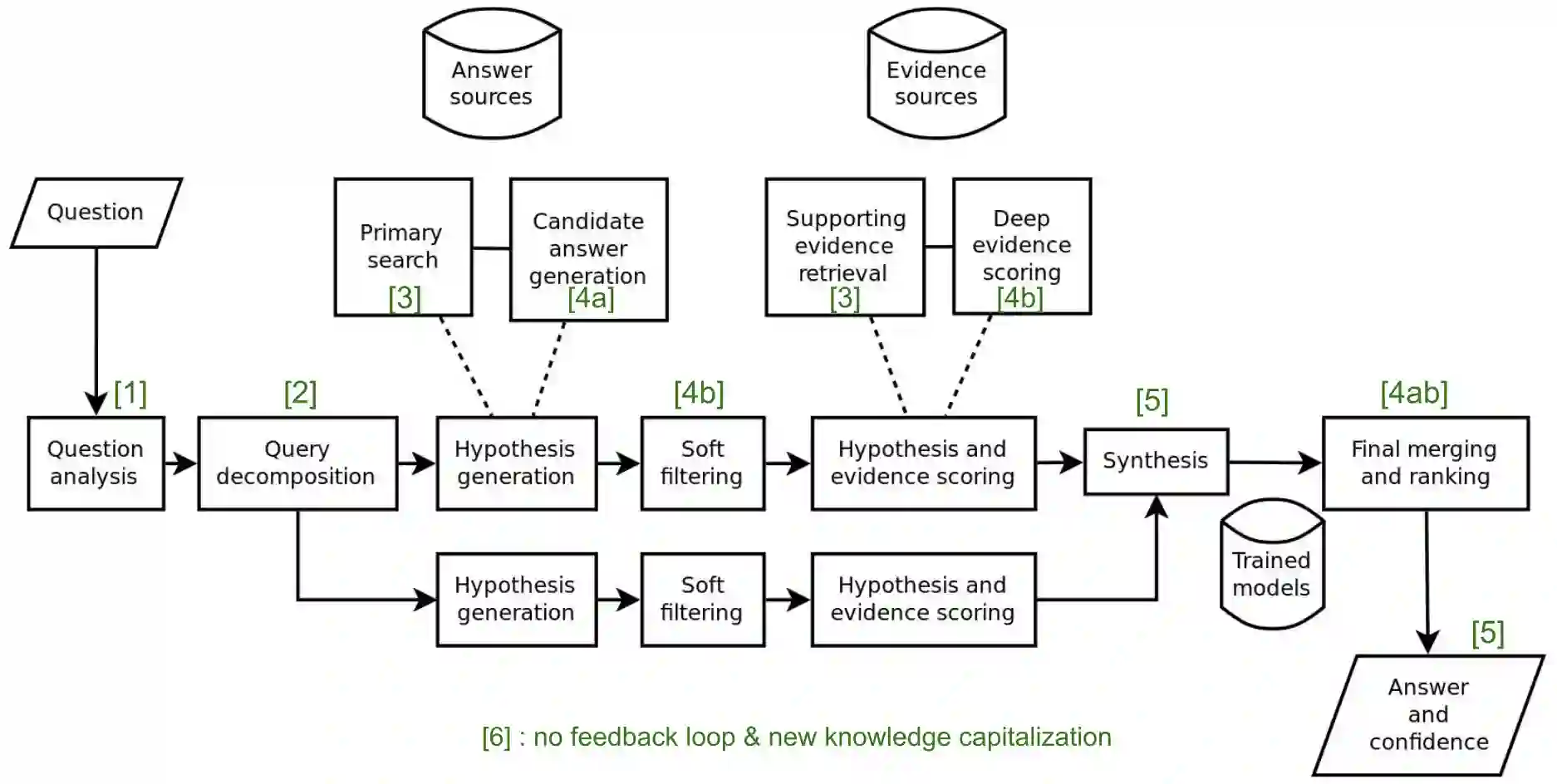
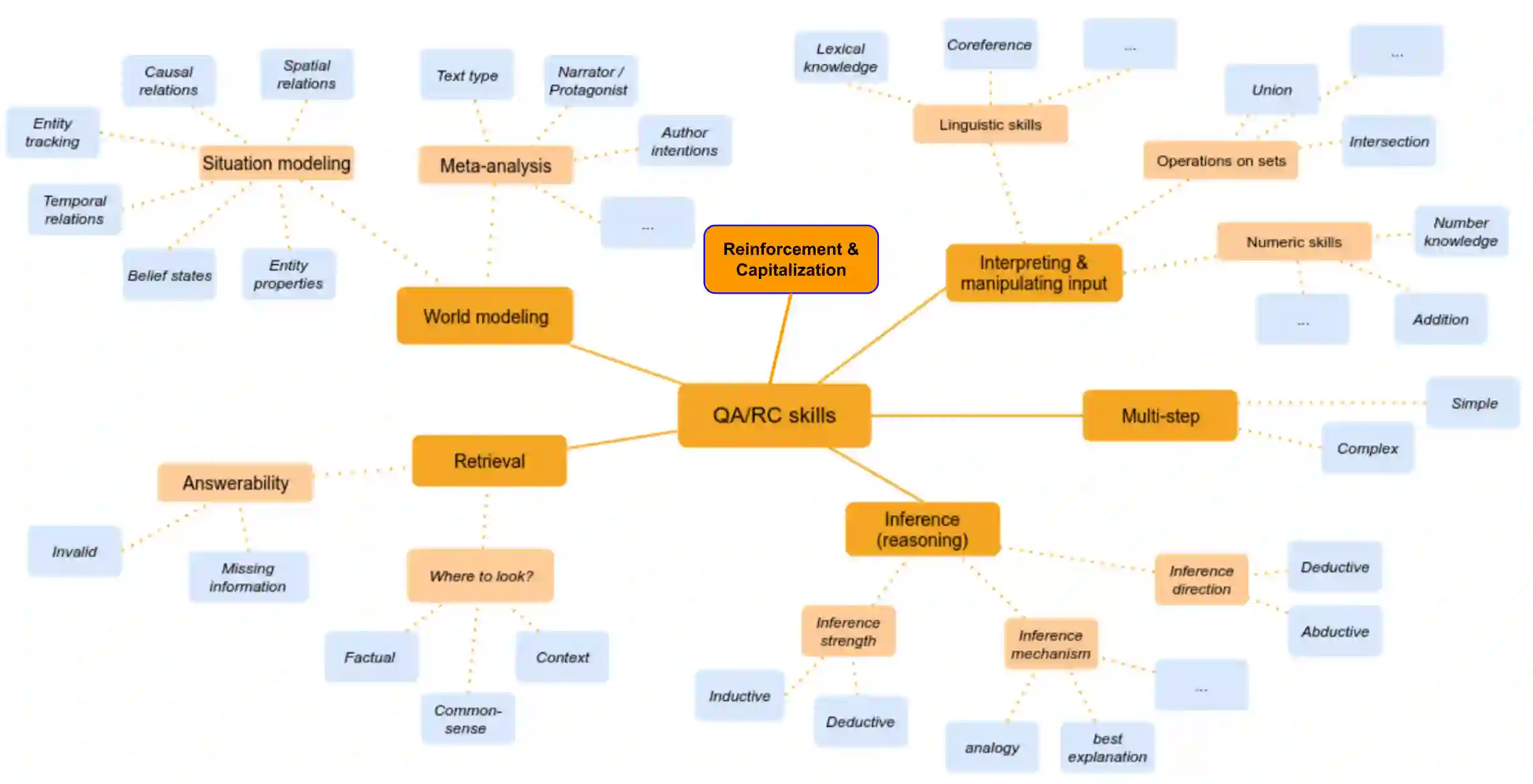
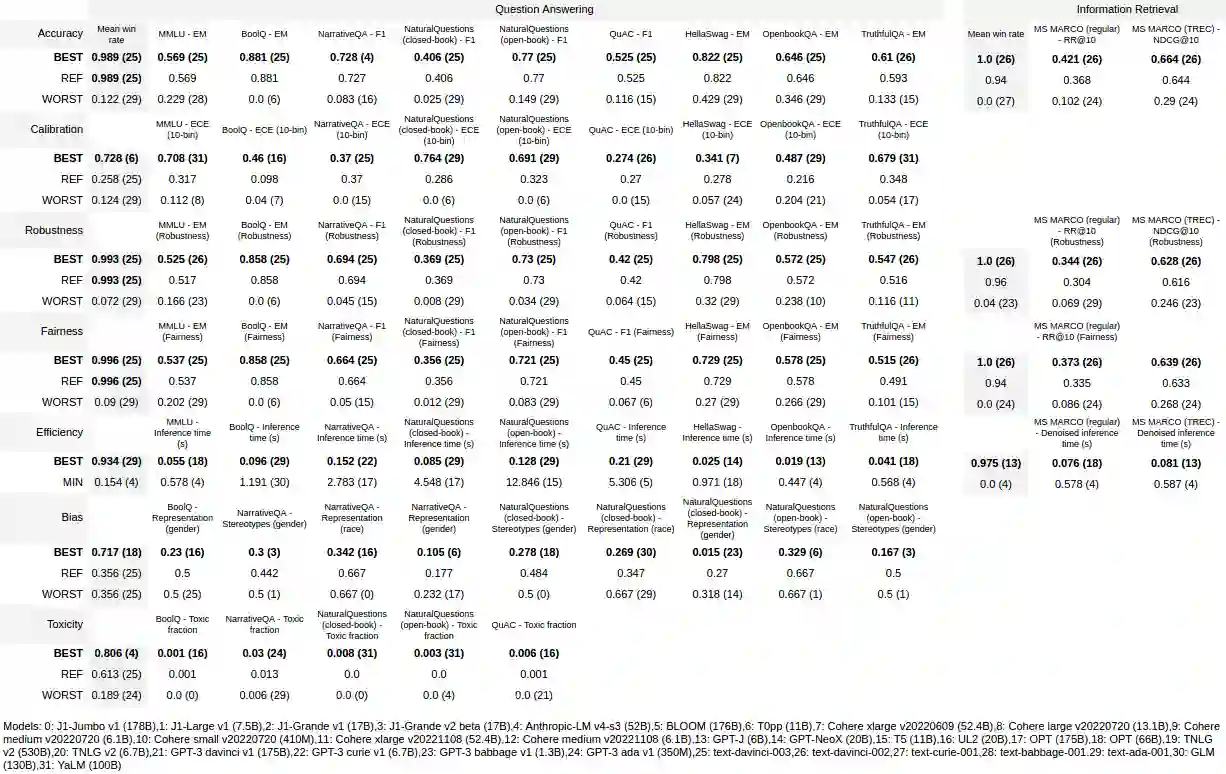
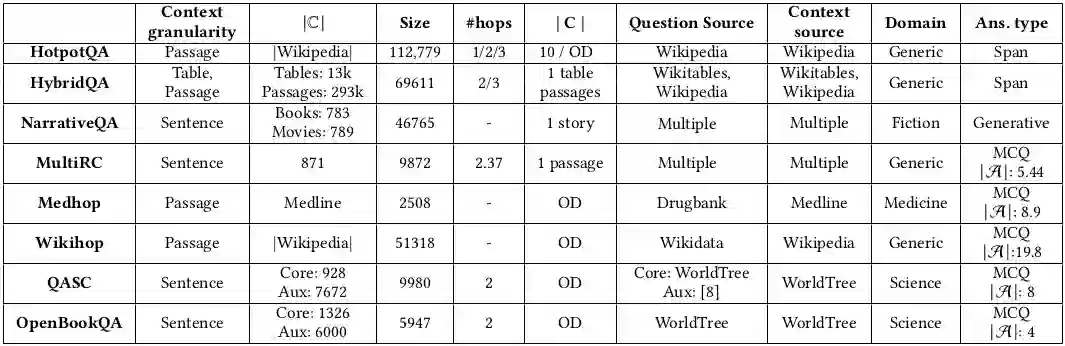
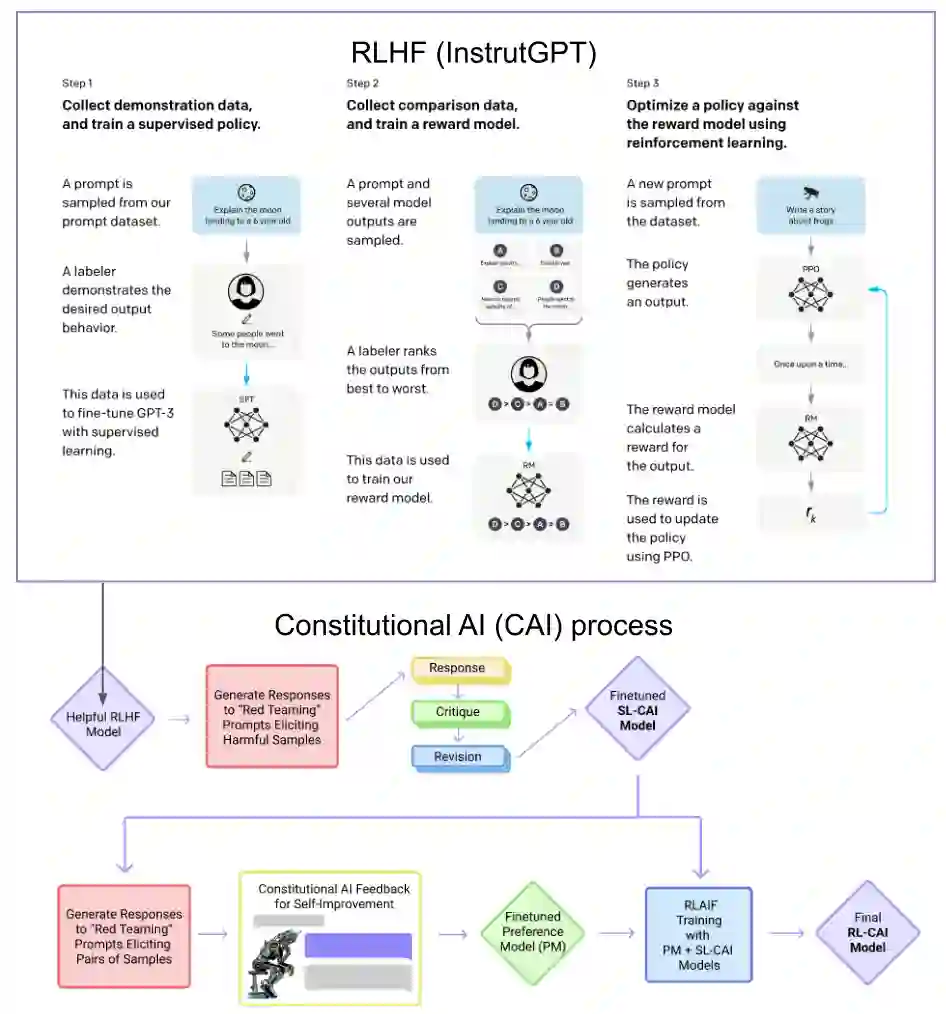
This paper reviews the state-of-the-art of hybrid language models architectures and strategies for "complex" question-answering (QA, CQA, CPS). Large Language Models (LLM) are good at leveraging public data on standard problems but once you want to tackle more specific complex questions or problems you may need specific architecture, knowledge, skills, methods, sensitive data protection, explainability, human