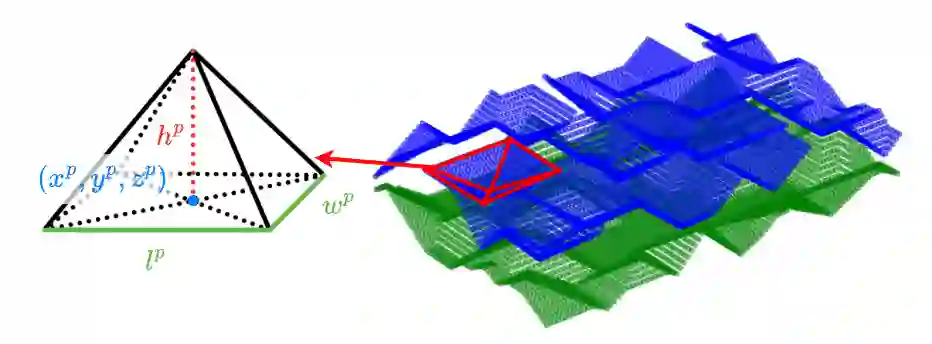
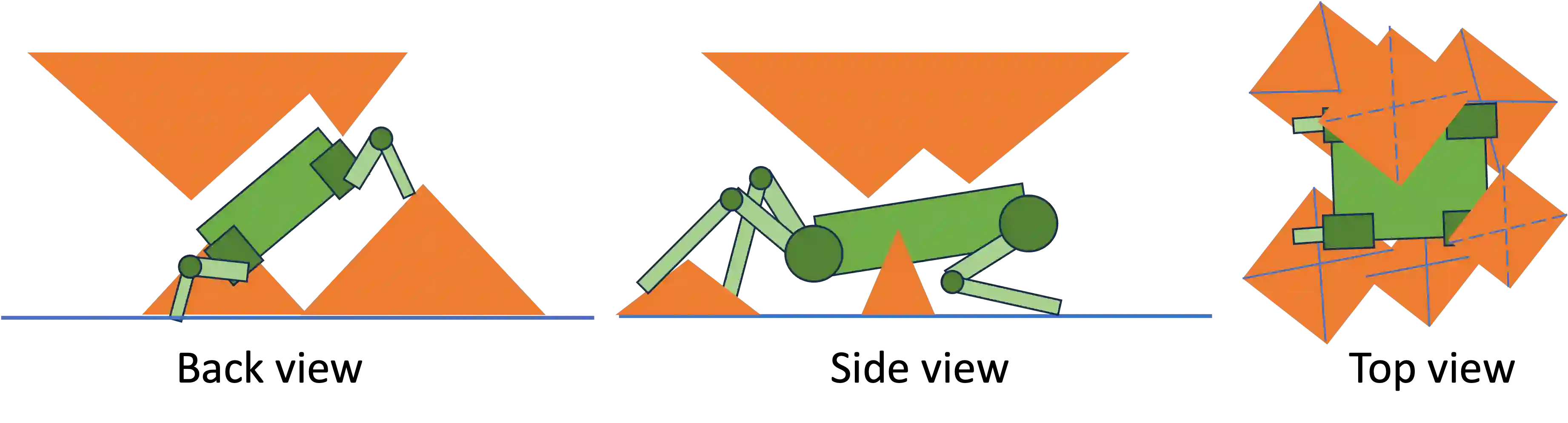
Recent advances of locomotion controllers utilizing deep reinforcement learning (RL) have yielded impressive results in terms of achieving rapid and robust locomotion across challenging terrain, such as rugged rocks, non-rigid ground, and slippery surfaces. However, while these controllers primarily address challenges underneath the robot, relatively little research has investigated legged mobility through confined 3D spaces, such as narrow tunnels or irregular voids, which impose all-around constraints. The cyclic gait patterns resulted from existing RL-based methods to learn parameterized locomotion skills characterized by motion parameters, such as velocity and body height, may not be adequate to navigate robots through challenging confined 3D spaces, requiring both agile 3D obstacle avoidance and robust legged locomotion. Instead, we propose to learn locomotion skills end-to-end from goal-oriented navigation in confined 3D spaces. To address the inefficiency of tracking distant navigation goals, we introduce a hierarchical locomotion controller that combines a classical planner tasked with planning waypoints to reach a faraway global goal location, and an RL-based policy trained to follow these waypoints by generating low-level motion commands. This approach allows the policy to explore its own locomotion skills within the entire solution space and facilitates smooth transitions between local goals, enabling long-term navigation towards distant goals. In simulation, our hierarchical approach succeeds at navigating through demanding confined 3D environments, outperforming both pure end-to-end learning approaches and parameterized locomotion skills. We further demonstrate the successful real-world deployment of our simulation-trained controller on a real robot.
翻译:深度强化学习(RL)驱动的运动控制器近期取得显著进展,在崎岖岩石、非刚性地面和光滑表面等复杂地形上实现了快速且稳健的运动能力。然而,现有控制器主要应对机器人下方的地形挑战,针对狭窄隧道或不规则空洞等受限三维空间(需考虑全方位约束)的腿式移动研究相对匮乏。基于现有强化学习方法通过运动参数(如速度和身体高度)习得的参数化运动技能,其循环步态模式可能不足以引导机器人穿越具有挑战性的受限三维空间——这既需要敏捷的三维避障能力,又需要稳健的腿式运动。为此,我们提出从目标导向的受限三维空间导航中端到端学习运动技能。针对跟踪远距离导航目标的低效性问题,我们引入分层运动控制器:经典规划器负责规划路径点以抵达远距离全局目标位置,而基于强化学习的策略通过生成低层运动指令来跟踪这些路径点。该方法允许策略在完整解空间中自主探索运动技能,并促进局部目标间的平滑过渡,从而实现向远距离目标的长期导航。仿真实验中,我们的分层方法成功通过了苛刻的受限三维环境,性能优于纯端到端学习方法与参数化运动技能。我们进一步将仿真训练的控制器成功部署至真实机器人上,验证了其实际应用潜力。