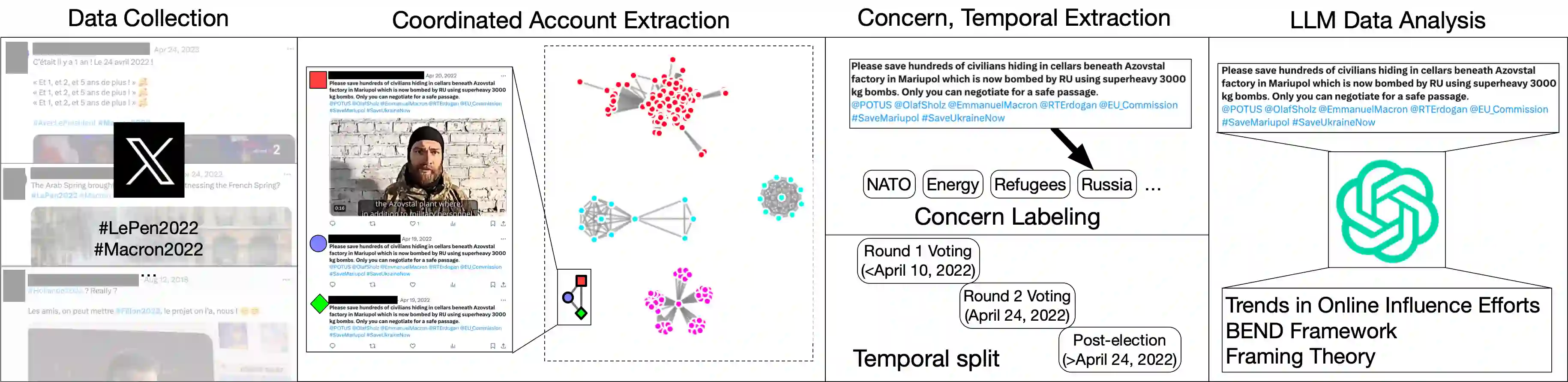
Adversarial information operations can destabilize societies by undermining fair elections, manipulating public opinions on policies, and promoting scams. Despite their widespread occurrence and potential impacts, our understanding of influence campaigns is limited by manual analysis of messages and subjective interpretation of their observable behavior. In this paper, we explore whether these limitations can be mitigated with large language models (LLMs), using GPT-3.5 as a case-study for coordinated campaign annotation. We first use GPT-3.5 to scrutinize 126 identified information operations spanning over a decade. We utilize a number of metrics to quantify the close (if imperfect) agreement between LLM and ground truth descriptions. We next extract coordinated campaigns from two large multilingual datasets from X (formerly Twitter) that respectively discuss the 2022 French election and 2023 Balikaran Philippine-U.S. military exercise in 2023. For each coordinated campaign, we use GPT-3.5 to analyze posts related to a specific concern and extract goals, tactics, and narrative frames, both before and after critical events (such as the date of an election). While the GPT-3.5 sometimes disagrees with subjective interpretation, its ability to summarize and interpret demonstrates LLMs' potential to extract higher-order indicators from text to provide a more complete picture of the information campaigns compared to previous methods.
翻译:对抗性信息操作通过破坏公平选举、操纵公共舆论对政策的看法以及助长诈骗活动,可能破坏社会稳定。尽管这类操作广泛存在且具有潜在影响,但我们对影响力活动的理解仍受限于人工信息分析及其可观察行为的主观解读。本文以GPT-3.5作为协同活动标注的案例研究,探讨大语言模型(LLMs)能否缓解这些局限性。我们首先使用GPT-3.5审阅了跨越十余年的126项已识别信息操作,通过多项指标量化大语言模型与真实描述之间紧密(尽管不完全一致)的吻合度。接着,我们从X平台(原Twitter)的两个大型多语言数据集中提取协同活动,分别涉及2022年法国大选和2023年菲律宾与美国“Balikaran”联合军事演习的讨论。针对每项协同活动,我们使用GPT-3.5分析特定议题相关帖文,提取关键事件(如选举日期)前后信息操作的目标、策略和叙事框架。尽管GPT-3.5有时与主观解读存在分歧,但其总结与解释能力表明,相较于传统方法,大语言模型能够从文本中提取高阶指标,从而更全面地呈现信息操作的全貌。