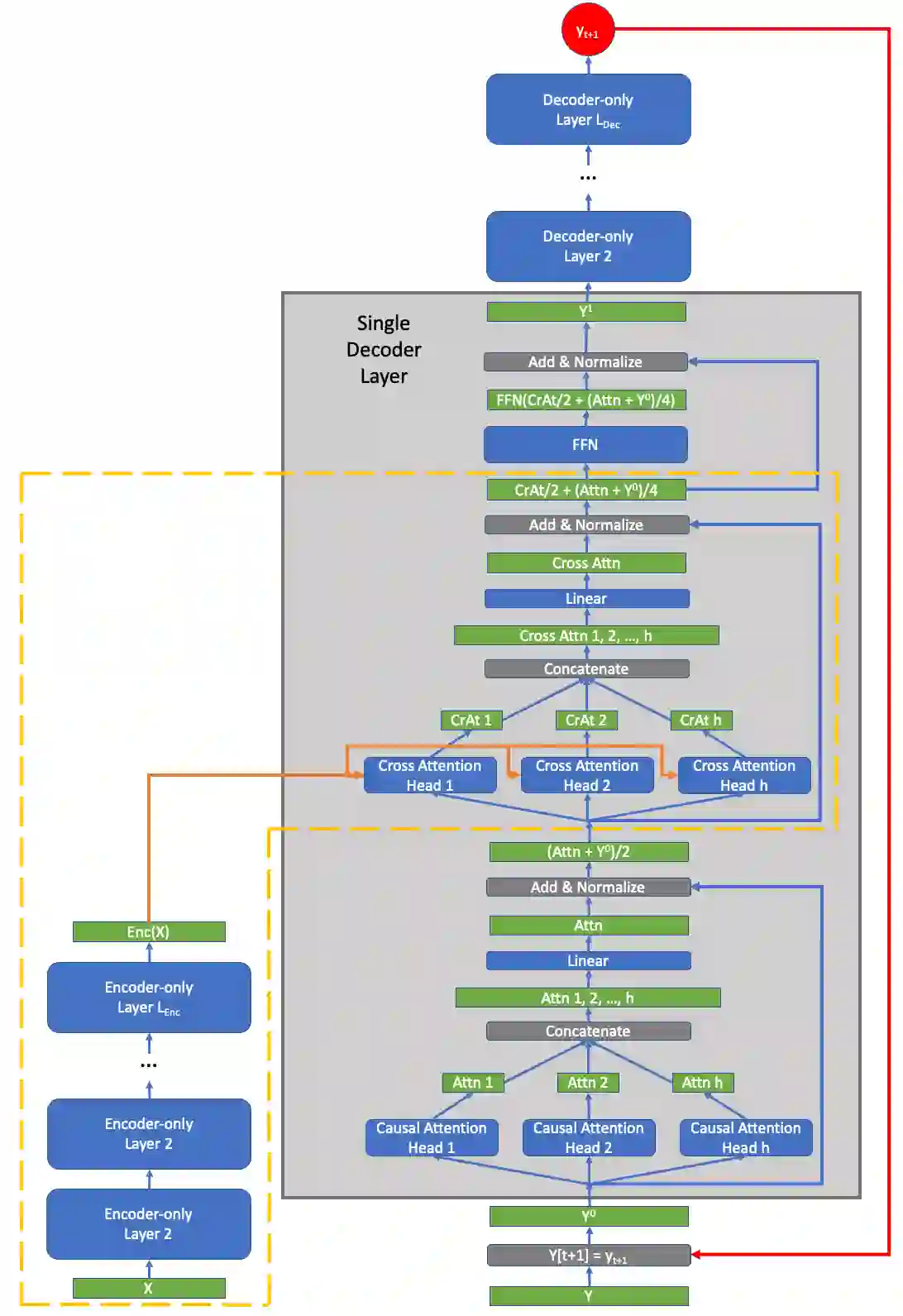
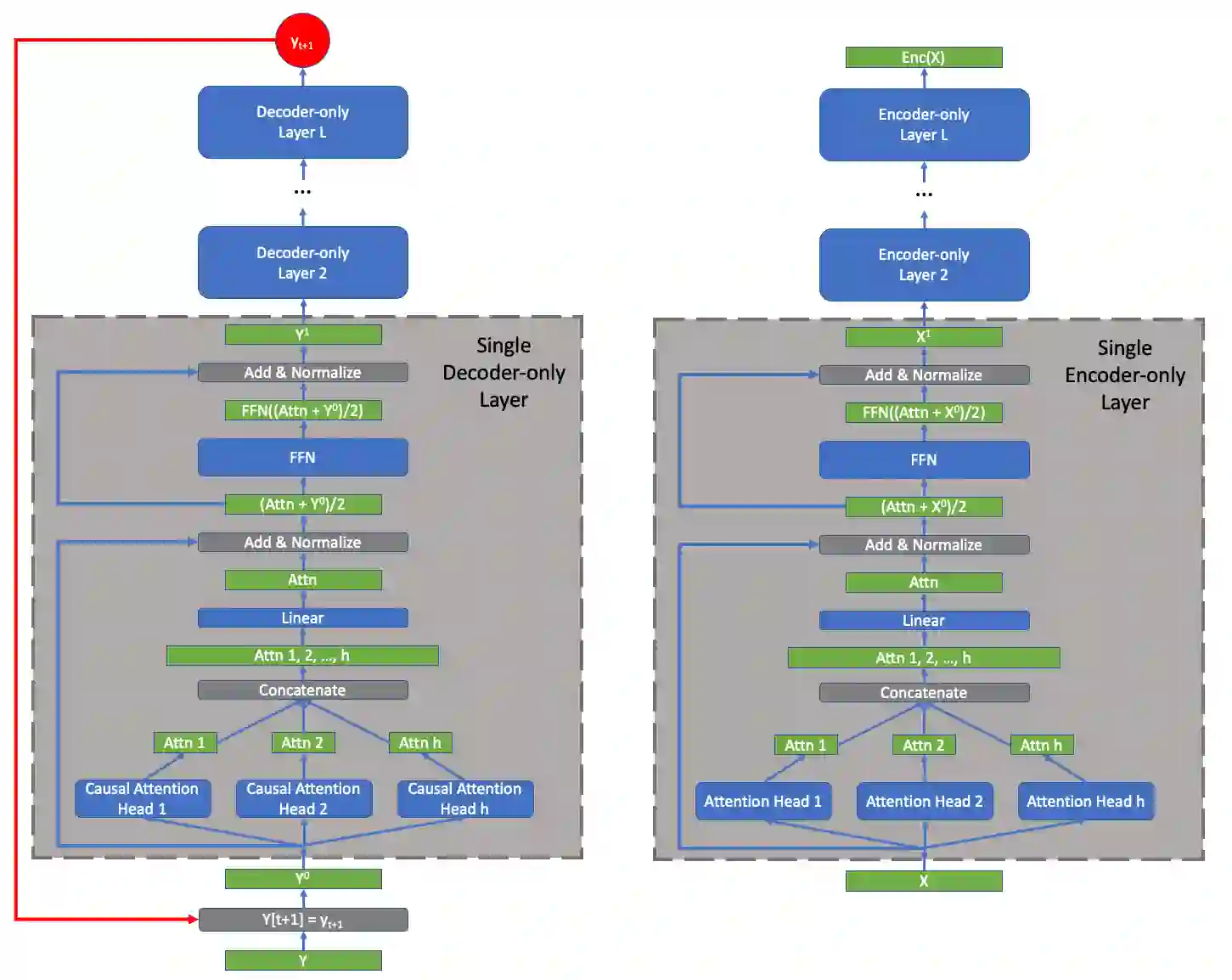
In this article we prove that the general transformer neural model undergirding modern large language models (LLMs) is Turing complete under reasonable assumptions. This is the first work to directly address the Turing completeness of the underlying technology employed in GPT-x as past work has focused on the more expressive, full auto-encoder transformer architecture. From this theoretical analysis, we show that the sparsity/compressibility of the word embedding is an important consideration for Turing completeness to hold. We also show that Transformers are are a variant of B machines studied by Hao Wang.
翻译:本文证明,在现代大型语言模型(LLM)中起核心作用的通用Transformer神经模型,在合理假设下具有图灵完备性。这是首项直接论证GPT-x所采用底层技术具有图灵完备性的工作,此前的研究主要聚焦于更具表达力的全自编码器Transformer架构。通过理论分析,我们发现词嵌入的稀疏性/可压缩性对于实现图灵完备性至关重要。我们还证明,Transformer 是Hao Wang所研究的B型机器的一种变体。