approval and versatile feedback... We identify key elements augmenting LLM to solve complex questions or problems. We extend findings from the robust community edited research papers BIG, BLOOM and HELM which open source, benchmark and analyze limits and challenges of LLM in terms of tasks complexity and strict evaluation on accuracy (e.g. fairness, robustness, toxicity, ...). Recent projects like ChatGPT and GALACTICA have allowed non-specialists to grasp the great potential as well as the equally strong limitations of language models in complex QA. Hybridizing these models with different components could allow to overcome these different limits and go much further. We discuss some challenges associated with complex QA, including domain adaptation, decomposition and efficient multi-step QA, long form and non-factoid QA, safety and multi-sensitivity data protection, multimodal search, hallucinations, explainability and truthfulness, temproal reasoning. Therefore, we analyze current solutions and promising research trends, using elements such as: hybrid LLM architectures, active human reinforcement learning supervised with AI, prompting adaptation, neuro-symbolic and structured knowledge grounding, program synthesis, iterated decomposition and others.
翻译:本文综述了面向"复杂"问答任务(QA、CQA、CPS)的混合语言模型架构与策略的当前发展水平。大型语言模型(LLM)在利用标准问题的公开数据方面表现优异,但当需要处理更具体的复杂问题或难题时,往往需要特定的架构、知识、技能、方法、敏感数据保护、可解释性、人工审批及多样化反馈机制。我们识别出增强LLM解决复杂问题能力的关键要素,并基于开源社区编辑的研究论文BIG、BLOOM及HELM的成果进行延伸——这些工作通过开源、基准测试与严格评估(如公平性、鲁棒性、毒性等维度),深入分析了LLM在任务复杂性和准确性方面的局限与挑战。近期项目如ChatGPT与GALACTICA已让非专业人士感受到语言模型在复杂问答中的巨大潜力,同时也清晰揭示了其显著局限性。通过将不同组件与这些模型进行混合,有望突破既有限制并实现更深远突破。我们探讨了复杂问答面临的多项挑战,包括领域适应、任务分解与高效多步推理、长文本与非事实型问答、安全与多敏感度数据保护、多模态检索、幻觉、可解释性与真实性,以及时序推理。为此,本文系统分析了当前解决方案与有前景的研究趋势,涉及混合LLM架构、AI监督下的人机主动强化学习、提示适配、神经符号化与结构化知识融合、程序合成、迭代分解等关键技术要素。