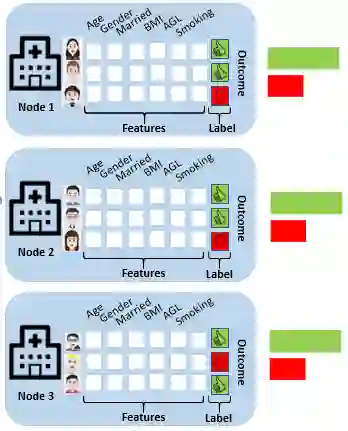
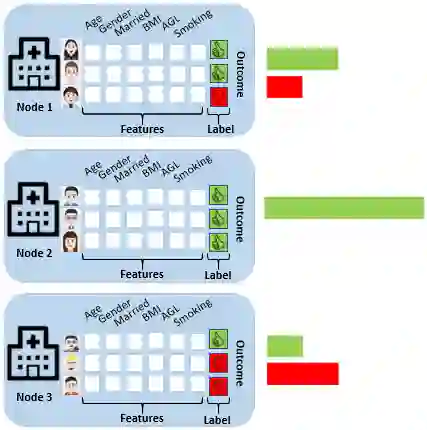
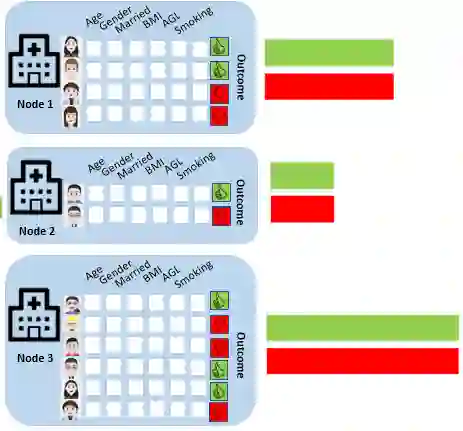
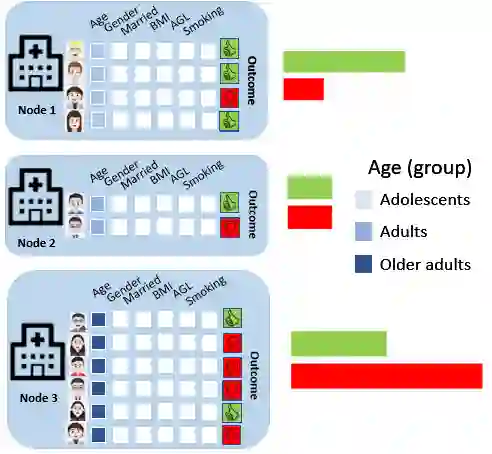
Federated Learning (FL) allows multiple privacy-sensitive applications to leverage their dataset for a global model construction without any disclosure of the information. One of those domains is healthcare, where groups of silos collaborate in order to generate a global predictor with improved accuracy and generalization. However, the inherent challenge lies in the high heterogeneity of medical data, necessitating sophisticated techniques for assessment and compensation. This paper presents a comprehensive exploration of the mathematical formalization and taxonomy of heterogeneity within FL environments, focusing on the intricacies of medical data. In particular, we address the evaluation and comparison of the most popular FL algorithms with respect to their ability to cope with quantity-based, feature and label distribution-based heterogeneity. The goal is to provide a quantitative evaluation of the impact of data heterogeneity in FL systems for healthcare networks as well as a guideline on FL algorithm selection. Our research extends beyond existing studies by benchmarking seven of the most common FL algorithms against the unique challenges posed by medical data use cases. The paper targets the prediction of the risk of stroke recurrence through a set of tabular clinical reports collected by different federated hospital silos: data heterogeneity frequently encountered in this scenario and its impact on FL performance are discussed.
翻译:联邦学习(FL)使多个隐私敏感型应用能够利用其数据集构建全局模型,同时不泄露任何信息。医疗领域便是其中之一,各数据孤岛协同合作以生成具有更高精度和泛化能力的全局预测器。然而,医疗数据的高度异质性构成了固有挑战,亟需开发精密复杂的评估与补偿技术。本文系统探讨了FL环境中异质性的数学形式化表述与分类体系,重点聚焦医疗数据的复杂特征。特别地,我们针对最流行的FL算法在应对基于数量、特征和标签分布的异质性能力进行了评估与比较。研究旨在量化评估数据异质性对医疗网络FL系统的影响,并为FL算法选择提供指导准则。通过针对医疗数据用例的特殊挑战,对七种主流FL算法进行基准测试,本工作超越了现有研究范畴。论文以不同联邦医院数据孤岛收集的表格化临床报告为依托,预测卒中复发风险:深入讨论了该场景中频繁出现的数据异质性现象及其对FL性能的影响。