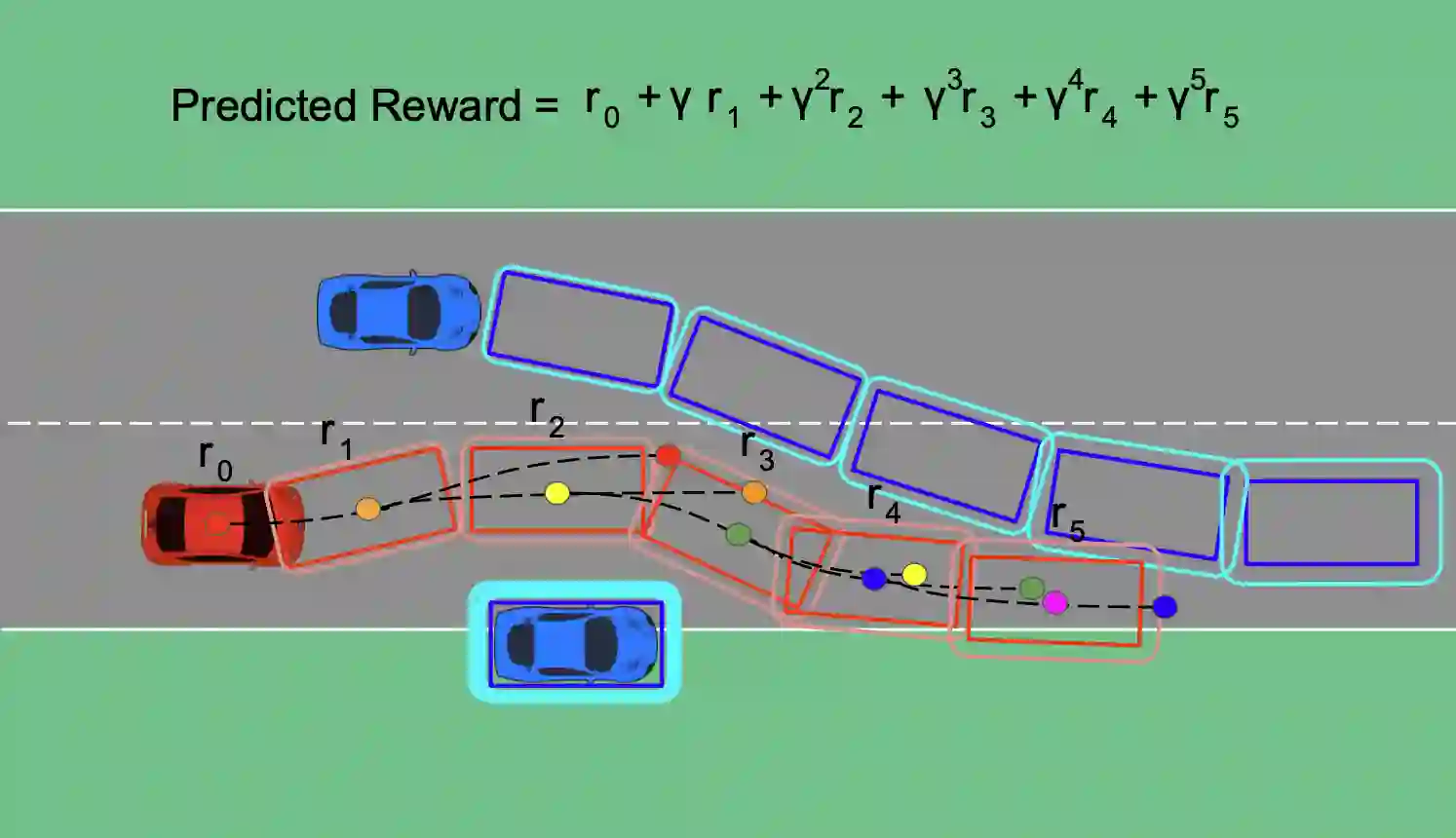
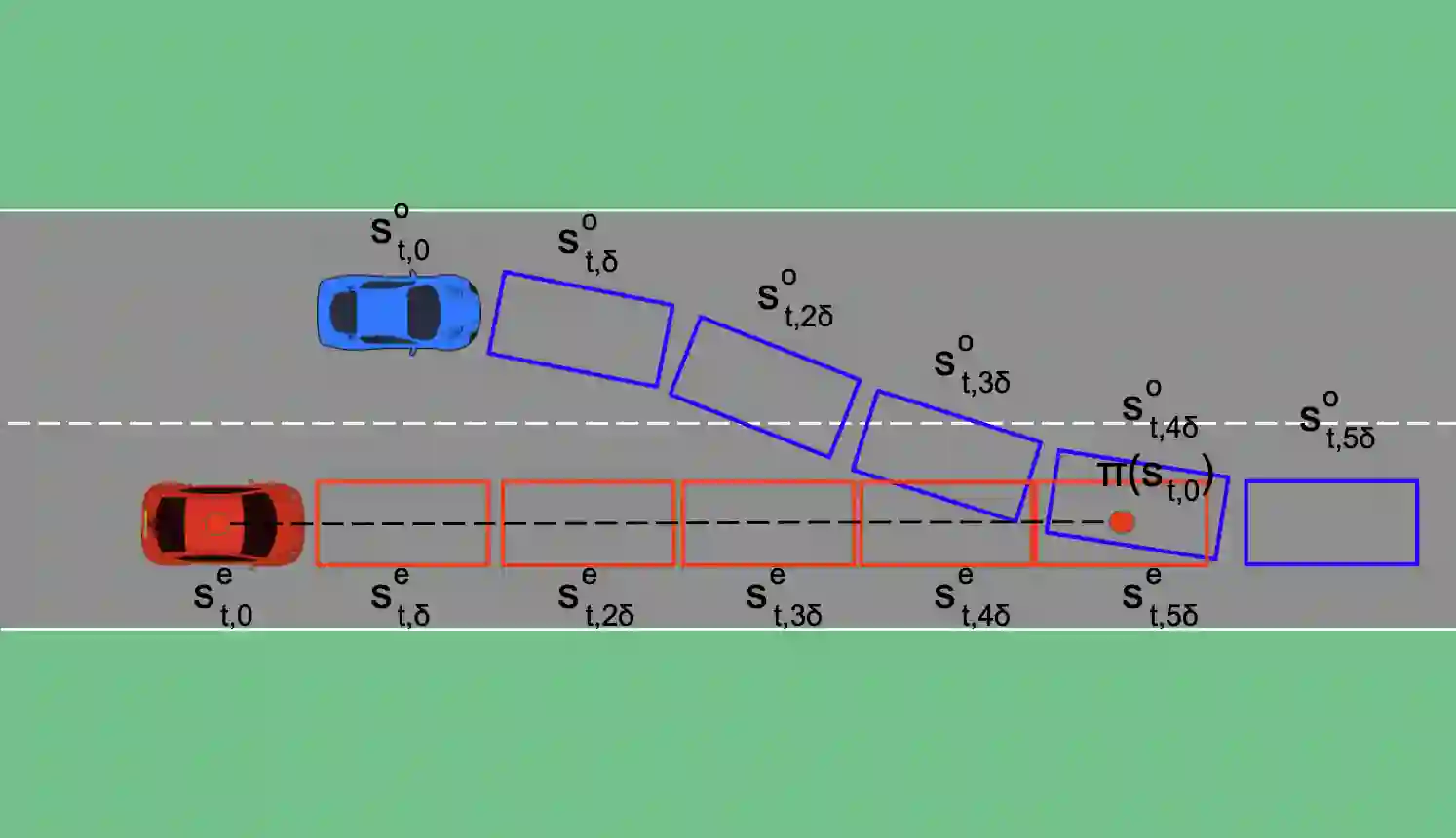
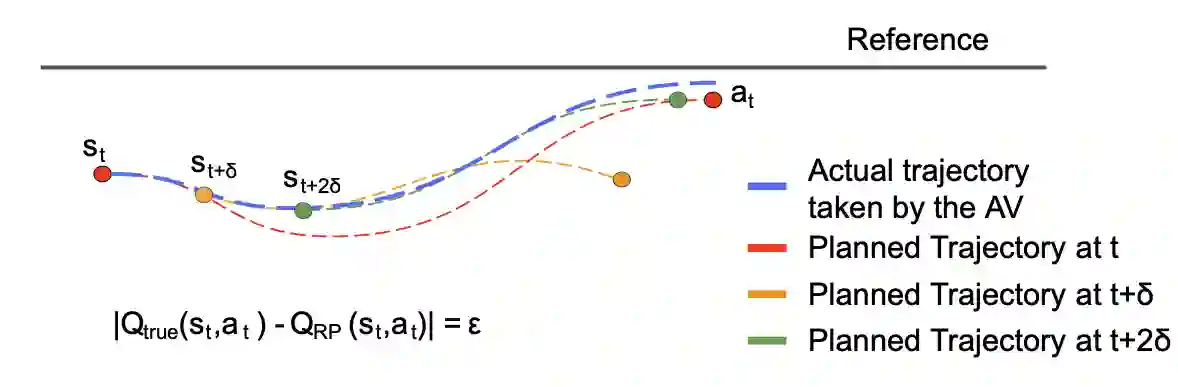
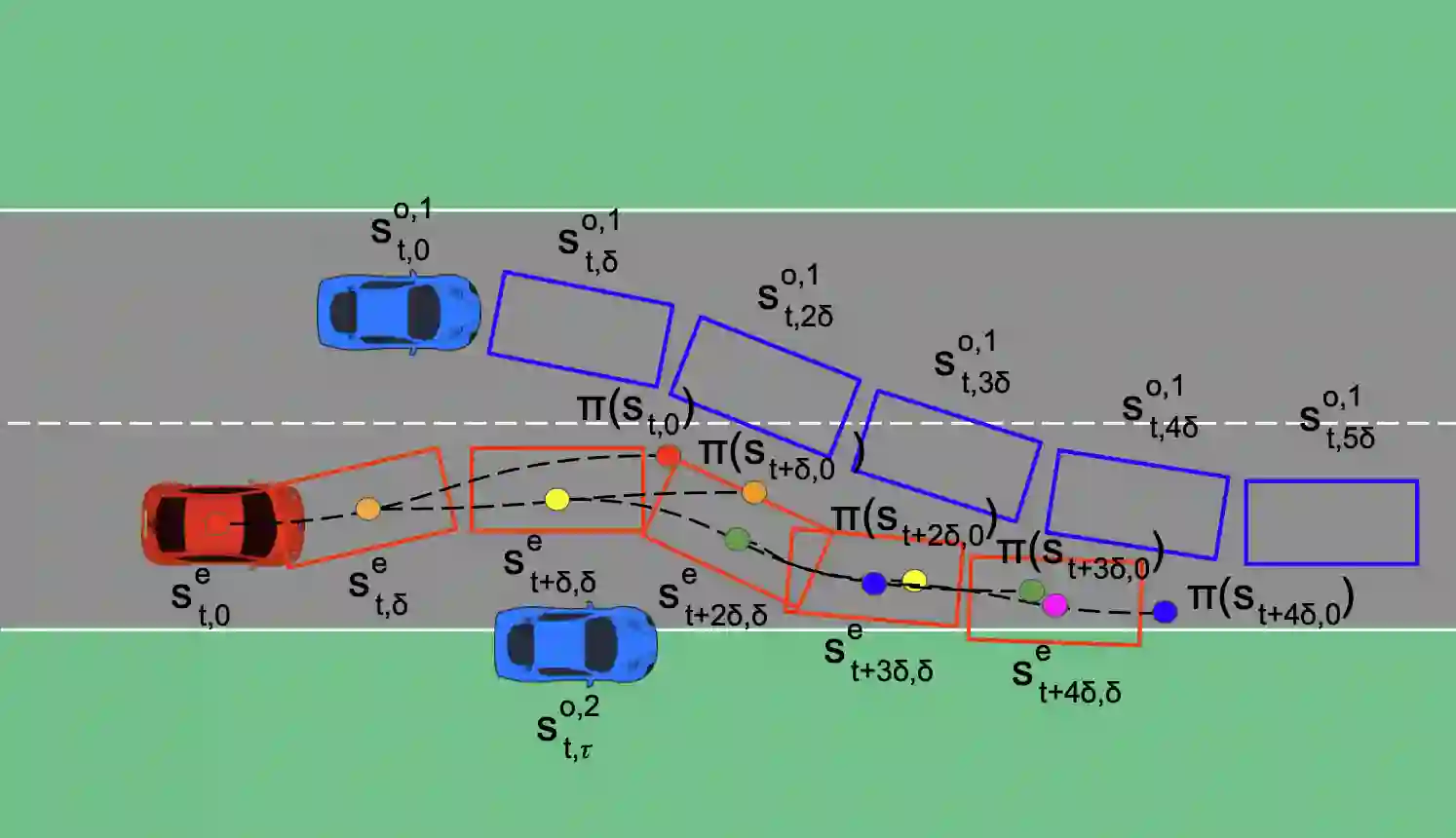
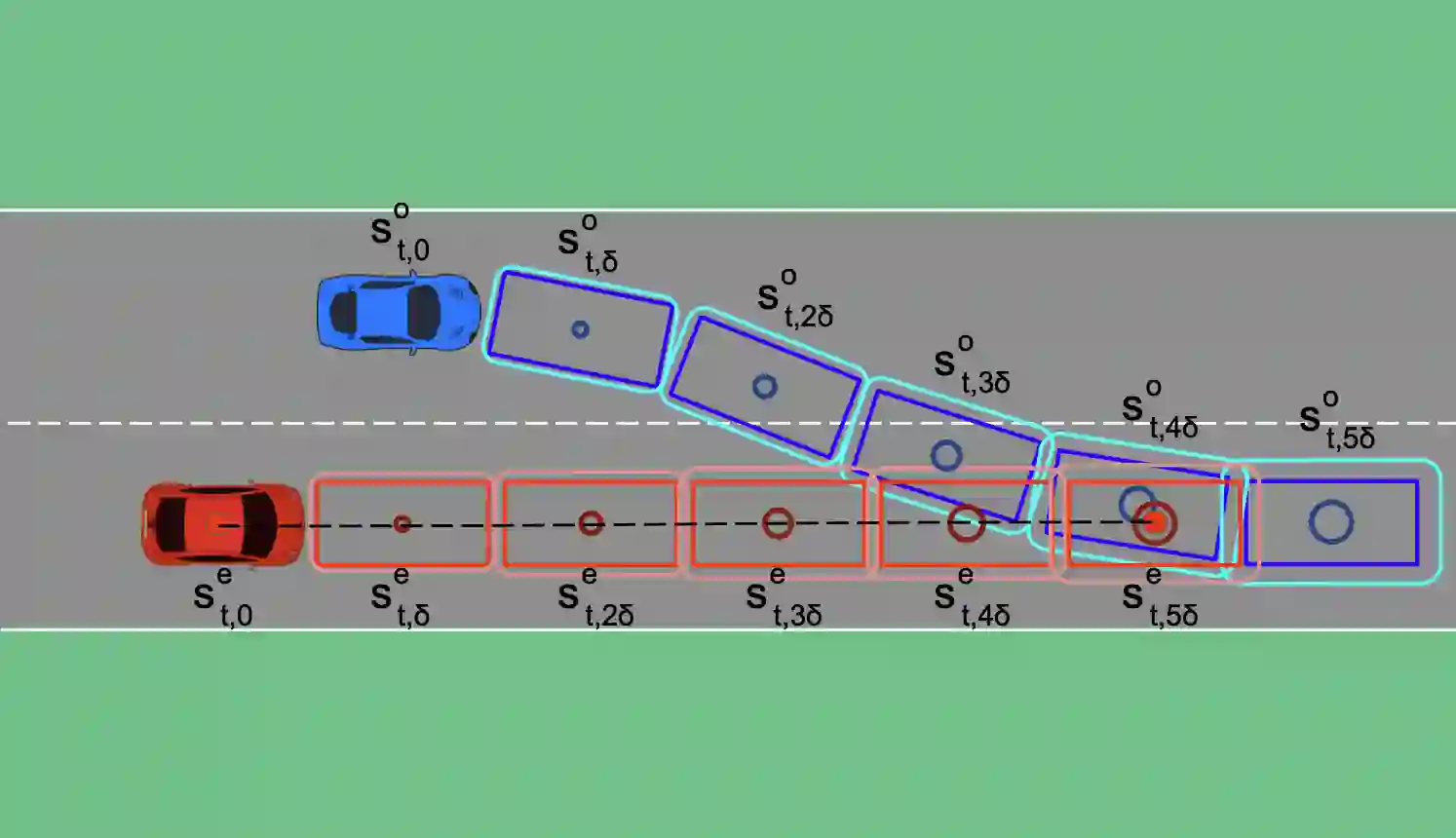
Traditional trajectory planning methods for autonomous vehicles have several limitations. For example, heuristic and explicit simple rules limit generalizability and hinder complex motions. These limitations can be addressed using reinforcement