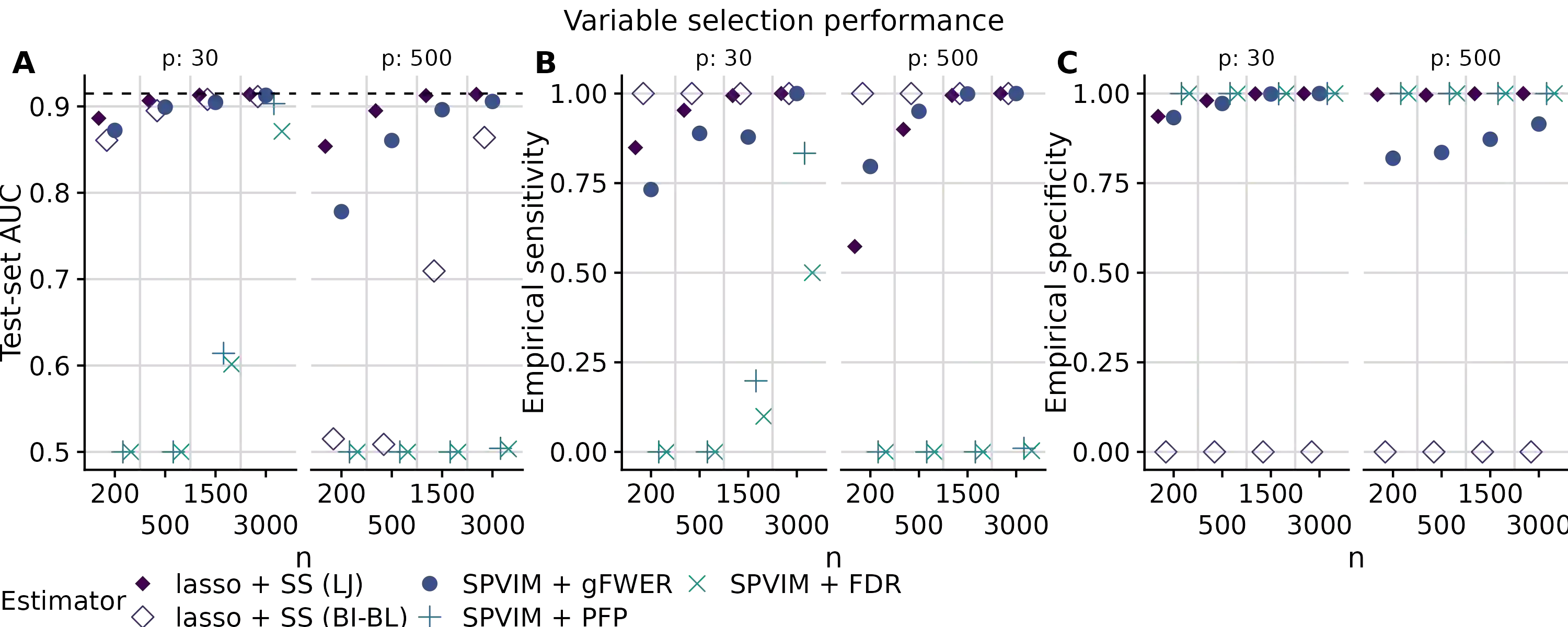
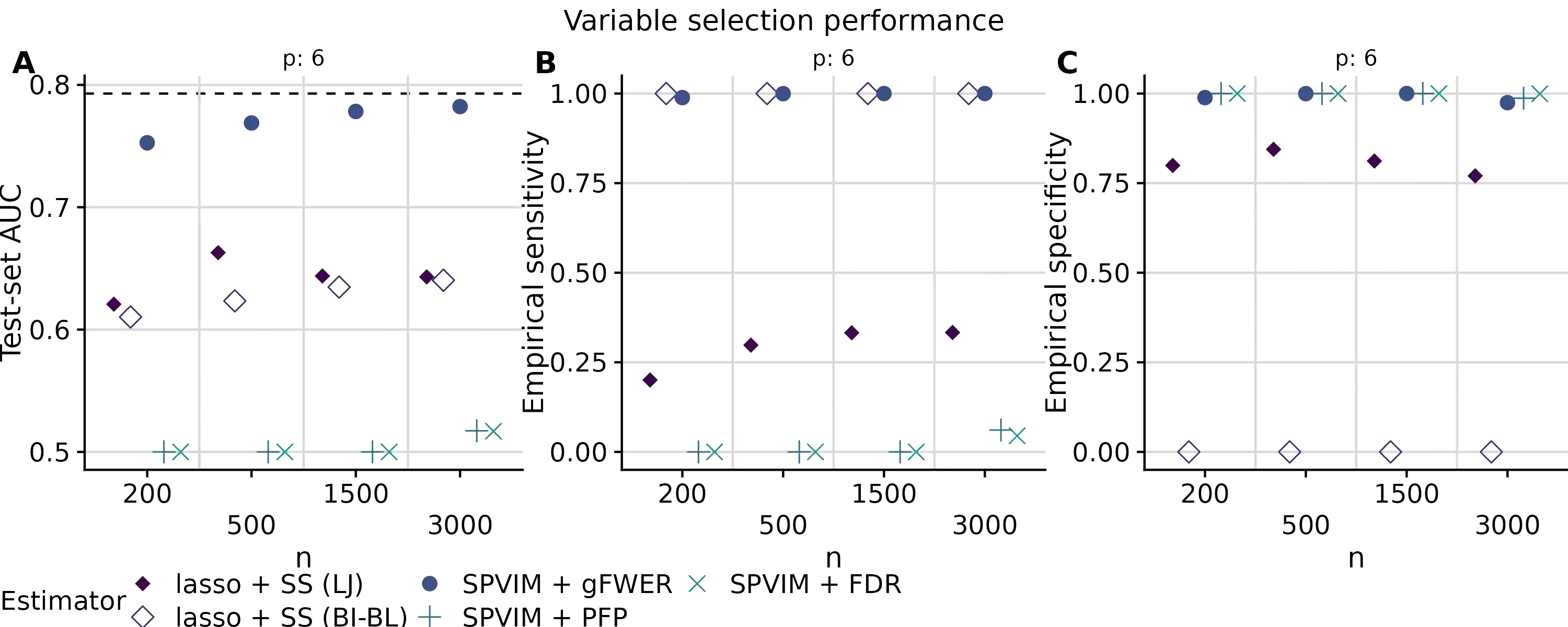
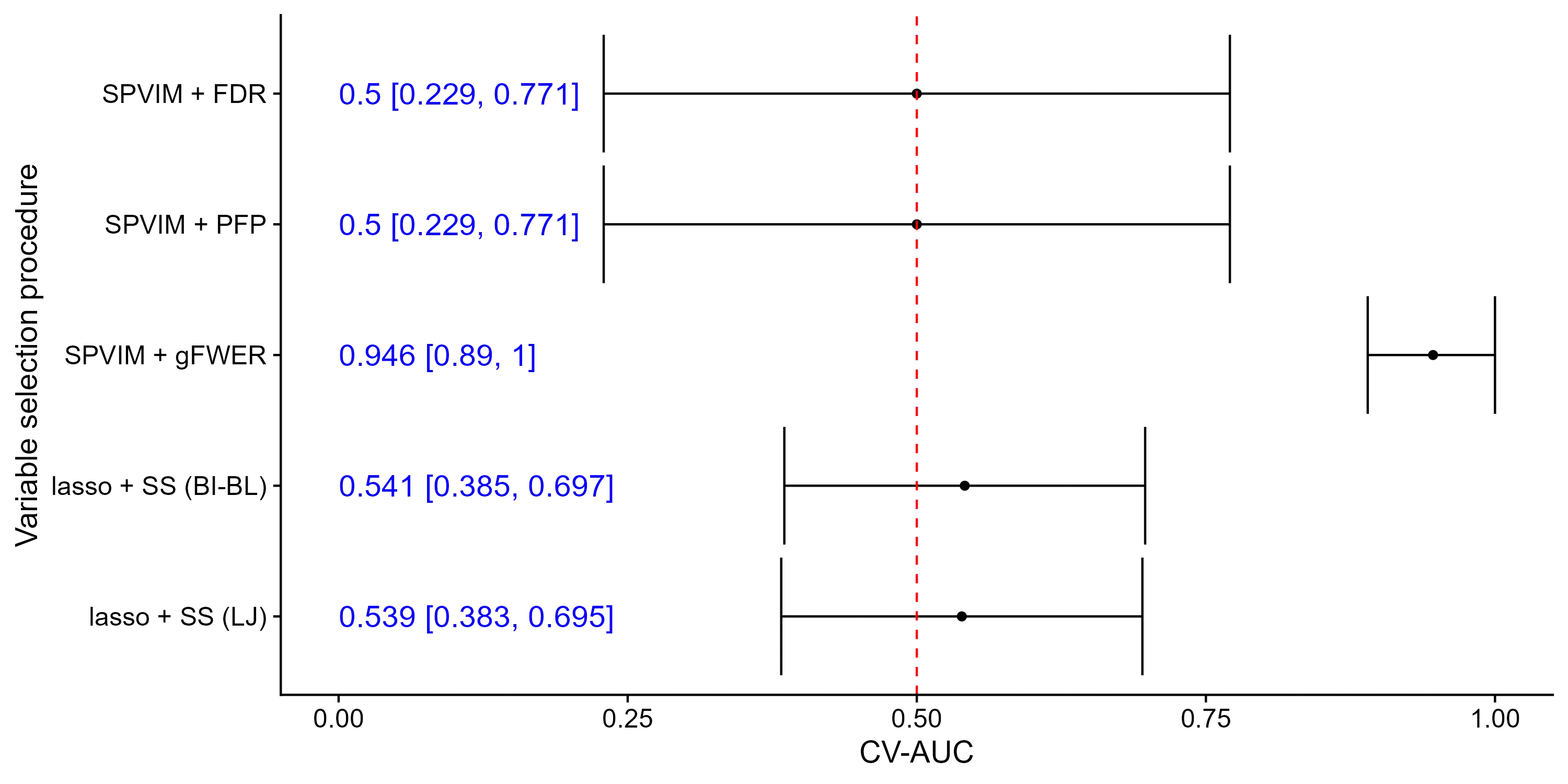
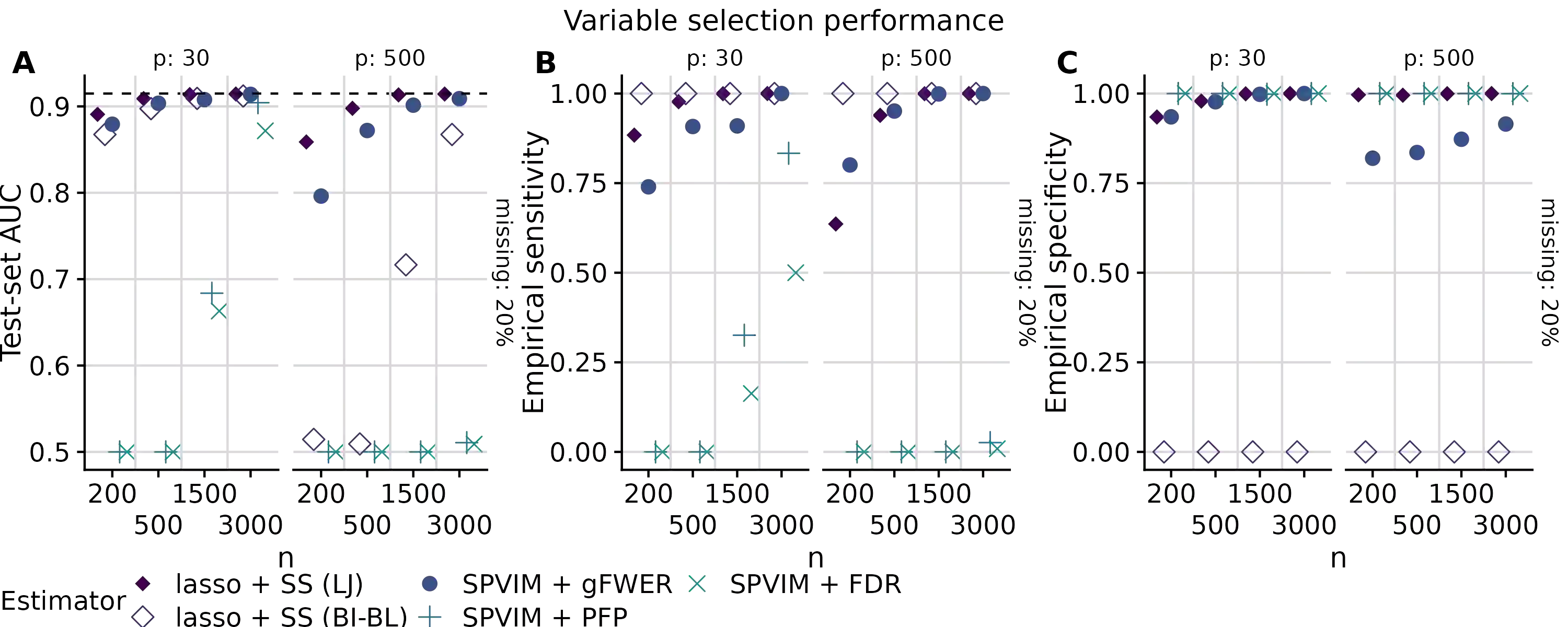
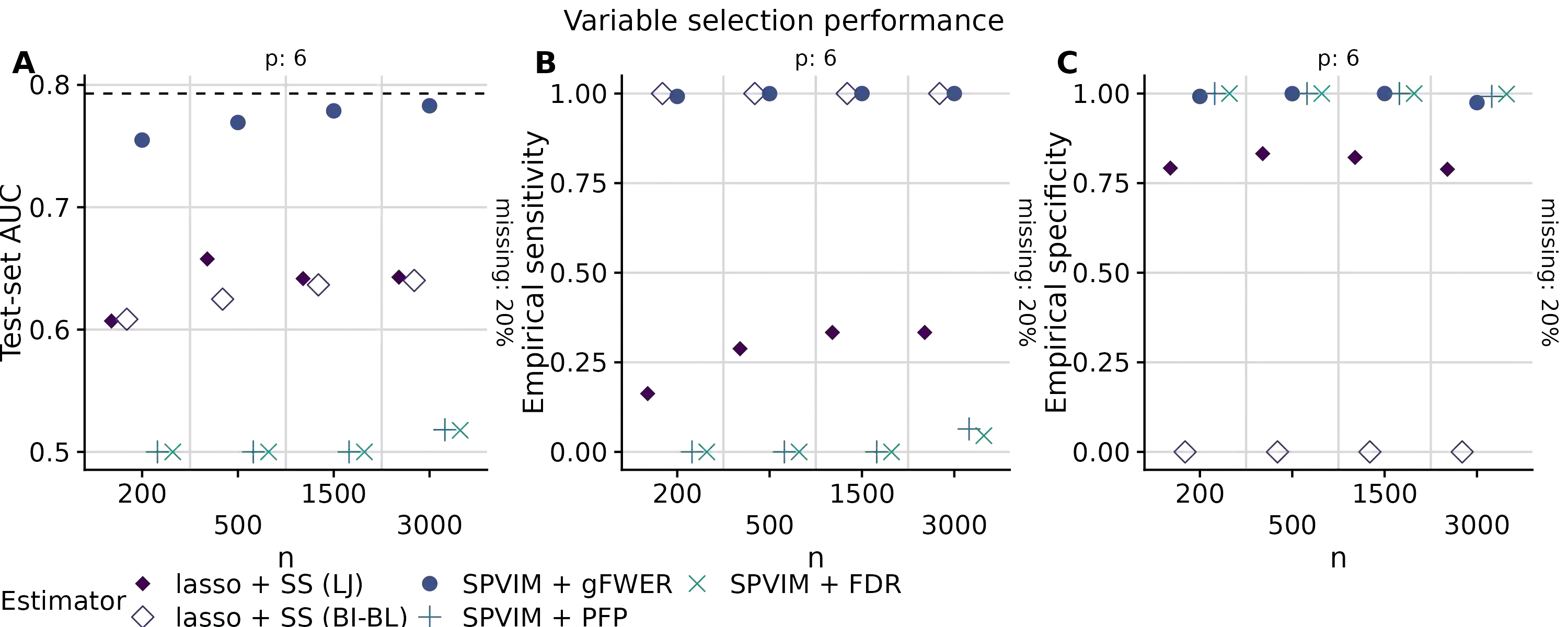
In many applications, it is of interest to identify a parsimonious set of features, or panel, from multiple candidates that achieves a desired level of performance in predicting a response. This task is often complicated in practice by missing data arising from the sampling design or other random mechanisms. Most recent