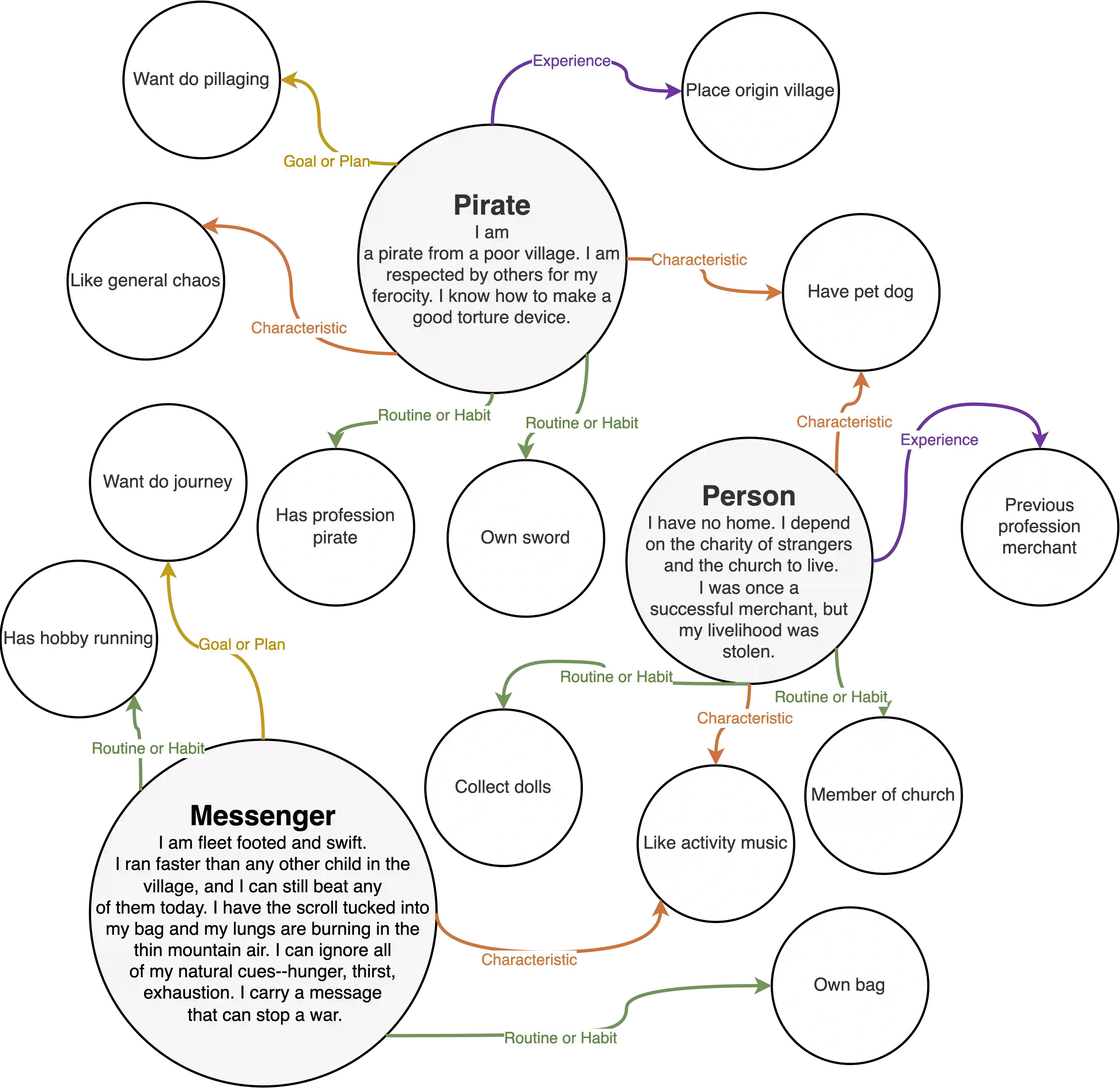
While valuable datasets such as PersonaChat provide a foundation for training persona-grounded dialogue agents, they lack diversity in conversational and narrative settings, primarily existing in the "real" world. To develop dialogue agents with unique personas, models are trained to converse given a specific persona, but hand-crafting these persona can be time-consuming, thus methods exist to automatically extract persona information from existing character-specific dialogue. However, these persona-extraction models are also trained on datasets derived from PersonaChat and struggle to provide high-quality persona information from conversational settings that do not take place in the real world, such as the fantasy-focused dataset, LIGHT. Creating new data to train models on a specific setting is human-intensive, thus prohibitively expensive. To address both these issues, we introduce a natural language inference method for post-hoc adapting a trained persona extraction model to a new setting. We draw inspiration from the literature of dialog natural language inference (NLI), and devise NLI-reranking methods to extract structured persona information from dialogue. Compared to existing persona extraction models, our method returns higher-quality extracted persona and requires less human annotation.
翻译:尽管诸如PersonaChat之类的宝贵数据集为训练基于人物角色的对话代理提供了基础,但它们在对话和叙事场景上缺乏多样性,主要局限于“现实”世界。为了开发具有独特人物角色的对话代理,模型需针对特定角色进行对话训练,但手工构建这些角色可能耗时费力,因此存在从现有角色特定对话中自动提取人物角色信息的方法。然而,这些角色提取模型也是在源自PersonaChat的数据集上训练的,难以从非现实世界的对话场景(如专注于奇幻的LIGHT数据集)中提供高质量的人物角色信息。为特定场景创建新数据来训练模型需要大量人力,成本过高。为解决这两个问题,我们提出了一种自然语言推理方法,用于事后调整训练好的角色提取模型以适应新场景。我们从对话自然语言推理(NLI)文献中汲取灵感,设计了NLI重排序方法,从对话中提取结构化的人物角色信息。与现有的角色提取模型相比,我们的方法能返回更高质量的提取结果,且所需的人工标注更少。