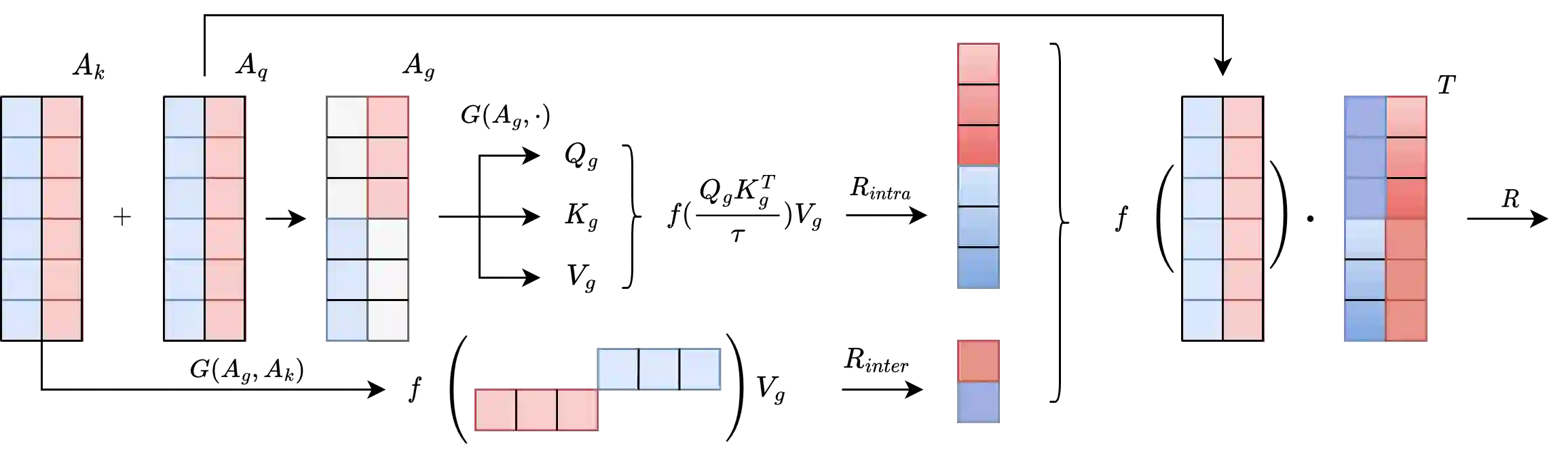
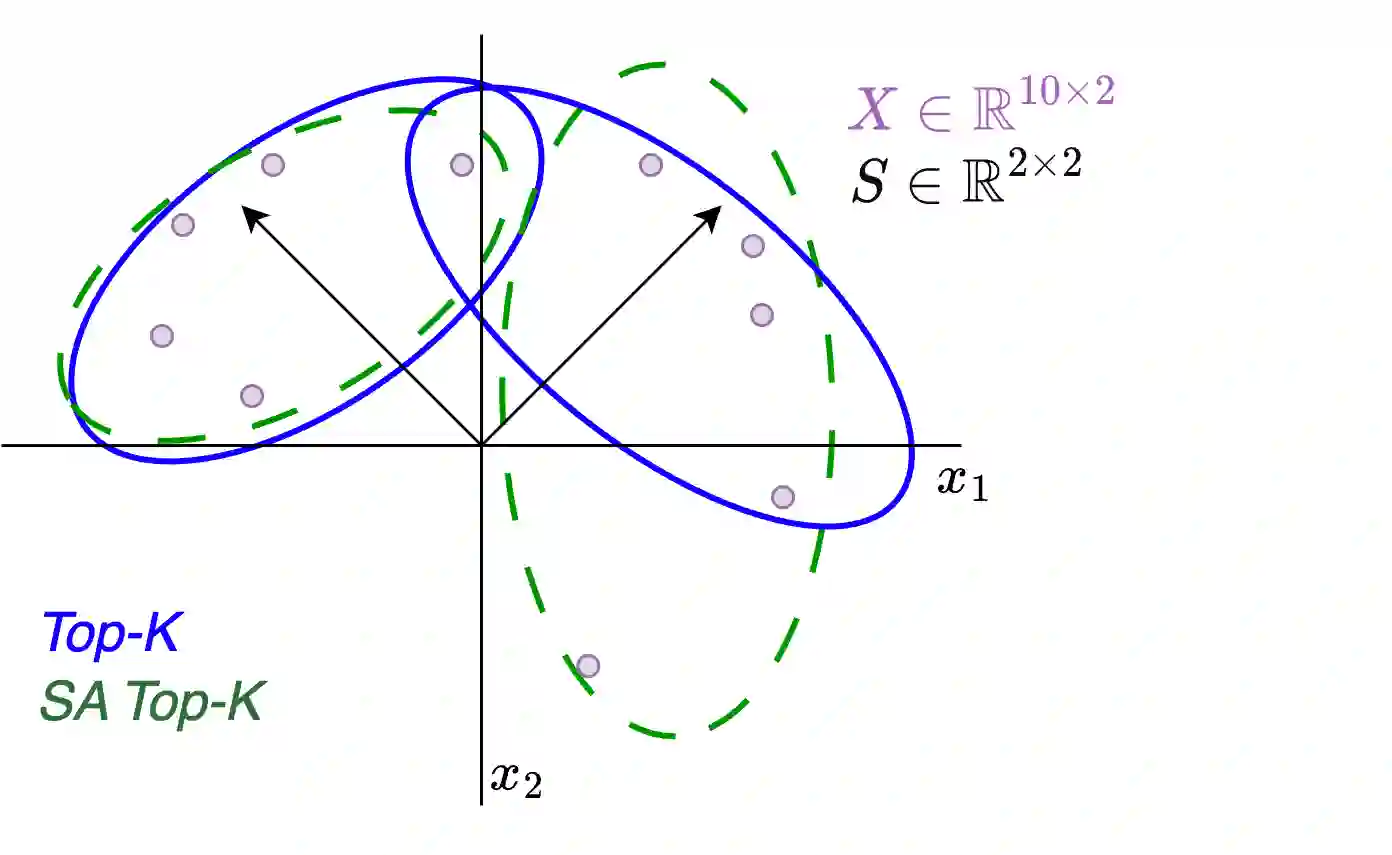
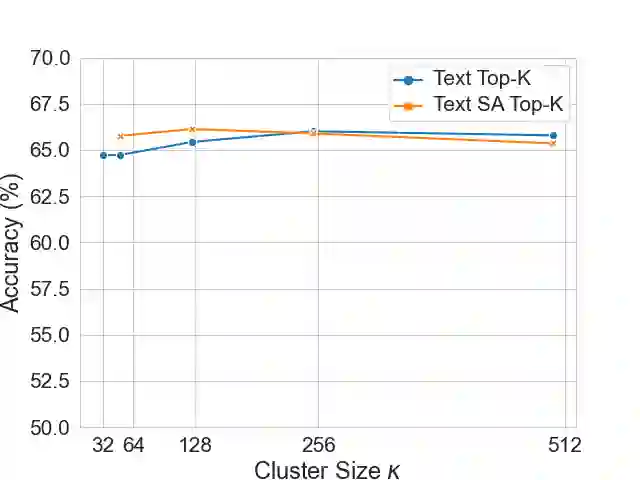
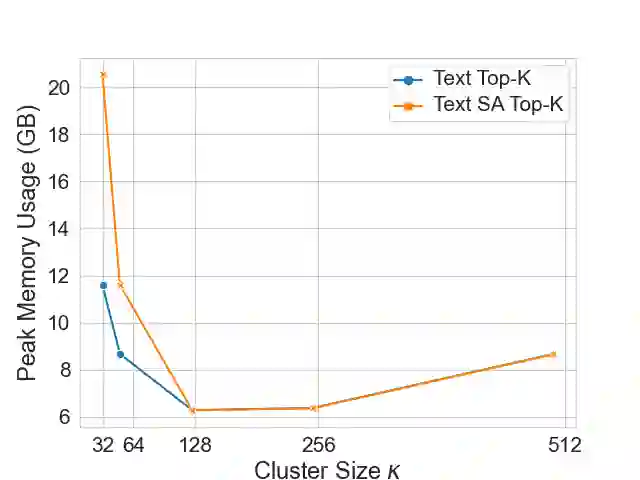
The Transformer architecture has shown to be a powerful tool for a wide range of tasks. It is based on the self-attention mechanism, which is an inherently computationally expensive operation with quadratic computational complexity: memory usage and compute time increase quadratically with the length of the input sequences, thus limiting the application of Transformers. In this work, we propose a novel Clustering self-Attention mechanism using Surrogate Tokens (CAST), to optimize the attention computation and achieve efficient transformers. CAST utilizes learnable surrogate tokens to construct a cluster affinity matrix, used to cluster the input sequence and generate novel cluster summaries. The self-attention from within each cluster is then combined