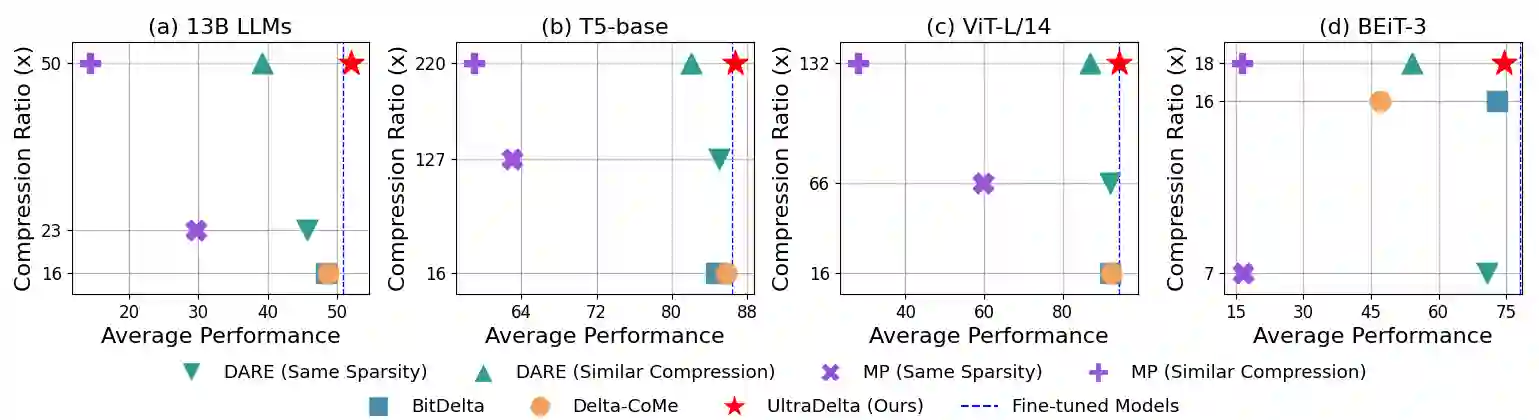
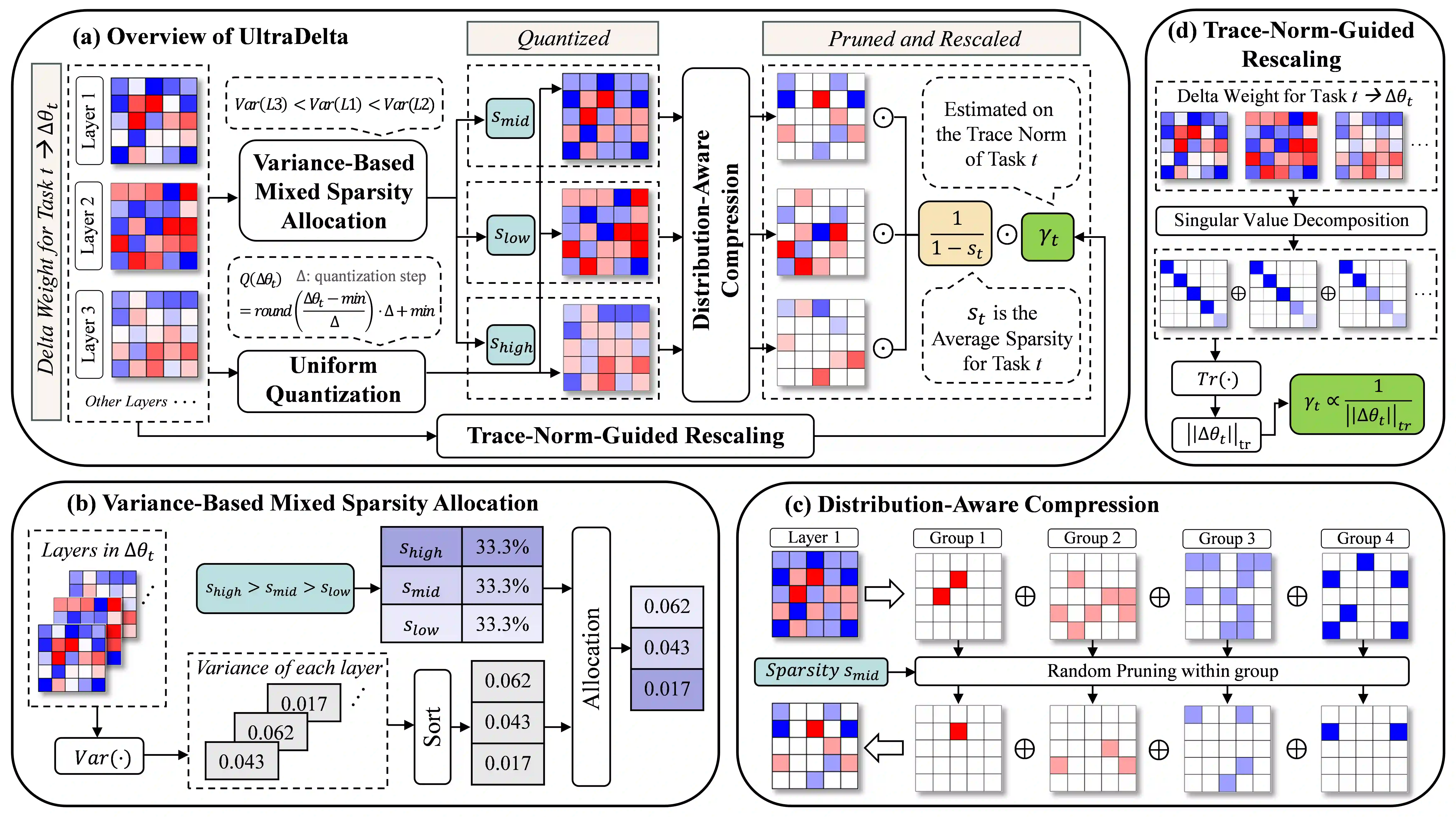
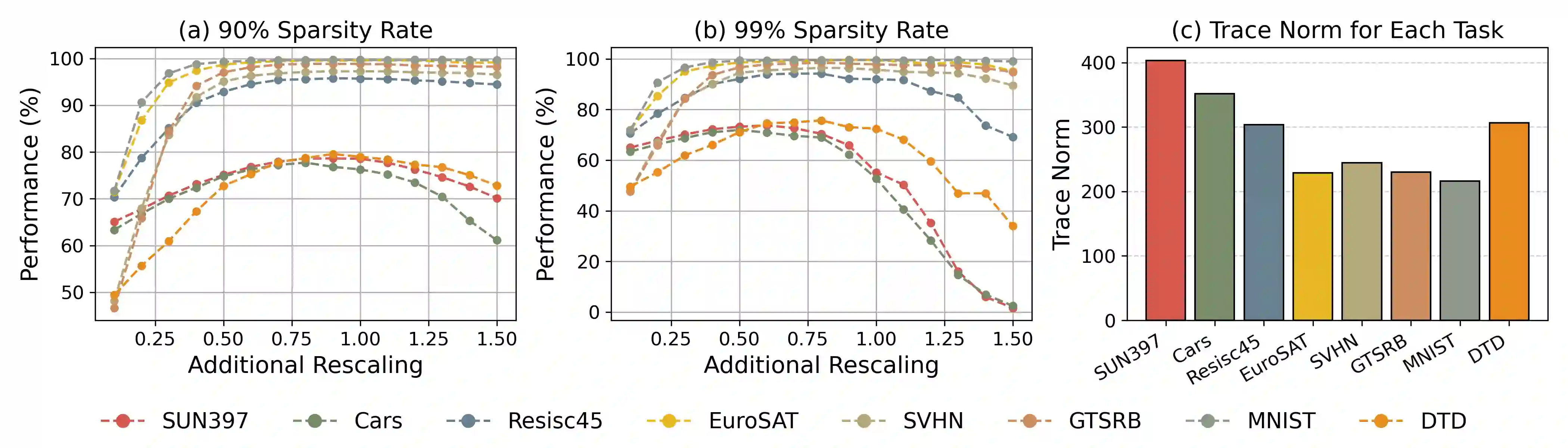
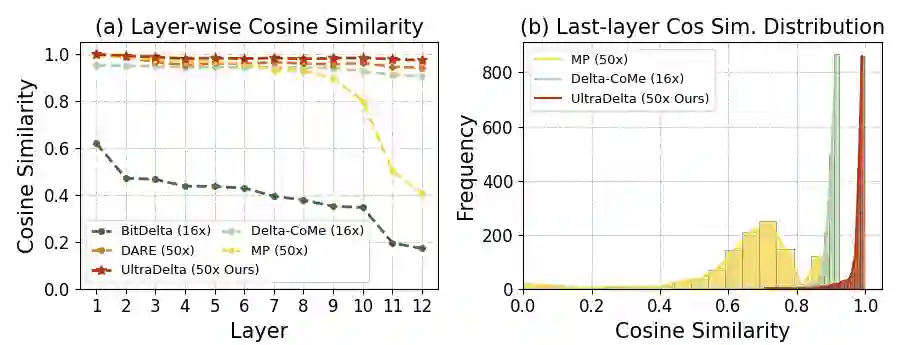
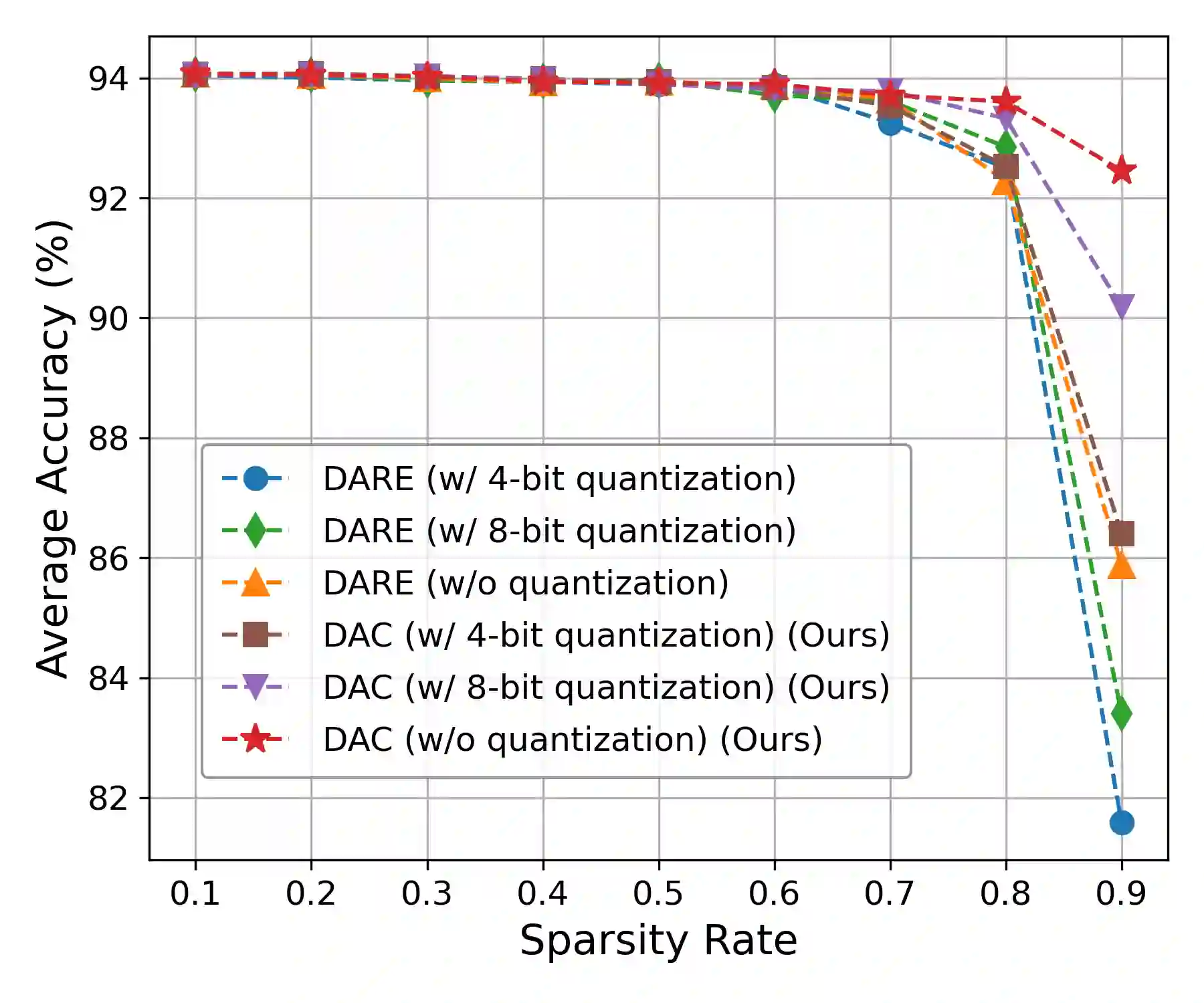
With the rise of the fine-tuned-pretrained paradigm, storing numerous fine-tuned models for multi-tasking creates significant storage overhead. Delta compression alleviates this by storing only the pretrained model and the highly compressed delta weights (the differences between fine-tuned and pretrained model weights). However, existing methods fail to maintain both high compression and performance, and often rely on data. To address