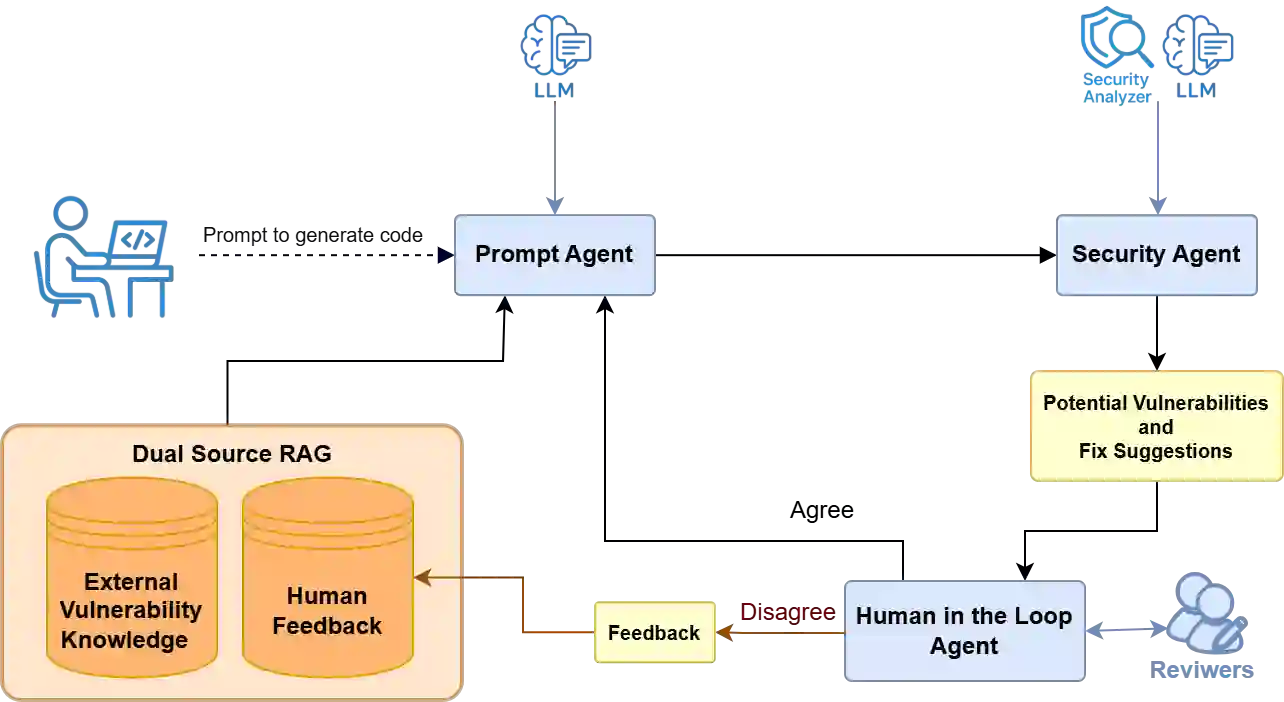
Existing literature heavily relies on static analysis tools to evaluate LLMs for secure code generation and vulnerability detection. We reviewed 1,080 LLM-generated code samples, built a human-validated ground-truth, and compared the outputs of two widely used static security tools, CodeQL and Semgrep, against this corpus. While 61% of the samples were genuinely secure, Semgrep and CodeQL classified 60% and 80% as secure, respectively. Despite the apparent agreement in aggregate statistics, per-sample analysis reveals substantial discrepancies: only 65% of Semgrep's and 61% of CodeQL's reports correctly matched the ground truth. These results question the reliability of static analysis tools as sole evaluators of code security and underscore the need for expert feedback. Building on this insight, we propose a conceptual framework that persistently stores human feedback in a dynamic retrieval-augmented generation pipeline, enabling LLMs to reuse past feedback for secure code generation and vulnerability detection.
翻译:现有文献严重依赖静态分析工具来评估LLM在安全代码生成与漏洞检测方面的性能。本研究审查了1,080个LLM生成的代码样本,构建了经人工验证的基准真值,并将两种广泛使用的静态安全工具(CodeQL与Semgrep)的输出结果与该语料库进行对比。虽然61%的样本确实安全,但Semgrep和CodeQL分别将60%和80%的样本归类为安全。尽管聚合统计数据呈现表面一致性,但逐样本分析揭示了显著差异:Semgrep仅65%、CodeQL仅61%的检测报告与基准真值准确匹配。这些结果对静态分析工具作为代码安全性唯一评估指标的可靠性提出质疑,并凸显了专家反馈的必要性。基于此发现,我们提出一个概念框架,将人类反馈持久存储在动态检索增强生成流程中,使LLM能够复用历史反馈以提升安全代码生成与漏洞检测能力。