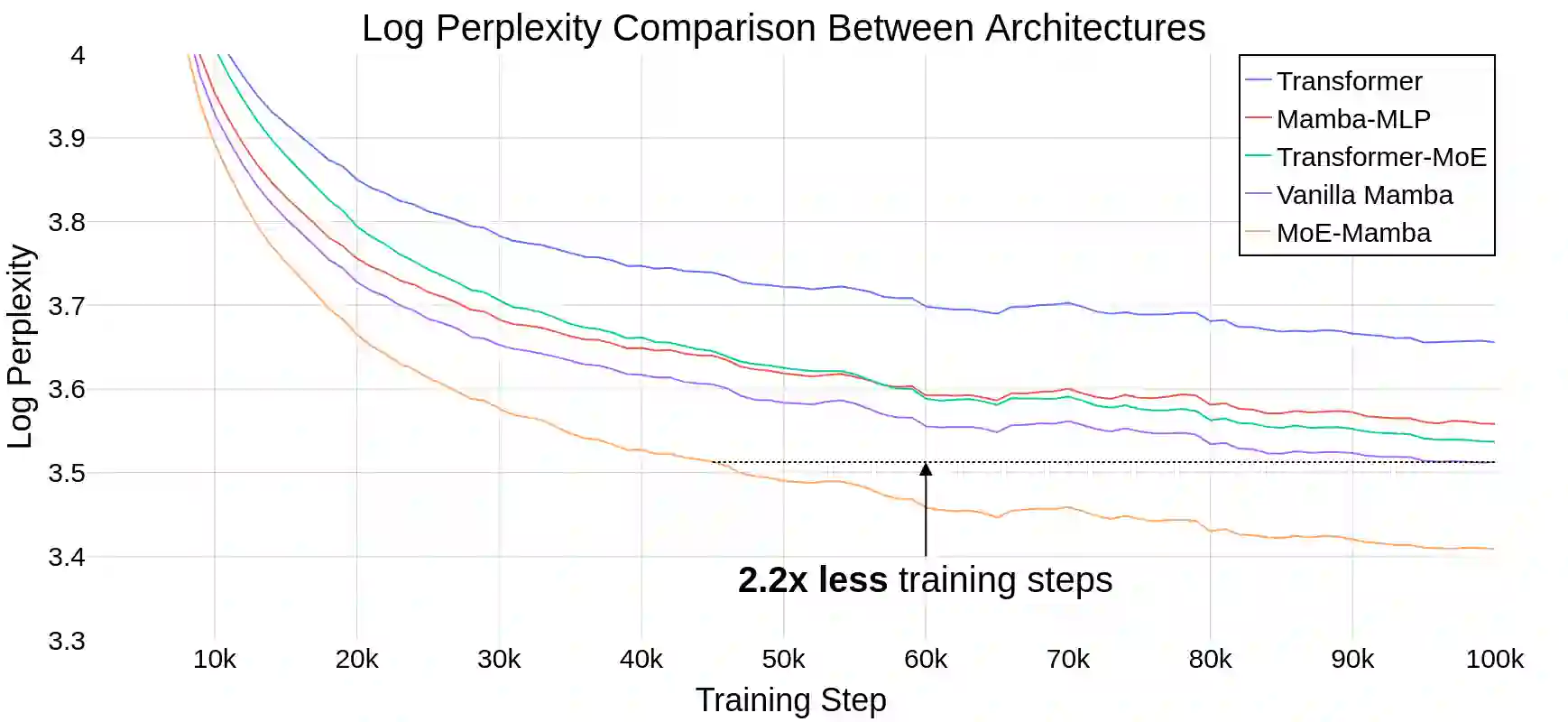
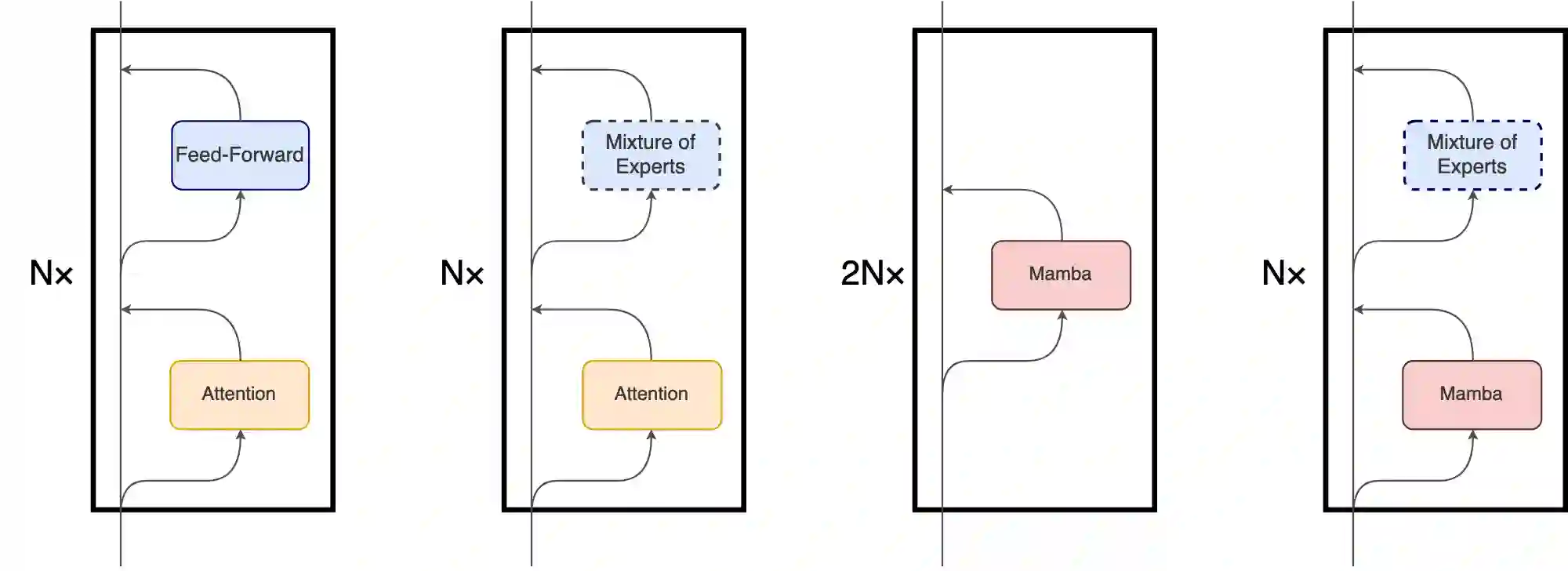
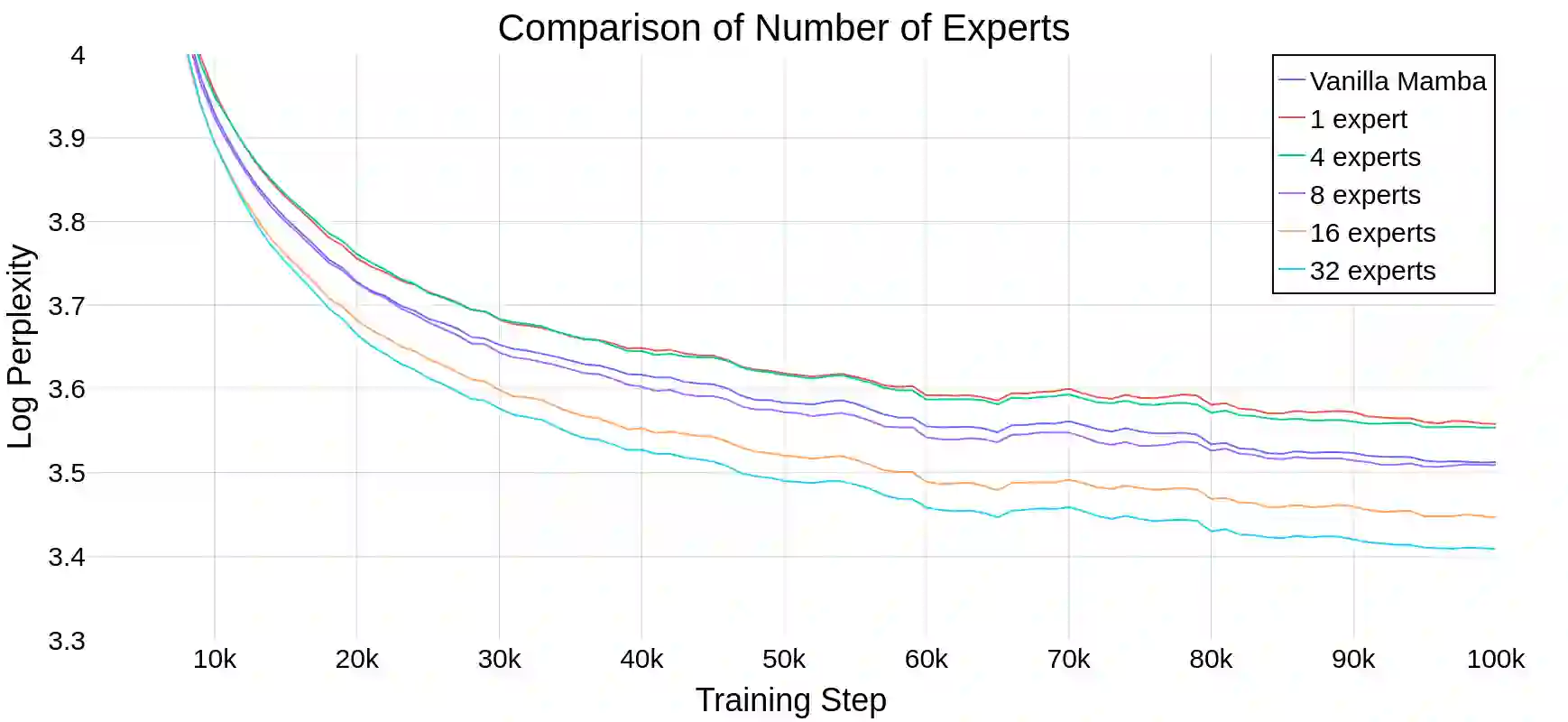
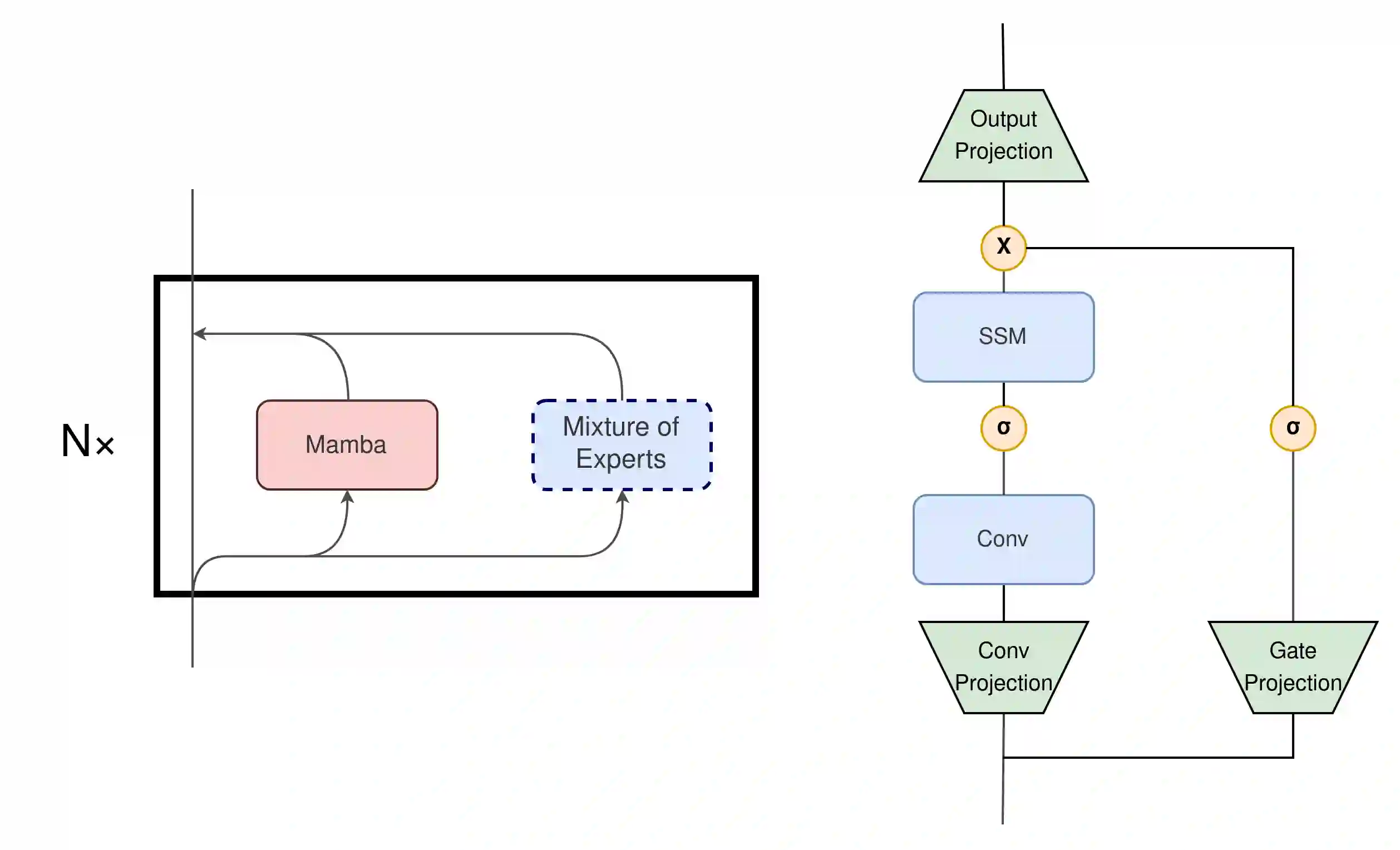
State Space Models (SSMs) have become serious contenders in the field of sequential modeling, challenging the dominance of Transformers. At the same time, Mixture of Experts (MoE) has significantly improved Transformer-based LLMs, including recent state-of-the-art open-source models. We propose that to unlock the potential of SSMs for scaling, they should be combined with MoE. We showcase this on Mamba, a recent SSM-based model that achieves remarkable, Transformer-like performance. Our model, MoE-Mamba, outperforms both Mamba and Transformer-MoE. In particular, MoE-Mamba reaches the same performance as Mamba in 2.2x less training steps while preserving the inference performance gains of Mamba against the Transformer.
翻译:状态空间模型(SSMs)已成为序列建模领域的重要竞争者,挑战着Transformer的主导地位。与此同时,专家混合(MoE)显著改进了基于Transformer的大语言模型,包括最新一代开源模型中的佼佼者。我们提出,为释放SSM在扩展能力上的潜力,应将其与MoE相结合。我们以Mamba(一种近期提出的、性能卓越的类Transformer SSM模型)为例进行验证。我们的模型MoE-Mamba在性能上超越了Mamba与Transformer-MoE。具体而言,MoE-Mamba仅需Mamba 2.2倍的训练步数即可达到同等性能,同时保持了Mamba相较Transformer的推理效率优势。