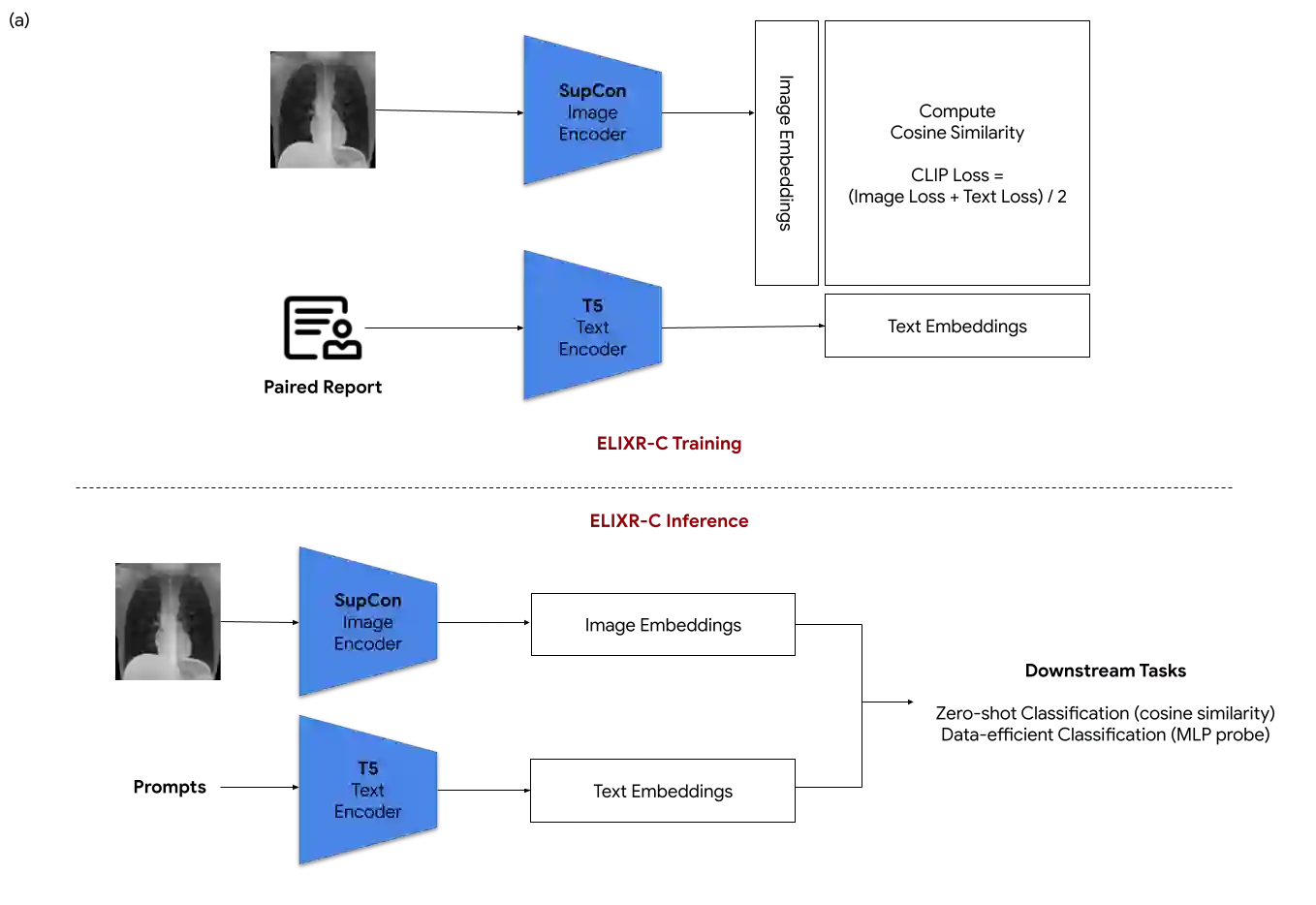
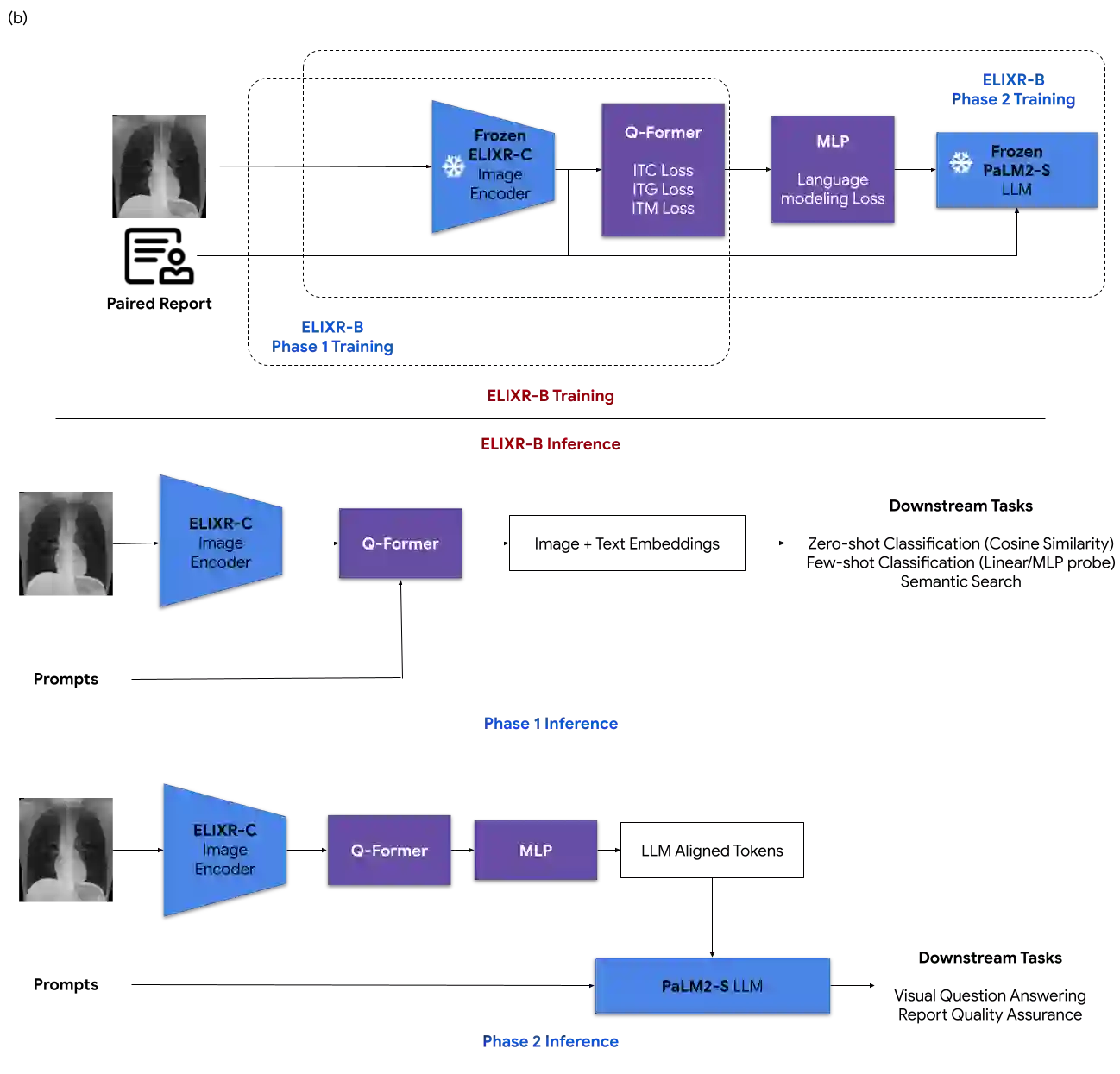
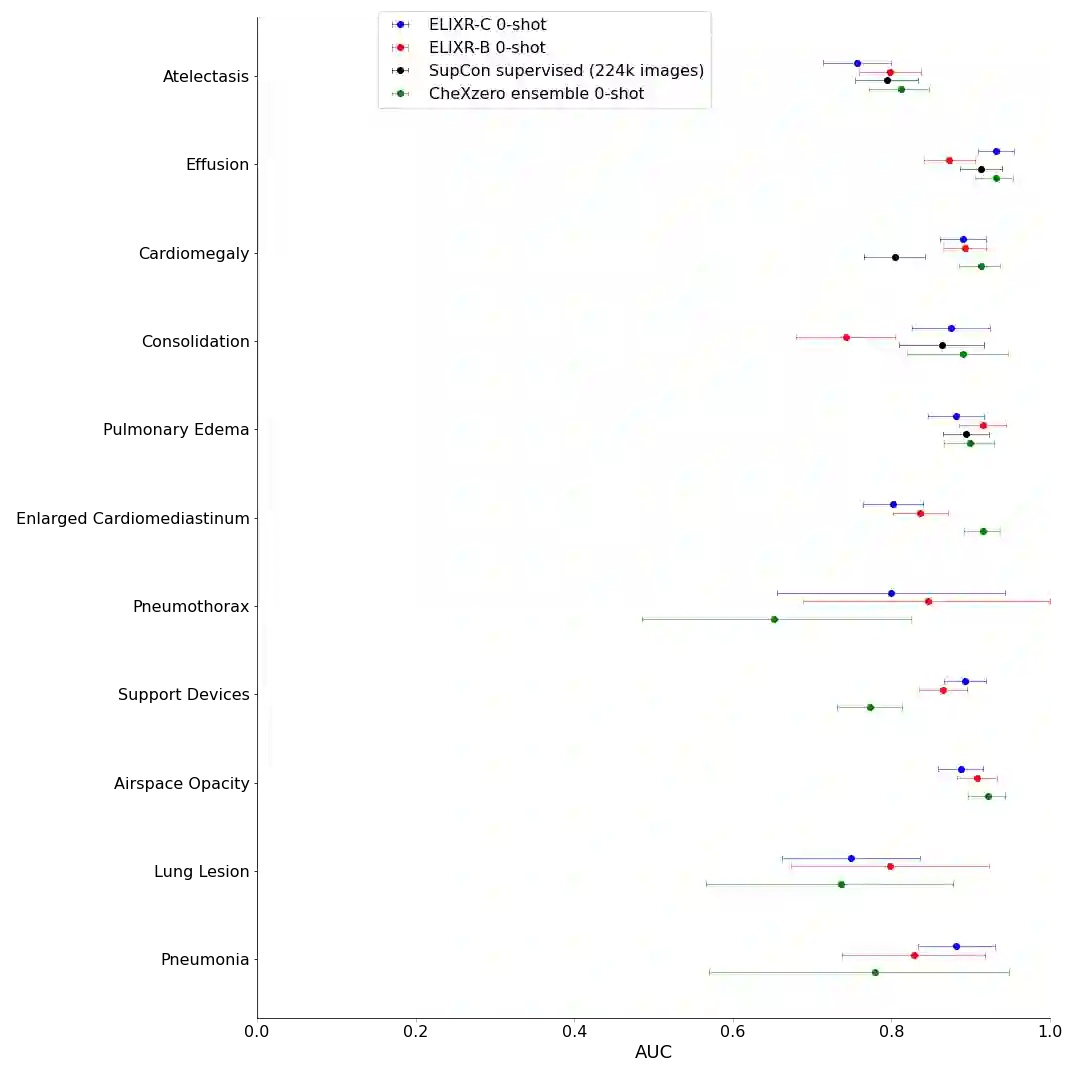
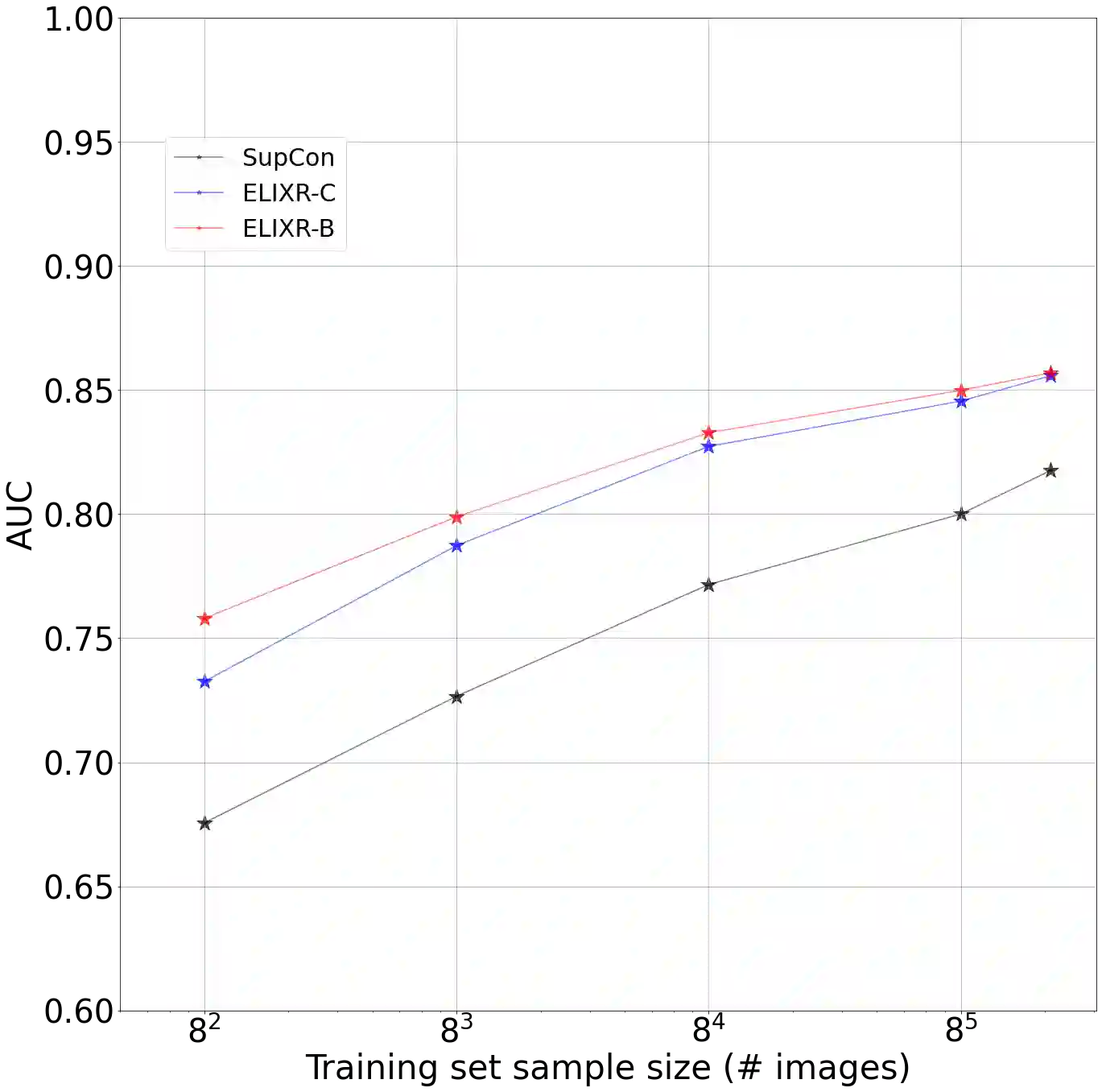
Our approach, which we call Embeddings for Language/Image-aligned X-Rays, or ELIXR, leverages a language-aligned image encoder combined or grafted onto a fixed LLM, PaLM 2, to perform a broad range of tasks. We train this lightweight adapter architecture using images paired with corresponding free-text radiology