work on variable selection in missing data contexts relies in some part on a finite-dimensional statistical model, e.g., a generalized or penalized linear model. In cases where this model is misspecified, the selected variables may not all be truly scientifically relevant and can result in panels with suboptimal classification performance. To address this limitation, we propose a nonparametric variable selection algorithm combined with multiple imputation to develop flexible panels in the presence of missing-at-random data. We outline strategies based on the proposed algorithm that achieve control of commonly used error rates. Through simulations, we show that our proposal has good operating characteristics and results in panels with higher classification and variable selection performance compared to several existing penalized regression approaches in cases where a generalized linear model is misspecified. Finally, we use the proposed method to develop biomarker panels for separating pancreatic cysts with differing malignancy potential in a setting where complicated missingness in the biomarkers arose due to limited specimen volumes.
翻译:在许多实际应用中,人们需要从多个候选变量中识别出一组简约的特征(即面板),使其在预测响应变量时达到期望的性能水平。然而,由于抽样设计或其他随机机制导致的缺失数据,这一任务往往变得复杂。目前关于缺失数据背景下变量选择的大多数研究,在某种程度上依赖于有限维统计模型(例如广义线性模型或惩罚线性模型)。当该模型被错误设定时,所选变量可能并非全部具有真正的科学相关性,并可能导致分类性能欠佳的面板。为解决这一局限性,我们提出一种结合多重插补的非参数变量选择算法,用于在随机缺失数据环境下生成灵活的面板。我们基于所提算法概述了能够控制常见错误率的策略。仿真研究表明,当广义线性模型被错误设定时,与几种现有惩罚回归方法相比,我们的方案具有良好的操作特性,能够得到分类性能和变量选择性能更高的面板。最后,我们将所提方法应用于胰腺囊肿生物标志物面板的开发,以区分具有不同恶性潜能的囊肿类型,该应用中因样本体积有限而导致生物标志物存在复杂的缺失模式。