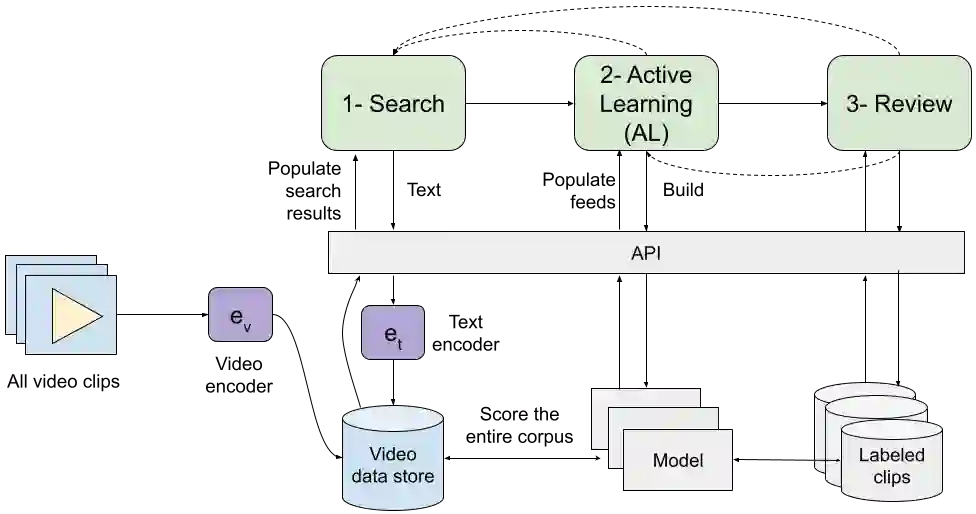
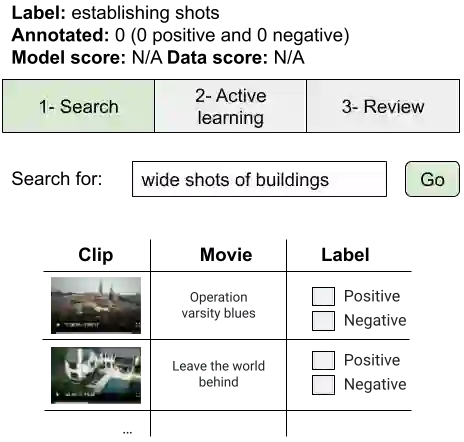
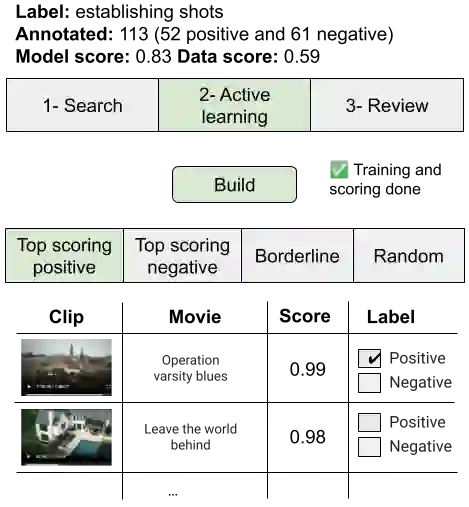
High-quality and consistent annotations are fundamental to the successful development of robust machine learning models. Traditional data annotation methods are resource-intensive and inefficient, often leading to a reliance on third-party annotators who are not the domain experts. Hard samples, which are usually the most informative for model training, tend to be difficult to label accurately and consistently without business context. These can arise unpredictably during the annotation process, requiring a variable number of iterations and rounds of feedback, leading to unforeseen expenses and time commitments to guarantee quality. We posit that more direct involvement of domain experts, using a human-in-the-loop system, can resolve many of these practical challenges. We propose a novel framework we call Video Annotator (VA) for annotating, managing, and iterating on video classification datasets. Our approach offers a new paradigm for an end-user-centered model development process, enhancing the efficiency, usability, and effectiveness of video classifiers. Uniquely, VA allows for a continuous annotation process, seamlessly integrating data collection and model training. We leverage the zero-shot capabilities of vision-language foundation models combined with active learning techniques, and demonstrate that VA enables the efficient creation of high-quality models. VA achieves a median 6.8 point improvement in Average Precision relative to the most competitive baseline across a wide-ranging assortment of tasks. We release a dataset with 153k labels across 56 video understanding tasks annotated by three professional video editors using VA, and also release code to replicate our experiments at: http://github.com/netflix/videoannotator.
翻译:高质量且一致的标注是开发稳健机器学习模型的基础。传统数据标注方法资源密集且效率低下,往往依赖缺乏领域专业知识的第三方标注者。对模型训练最具信息量的困难样本,若无业务背景通常难以准确一致地标注——这类样本可能在标注过程中不可预测地出现,需要可变次数的迭代与反馈轮次,导致确保质量所需的时间和费用难以预估。我们认为,采用人在回路系统让领域专家更直接参与,可解决诸多实际挑战。本文提出名为"Video Annotator (VA)"的新框架,用于视频分类数据集的标注、管理与迭代优化。该方法开创了以终端用户为中心的模型开发新范式,显著提升视频分类器的效率、可用性与有效性。独特之处在于,VA支持持续标注流程,无缝整合数据采集与模型训练。我们利用视觉-语言基础模型的零样本能力结合主动学习技术,证明VA能高效创建高质量模型。在广泛多样的任务集上,VA相较最具竞争力的基线方法,平均精度中位数提升6.8个百分点。我们发布了一个包含56项视频理解任务、由三位专业视频编辑使用VA标注的15.3万标签数据集,并公开实验复现代码:http://github.com/netflix/videoannotator。