learning-based trajectory planning. However, reinforcement learning suffers from unstable learning and existing reinforcement learning-based trajectory planning methods do not consider the uncertainties. Thus, this paper, proposes a reinforcement learning-based trajectory planning method for autonomous vehicles. The proposed method involves an iterative reward prediction approach that iteratively predicts expectations of future states. These predicted states are then used to forecast rewards and integrated into the learning process to enhance stability. Additionally, a method is proposed that utilizes uncertainty propagation to make the reinforcement learning agent aware of uncertainties.The proposed method was evaluated using the CARLA simulator. Compared to the baseline methods, the proposed method reduced the collision rate by 60.17%, and increased the average reward by 30.82 times. A video of the proposed method is available at https://www.youtube.com/watch?v=PfDbaeLfcN4.
翻译:传统的自动驾驶车辆轨迹规划方法存在若干局限性。例如,基于启发式和显式简单规则的方法限制了泛化能力,并阻碍了复杂运动的实现。这些问题可通过基于强化学习的轨迹规划方法来克服。然而,强化学习存在学习不稳定的问题,且现有基于强化学习的轨迹规划方法未考虑不确定性因素。为此,本文提出一种面向自动驾驶车辆的强化学习轨迹规划方法。该方法采用迭代奖励预测策略,通过迭代预测未来状态的期望值,并利用这些预测状态预估奖励,将其融入学习过程以增强稳定性。此外,还提出一种利用不确定性传播使强化学习智能体感知不确定性的方法。通过CARLA仿真器对所述方法进行评估。与基线方法相比,本方法将碰撞率降低60.17%,平均奖励提升30.82倍。演示视频见https://www.youtube.com/watch?v=PfDbaeLfcN4。