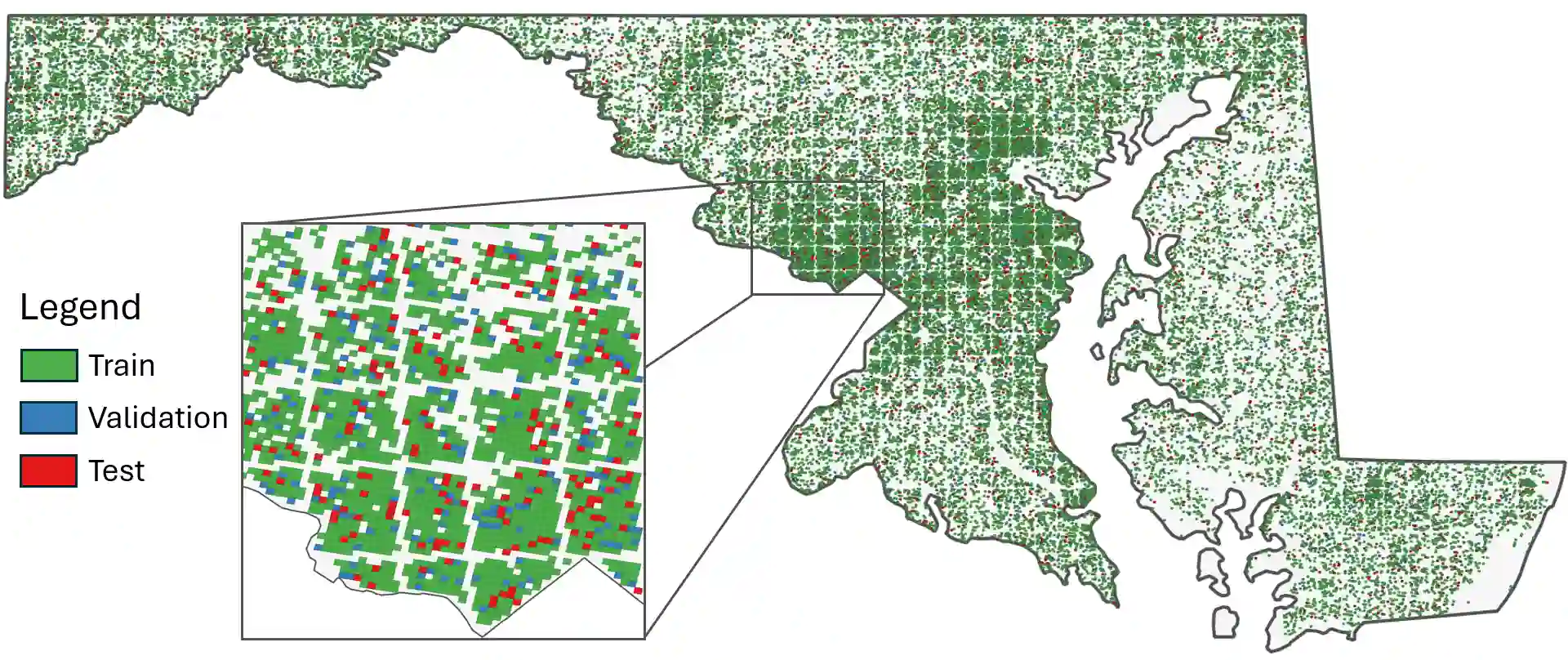
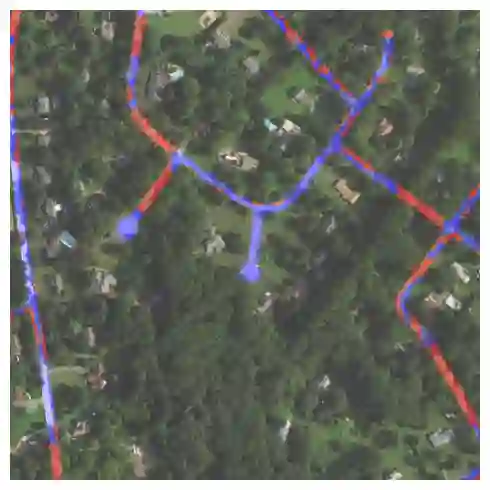
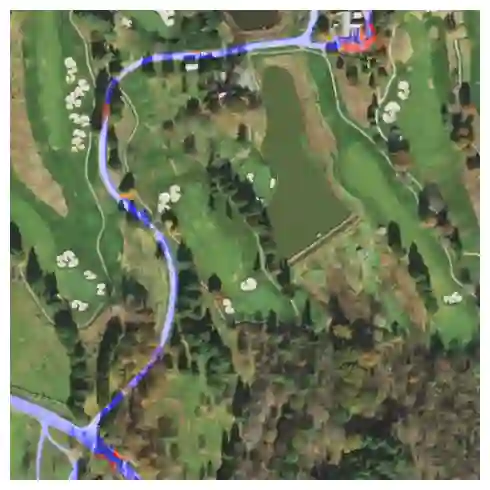
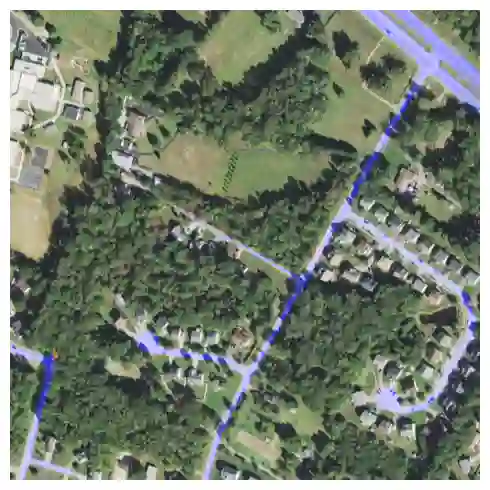
Fully understanding a complex high-resolution satellite or aerial imagery scene often requires spatial reasoning over a broad relevant context. The human object recognition system is able to understand object in a scene over a long-range relevant context. For example, if a human observes an aerial scene that shows sections of road broken up by tree canopy, then they will be unlikely to conclude that the road has actually been broken up into disjoint pieces by trees and instead think that the canopy of nearby trees is occluding the road. However, there is limited research being conducted to understand long-range context understanding of modern machine learning models. In this work we propose a road segmentation benchmark dataset, Chesapeake Roads Spatial Context (RSC), for evaluating the spatial long-range context understanding of geospatial machine learning models and show how commonly used semantic