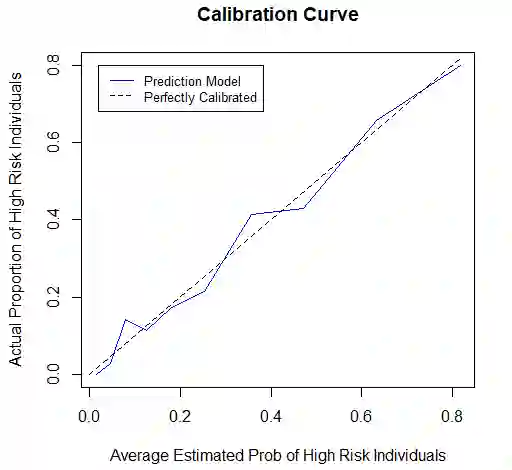
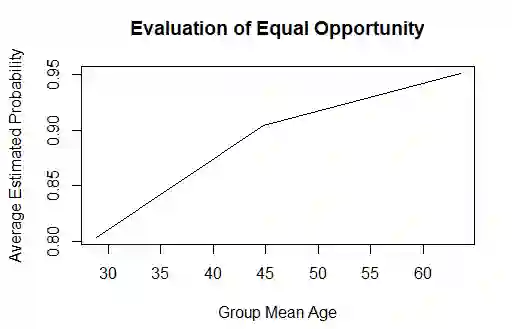
This paper proposes the use of causal modeling to detect and mitigate algorithmic bias that is nonlinear in the protected attribute. We provide a general overview of our approach. We use the German Credit data set, which is available for download from the UC Irvine Machine Learning Repository, to develop (1) a prediction model, which is treated as a black box, and (2) a causal model for bias mitigation. In this paper, we focus on age bias and the problem of binary classification. We show that the probability of getting correctly classified as "low risk" is lowest among young people. The probability increases with age nonlinearly. To incorporate the nonlinearity into the causal model, we introduce a higher order polynomial term. Based on the fitted causal model, the de-biased probability estimates are computed, showing improved fairness with little impact on overall classification accuracy. Causal modeling is intuitive and, hence, its use can enhance explicability and promotes trust among different stakeholders of AI.
翻译:本文提出利用因果建模来检测和缓解受保护属性中呈现非线性的算法偏差。我们概述了该方法的一般框架。采用可从加州大学欧文分校机器学习存储库下载的德国信用数据集,我们构建了(1)一个作为黑箱处理的预测模型,以及(2)一个用于缓解偏差的因果模型。本研究聚焦于年龄偏差与二元分类问题。研究表明,年轻人被正确归类为"低风险"的概率最低,该概率随年龄增长呈非线性增加。为将非线性特征纳入因果模型,我们引入高阶多项式项。基于拟合后的因果模型计算去偏概率估计值,结果显示在保持分类整体准确率基本不变的前提下,公平性得到显著提升。因果建模兼具直观性,因此其应用能够增强可解释性并促进人工智能各利益相关方之间的信任。