these challenges, we propose UltraDelta, the first data-free delta compression pipeline that achieves both ultra-high compression and strong performance. UltraDelta is designed to minimize redundancy, maximize information, and stabilize performance across inter-layer, intra-layer, and global dimensions, using three key components: (1) Variance-Based Mixed Sparsity Allocation assigns sparsity based on variance, giving lower sparsity to high-variance layers to preserve inter-layer information. (2) Distribution-Aware Compression applies uniform quantization and then groups parameters by value, followed by group-wise pruning, to better preserve intra-layer distribution. (3) Trace-Norm-Guided Rescaling uses the trace norm of delta weights to estimate a global rescaling factor, improving model stability under higher compression. Extensive experiments across (a) large language models (fine-tuned on LLaMA-2 7B and 13B) with up to 50x compression, (b) general NLP models (RoBERTa-base, T5-base) with up to 224x compression, (c) vision models (ViT-B/32, ViT-L/14) with up to 132x compression, and (d) multi-modal models (BEiT-3) with 18x compression, demonstrate that UltraDelta consistently outperforms existing methods, especially under ultra-high compression. Code is available at https://github.com/xiaohuiwang000/UltraDelta.
翻译:随着微调预训练范式的兴起,为多任务存储大量微调模型带来了显著的存储开销。差分压缩通过仅存储预训练模型和高度压缩的差分权重(微调模型与预训练模型权重之间的差异)来缓解这一问题。然而,现有方法难以同时保持高压缩率和模型性能,且通常依赖于数据。为解决这些挑战,我们提出了UltraDelta,首个实现超高压缩与强大性能的无数据差分压缩流程。UltraDelta旨在从层间、层内和全局三个维度最小化冗余、最大化信息并稳定性能,其包含三个关键组件:(1) 基于方差的混合稀疏度分配:根据方差分配稀疏度,对高方差层赋予较低稀疏度以保留层间信息。(2) 分布感知压缩:先应用均匀量化,然后按参数值分组,再进行分组剪枝,以更好地保留层内分布。(3) 迹范数引导的重新缩放:利用差分权重的迹范数估计全局重新缩放因子,以提升模型在更高压缩率下的稳定性。在以下领域的广泛实验证明了UltraDelta始终优于现有方法,尤其是在超高压缩率下:(a) 大语言模型(基于LLaMA-2 7B和13B微调),压缩比高达50倍;(b) 通用NLP模型(RoBERTa-base、T5-base),压缩比高达224倍;(c) 视觉模型(ViT-B/32、ViT-L/14),压缩比高达132倍;(d) 多模态模型(BEiT-3),压缩比为18倍。代码发布于 https://github.com/xiaohuiwang000/UltraDelta。