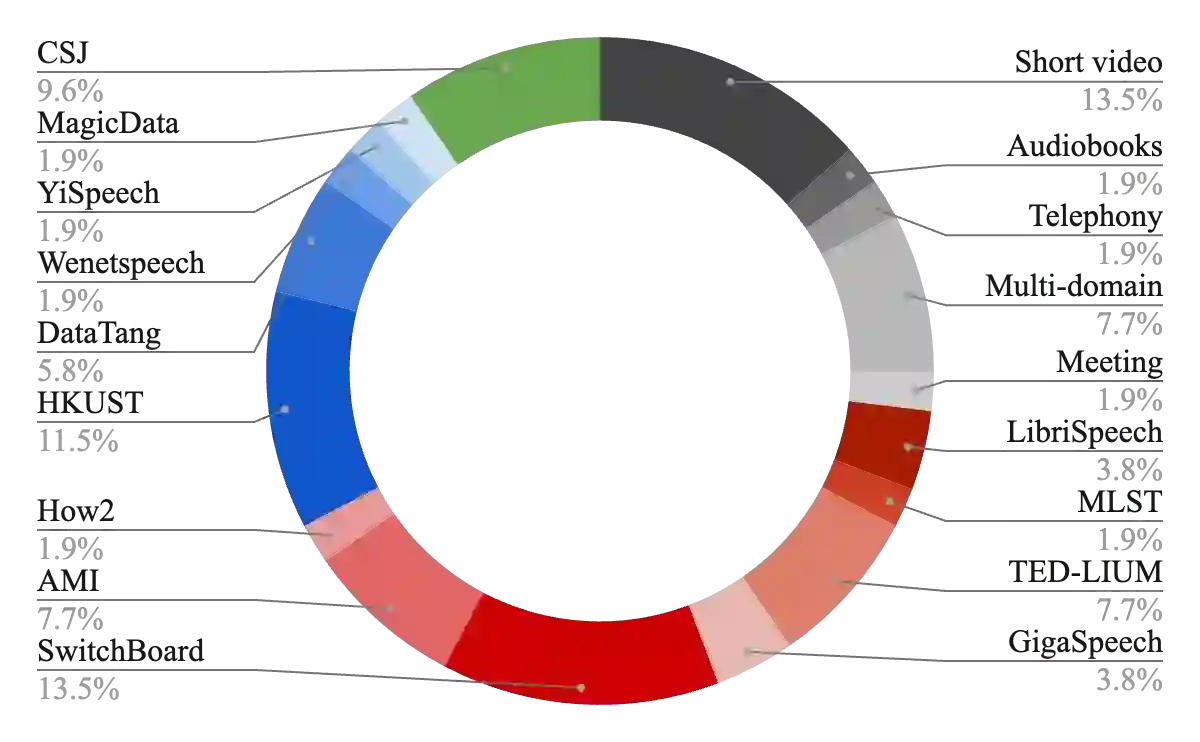
The vast majority of ASR research uses corpora in which both the training and test data have been pre-segmented into utterances. In most real-word ASR use-cases, however, test audio is not segmented, leading to a mismatch between inference-time conditions and models trained on segmented utterances. In this paper, we re-release three standard ASR corpora - TED-LIUM 3, Gigapeech, and VoxPopuli-en - with updated transcription and alignments to enable their use for long-form ASR research. We use these reconstituted corpora to study the train-test mismatch problem for transducers and attention-based encoder-decoders (AEDs), confirming that AEDs are more susceptible to this issue. Finally, we benchmark a simple long-form training for these models, showing its efficacy for model robustness under this domain shift.
翻译:绝大多数自动语音识别(ASR)研究使用的语料库中,训练数据和测试数据均预先分割为话语片段。然而,在实际ASR应用场景中,测试音频通常未经分割,导致推理条件与基于分割话语训练的模型之间存在失配问题。本文重新发布了三个标准ASR语料库——TED-LIUM 3、Gigapeech和VoxPopuli-en,并更新了转录文本与对齐标注,以支持其在长篇ASR研究中的应用。通过重构后的语料库,我们针对序列转导模型(transducers)与基于注意力机制的编码器-解码器(AEDs)研究了训练-测试失配问题,证实AEDs更容易受此影响。最后,我们对此类模型的长篇训练方案进行了基准测试,验证了该方案在领域偏移条件下对提升模型鲁棒性的有效性。