with the cluster summaries of other clusters, enabling information flow across the entire input sequence. CAST improves efficiency by reducing the complexity from $O(N^2)$ to $O(\alpha N)$ where N is the sequence length, and {\alpha} is constant according to the number of clusters and samples per cluster. We show that CAST performs better than or comparable to the baseline Transformers on long-range sequence modeling tasks, while also achieving higher results on time and memory efficiency than other efficient transformers.
翻译:Transformer架构已被证明是处理广泛任务的有力工具。其核心基于自注意力机制,但该机制天然存在二次计算复杂度的瓶颈:内存占用和计算时间随输入序列长度呈二次方增长,从而限制了Transformer的应用。本文提出一种创新的基于代理令牌的聚类自注意力机制(CAST),通过优化注意力计算实现高效Transformer。CAST利用可学习的代理令牌构建聚类亲和度矩阵,对输入序列进行聚类并生成新型聚类摘要。每个聚类内部的自注意力结果与其他聚类的摘要信息进行融合,实现跨整个输入序列的信息流动。该机制将计算复杂度从$O(N^2)$降至$O(\alpha N)$(其中N为序列长度,$\alpha$为由聚类数量和每聚类样本数决定的常数)。实验表明,在长序列建模任务中,CAST的性能优于或持平于基准Transformer,同时在时间和内存效率方面均超越其他高效Transformer。