types and contain billions of parameters, pose significant challenges for practical use due to their tremendous computational costs in both development and deployment. In this work, we present a novel strategy, named the G2L framework, to increase the performance of large-scale foundation models, which consist of only $15\%$ of the parameters of giga-scale models, to a comparable performance level of giga-scale models in cancer-specific tasks. Our approach applies knowledge distillation, transferring the capabilities of a giga-scale model to a large-scale model, using just 1K pathology slides of a target cancer (e.g., breast, prostate, etc.). The resulting distilled model not only outperformed state-of-the-art models of the same size (i.e., large-scale) across several benchmarks but also, interestingly, surpassed the giga-scale teacher and huge-scale models in some benchmarks. In addition, the distilled model exhibited a higher robustness index, indicating improved resilience to image variations originating from multiple institutions. These findings suggest that the proposed distillation approach for a large-scale model is a data- and parameter-efficient way to achieve giga-scale-level performance for cancer-specific applications without prohibitive computational burden.
翻译:近期病理学基础模型的研究表明,扩大训练数据规模、增加癌症类型多样性以及提升模型参数量均能持续改善模型性能。然而,千亿级基础模型(在覆盖数十种癌症类型的数十万张病理切片上训练,包含数百亿参数)因其在开发与部署阶段产生的巨大计算成本,在实际应用中面临显著挑战。本研究提出一种名为G2L框架的创新策略,旨在将仅包含千亿级模型参数量$15\%$的大规模基础模型,在癌症特异性任务中的性能提升至与千亿级模型相当的水平。该方法通过知识蒸馏技术,仅使用目标癌症(如乳腺癌、前列腺癌等)的1K张病理切片,将千亿级模型的能力迁移至大规模模型。所得蒸馏模型不仅在同规模(即大规模)模型的多个基准测试中超越了现有最优模型,更值得注意的是,在部分基准测试中甚至超越了千亿级教师模型及超大规模模型。此外,该蒸馏模型展现出更高的鲁棒性指数,表明其对来自多机构的图像变异具有更强的适应能力。这些发现证明,所提出的大规模模型蒸馏方法是一种数据与参数高效的技术路径,可在不产生过高计算负担的前提下,为癌症特异性应用实现千亿级模型的性能水平。