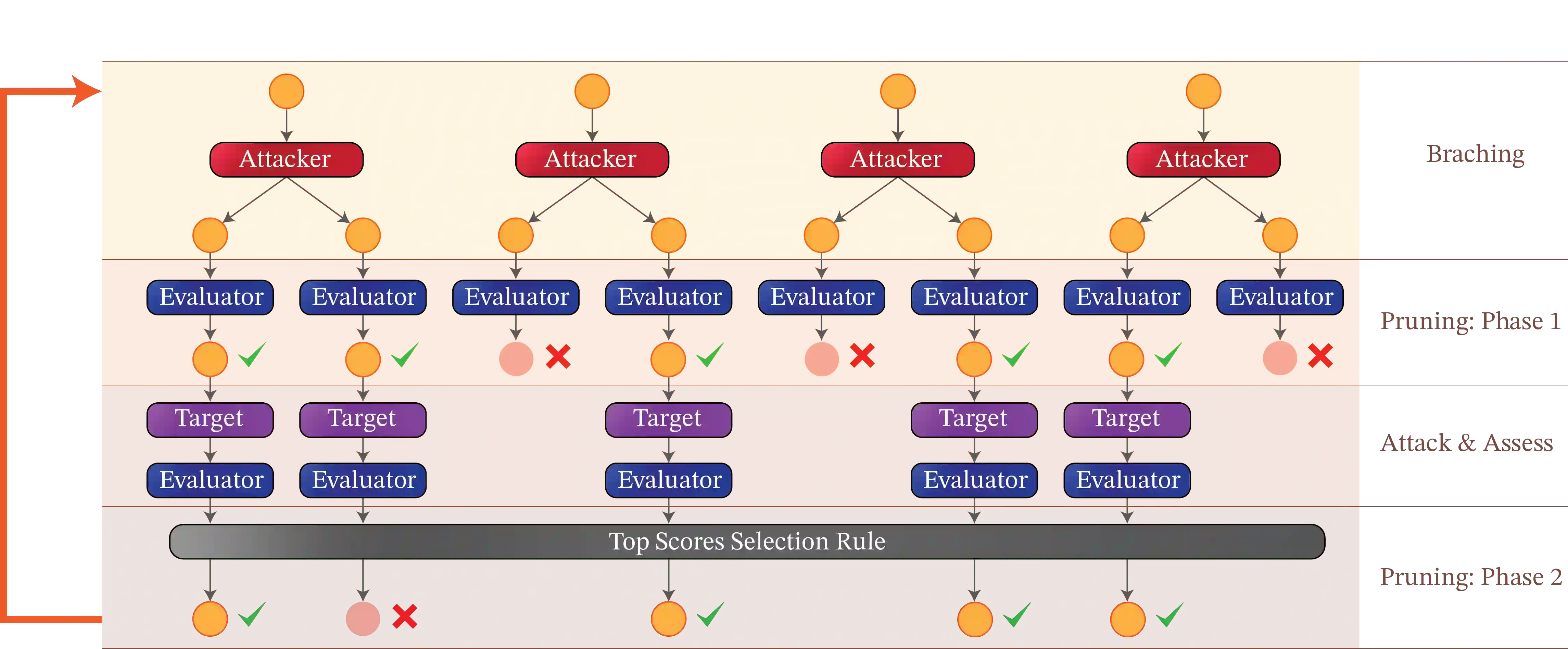
While Large Language Models (LLMs) display versatile functionality, they continue to generate harmful, biased, and toxic content, as demonstrated by the prevalence of human-designed jailbreaks. In this work, we present Tree of Attacks with Pruning (TAP), an automated method for generating jailbreaks that only requires black-box access to the target LLM. TAP utilizes an LLM to iteratively refine candidate (attack) prompts using tree-of-thought reasoning until one of the generated prompts jailbreaks the target. Crucially, before sending prompts to the target, TAP assesses them and prunes the ones unlikely to result in jailbreaks. Using tree-of-thought reasoning allows TAP to navigate a large search space of prompts and pruning reduces the total number of queries sent to the target. In empirical evaluations, we observe that TAP generates prompts that jailbreak state-of-the-art LLMs (including GPT4 and GPT4-Turbo) for more than 80% of the prompts using only a small number of queries. Interestingly, TAP is also capable of jailbreaking LLMs protected by state-of-the-art guardrails, e.g., LlamaGuard. This significantly improves upon the previous state-of-the-art black-box method for generating jailbreaks.
翻译:尽管大语言模型(LLMs)展现出广泛的功能,但人类设计的越狱攻击的普遍存在表明,它们仍会生成有害、有偏见和有毒的内容。本文提出"带剪枝的攻击之树"(TAP)——一种仅需对目标LLM进行黑盒访问即可自动生成越狱攻击的方法。TAP利用LLM通过思维树推理迭代优化候选(攻击)提示,直至生成的某个提示成功越狱目标。关键之处在于,在向目标发送提示前,TAP会评估这些提示并剪除那些不可能导致越狱的提示。利用思维树推理使TAP能够探索广阔的提示搜索空间,而剪枝则减少了发送给目标的总查询次数。实证评估中,我们观察到TAP仅需少量查询即可生成对80%以上的提示成功越狱最先进LLM(包括GPT4和GPT4-Turbo)的提示。有趣的是,TAP还能越狱受最先进防护机制(如LlamaGuard)保护的LLM。这显著超越了此前最先进的黑盒越狱生成方法。