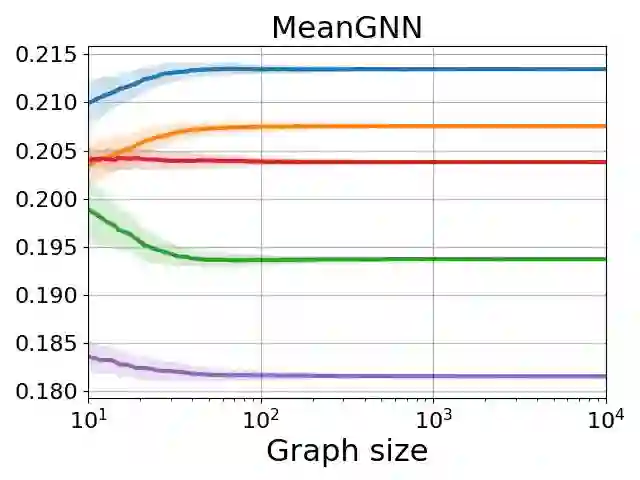
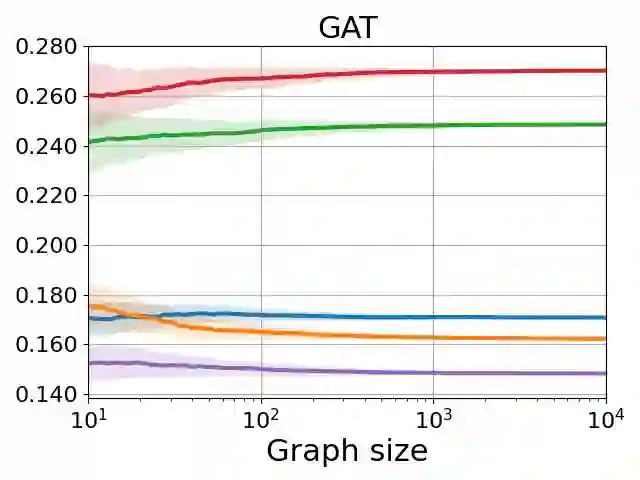
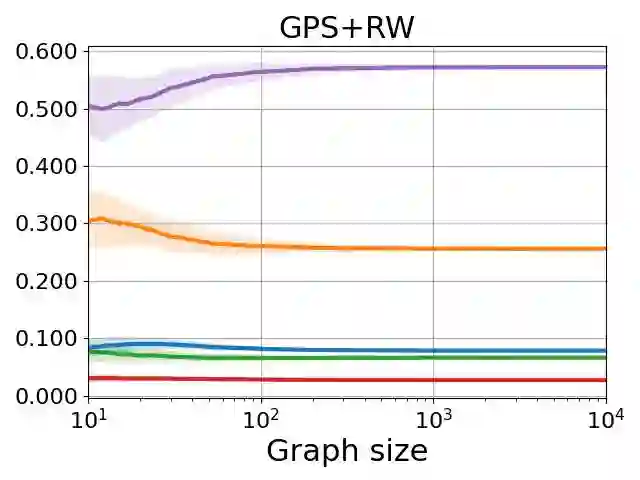
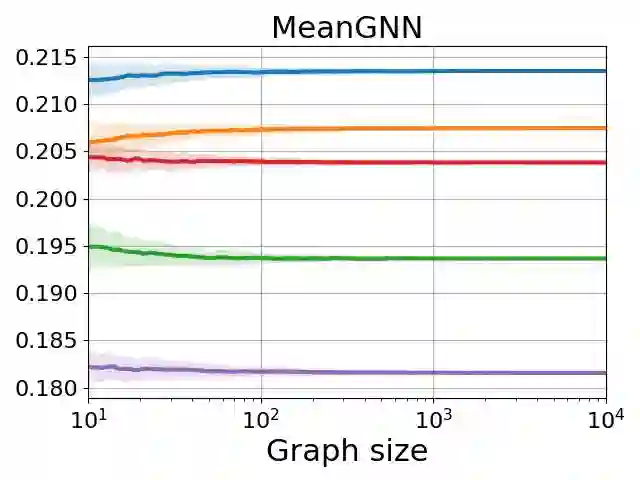
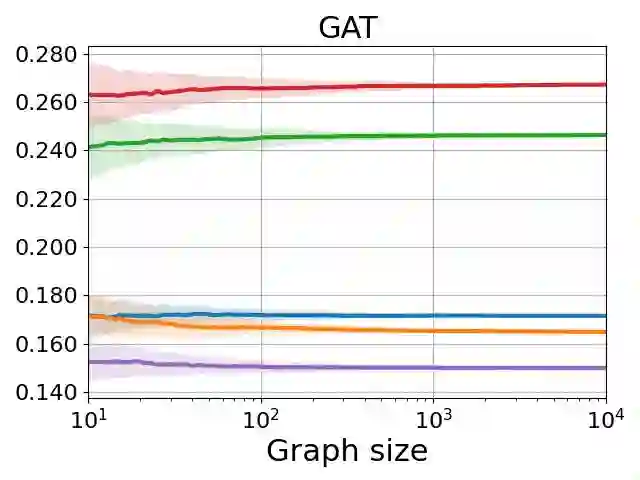
Graph neural networks (GNNs) are the predominant architectures for a variety of learning tasks on graphs. We present a new angle on the expressive power of GNNs by studying how the predictions of a GNN probabilistic classifier evolve as we apply it on larger graphs drawn from some random graph model. We show that the output converges to a constant function, which upper-bounds what these classifiers can express uniformly. This convergence phenomenon applies to a very wide class of GNNs, including state of the art models, with aggregates including mean and the attention-based mechanism of graph transformers. Our results apply to a broad class of random graph models, including the (sparse) Erd\H{o}s-R\'enyi model and the stochastic block model. We empirically validate these findings, observing that the convergence phenomenon already manifests itself on graphs of relatively modest size.
翻译:图神经网络(GNNs)是处理图上多种学习任务的主流架构。我们通过研究GNN概率分类器在来自随机图模型的更大图上的预测演化,为GNN的表达能力提供了新视角。我们证明其输出收敛于常数函数,这给出了这些分类器可统一表达能力的上界。该收敛现象适用于极广泛的GNN类别,包括最先进模型,其聚合函数涵盖均值以及图Transformer的注意力机制。我们的结果适用于广泛的随机图模型,包括(稀疏)Erdős–Rényi模型和随机块模型。我们通过实验验证了这些发现,观察到该收敛现象在规模相对适中的图上已开始显现。