segmentation models can fail at this task. For example, we show that a U-Net trained to segment roads from background in aerial imagery achieves an 84% recall on unoccluded roads, but just 63.5% recall on roads covered by tree canopy despite being trained to model both the same way. We further analyze how the performance of models changes as the relevant context for a decision (unoccluded roads in our case) varies in distance. We release the code to reproduce our experiments and dataset of imagery and masks to encourage future research in this direction -- https://github.com/isaaccorley/ChesapeakeRSC.
翻译:全面理解复杂的高分辨率卫星或航拍影像场景,通常需要在大范围相关上下文中进行空间推理。人类目标识别系统能够在长距离相关上下文中理解场景中的物体。例如,当人类观察到一幅被树冠分割成若干路段的航拍场景时,他们不会得出道路实际上已被树木割裂成不连续碎片的结论,而会认为附近的树冠遮挡了道路。然而,目前关于现代机器学习模型对长距离上下文理解能力的研究十分有限。本文提出一个道路分割基准数据集——切萨皮克道路空间上下文(RSC),用于评估地理空间机器学习模型的长距离空间上下文理解能力,并揭示常用语义分割模型在此任务中可能失效的情况。例如,我们证明,在航拍图像中训练用于道路分割的U-Net模型,对未遮挡道路的召回率达84%,而对树冠覆盖道路的召回率仅为63.5%,尽管两者采用相同的训练方式。我们进一步分析了当决策相关上下文(本例中为未遮挡道路)的距离变化时模型性能的演变规律。为促进该方向的后续研究,我们公开了实验复现代码及影像与掩膜数据集:https://github.com/isaaccorley/ChesapeakeRSC。