reports from the MIMIC-CXR dataset. ELIXR achieved state-of-the-art performance on zero-shot chest X-ray (CXR) classification (mean AUC of 0.850 across 13 findings), data-efficient CXR classification (mean AUCs of 0.893 and 0.898 across five findings (atelectasis, cardiomegaly, consolidation, pleural effusion, and pulmonary edema) for 1% (~2,200 images) and 10% (~22,000 images) training data), and semantic search (0.76 normalized discounted cumulative gain (NDCG) across nineteen queries, including perfect retrieval on twelve of them). Compared to existing data-efficient methods including supervised contrastive learning (SupCon), ELIXR required two orders of magnitude less data to reach similar performance. ELIXR also showed promise on CXR vision-language tasks, demonstrating overall accuracies of 58.7% and 62.5% on visual question answering and report quality assurance tasks, respectively. These results suggest that ELIXR is a robust and versatile approach to CXR AI.
翻译:我们的方法称为面向语言/图像对齐X射线的嵌入系统(ELIXR),通过将语言对齐的图像编码器与固定的大语言模型PaLM 2进行融合或嫁接,以执行广泛的任务。我们利用MIMIC-CXR数据集中配对图像及其对应的自由文本放射学报告来训练这一轻量级适配器架构。ELIXR在零样本胸部X射线(CXR)分类(13项发现平均AUC为0.850)、数据高效CXR分类(针对肺不张、心脏肥大、实变、胸腔积液和肺水肿五项发现,使用1%(约2200张图像)和10%(约22000张图像)训练数据时平均AUC分别达到0.893和0.898)以及语义搜索(19项查询中归一化折损累积增益(NDCG)为0.76,其中12项实现完美检索)方面均取得了最先进性能。与包括监督对比学习(SupCon)在内的现有数据高效方法相比,ELIXR达到相似性能所需的数据量低两个数量级。此外,ELIXR在CXR视觉语言任务中展现出潜力,在视觉问答和报告质量保证任务上的总体准确率分别为58.7%和62.5%。这些结果表明ELIXR是一种稳健且通用的CXR人工智能方法。