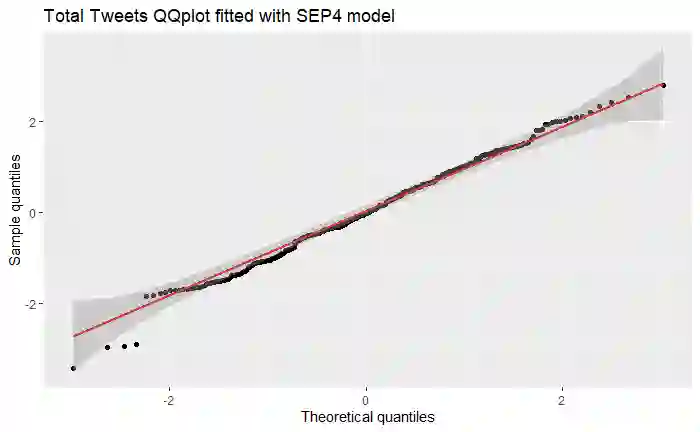
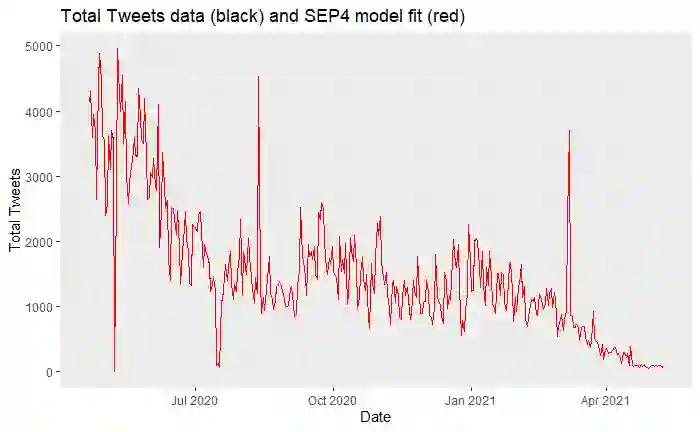
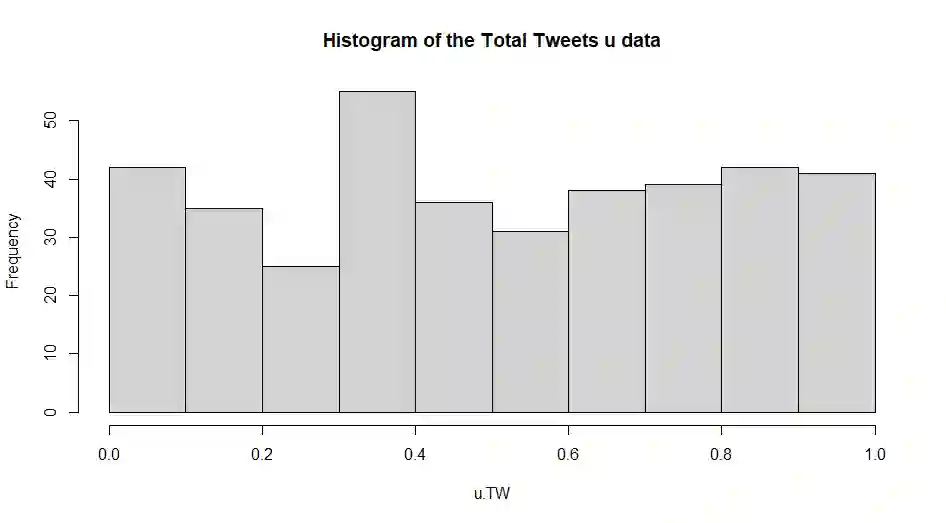
The Covid-19 pandemic presents a serious threat to people health, resulting in over 250 million confirmed cases and over 5 million deaths globally. To reduce the burden on national health care systems and to mitigate the effects of the outbreak, accurate modelling and forecasting methods for short- and long-term health demand are needed to inform government interventions aiming at curbing the pandemic. Current research on Covid-19 is typically based on a single source of information, specifically on structured historical pandemic data. Other studies are exclusively focused on unstructured online retrieved insights, such as data available from social media. However, the combined use of structured and unstructured information is still uncharted. This paper aims at filling this gap, by leveraging historical and social media information with a novel data integration methodology. The proposed approach is based on vine copulas, which allow us to exploit the dependencies between different sources of information. We apply the methodology to combine structured datasets retrieved from official sources and a big unstructured dataset of information collected from social media. The results show that the combined use of official and online generated information contributes to yield a more accurate assessment of the evolution of the Covid-19 pandemic, compared to the sole use of official data.
翻译:COVID-19大流行对人类健康构成严重威胁,全球已导致超过2.5亿确诊病例和500万人死亡。为减轻国家医疗系统的负担并缓解疫情的影响,需要针对短期和长期医疗健康需求的精确建模与预测方法,为政府旨在遏制疫情的干预措施提供信息支持。当前COVID-19研究通常基于单一信息源,特别是结构化的历史疫情数据。其他研究则主要聚焦于非结构化的在线检索信息,例如社交媒体数据。然而,结构化与非结构化信息的结合使用仍属未知领域。本文旨在通过一种新型数据集成方法,结合历史信息与社交媒体信息,弥补这一空白。所提出的方法基于藤蔓联结函数(Vine Copulas),能够利用不同信息源之间的相关性。我们将该方法应用于结合官方来源的结构化数据集以及从社交媒体收集的大规模非结构化信息数据集。结果表明,与仅使用官方数据相比,官方数据与在线生成信息的结合使用有助于更准确地评估COVID-19疫情的演变趋势。