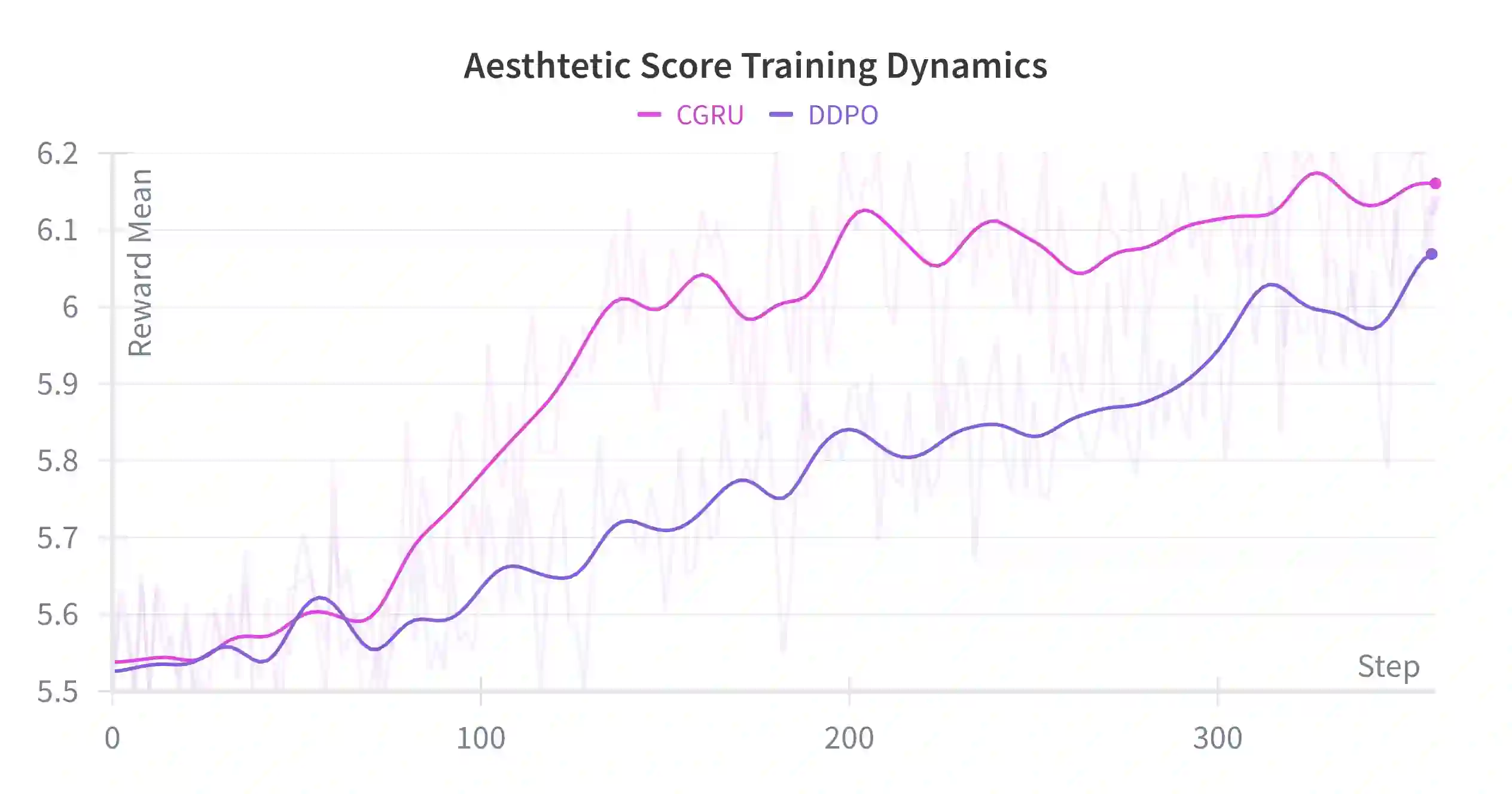
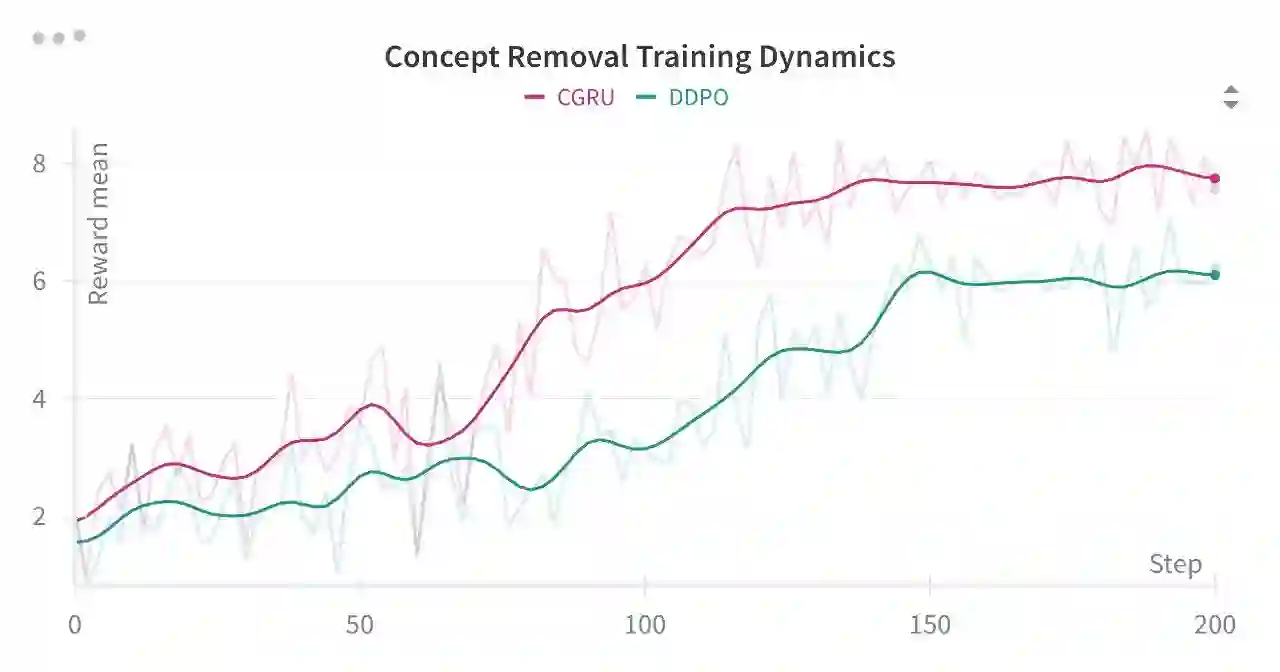
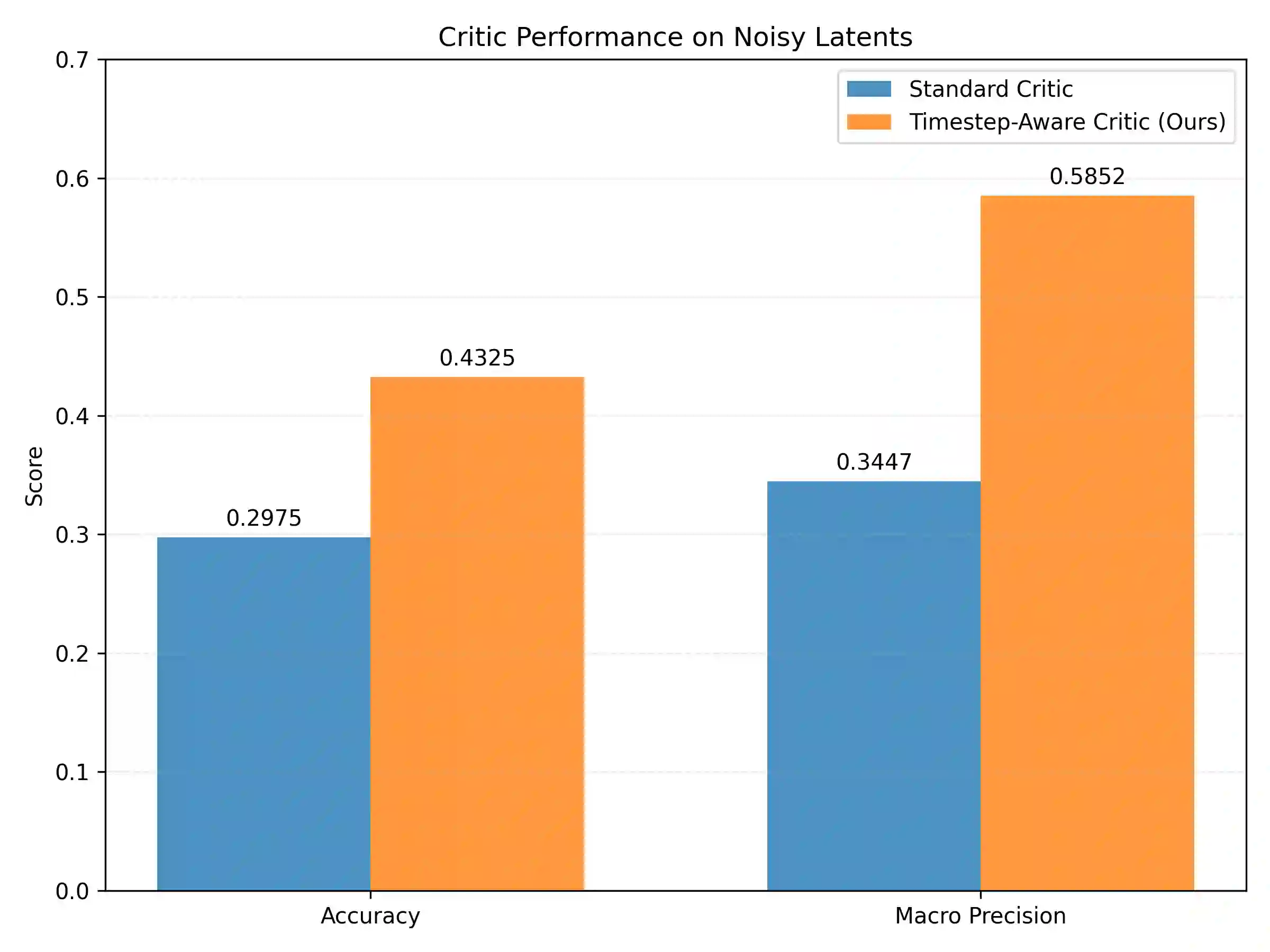
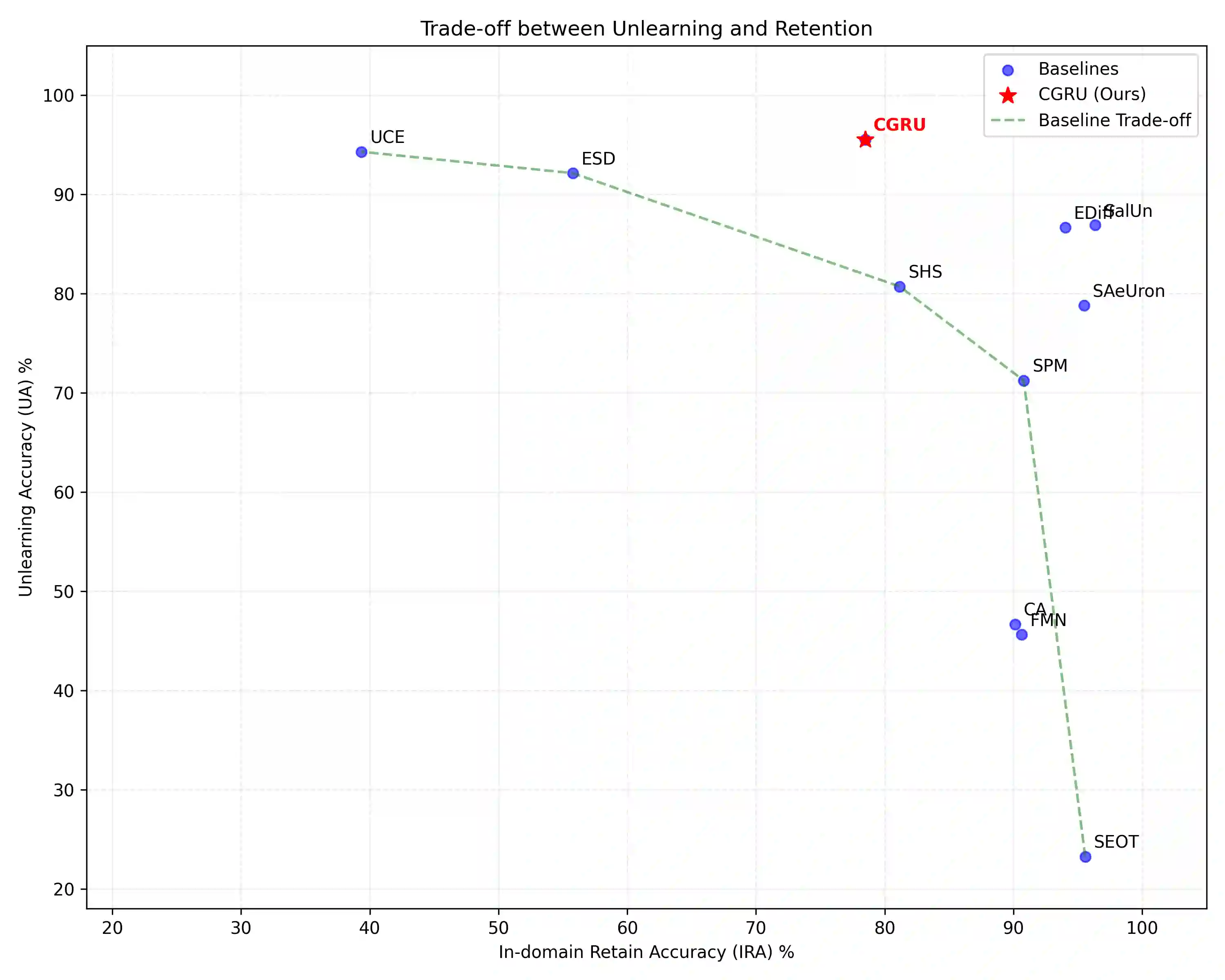
Machine unlearning in text-to-image diffusion models aims to remove targeted concepts while preserving overall utility. Prior diffusion unlearning methods typically rely on supervised weight edits or global penalties; reinforcement-learning (RL) approaches, while flexible, often optimize sparse end-of-trajectory rewards, yielding high-variance updates and weak credit assignment. We present a general RL framework for diffusion unlearning that treats denoising as a sequential decision process and introduces a timestep-aware critic with noisy-step rewards. Concretely, we train a CLIP-based reward predictor on noisy latents and use its per-step signal to compute advantage estimates for policy-gradient updates of the reverse diffusion kernel. Our algorithm is simple to implement, supports off-policy reuse, and plugs into standard text-to-image backbones. Across multiple concepts, the method achieves better or comparable forgetting to strong baselines while maintaining image quality and benign prompt fidelity; ablations show that (i) per-step critics and (ii) noisy-conditioned rewards are key to stability and effectiveness. We release code and evaluation scripts to facilitate reproducibility and future research on RL-based diffusion unlearning.
翻译:文本到图像扩散模型的机器遗忘旨在移除特定概念的同时保持模型整体效用。现有扩散遗忘方法通常依赖于监督式权重编辑或全局惩罚;强化学习方法虽具灵活性,但往往优化稀疏的轨迹末端奖励,导致高方差更新与弱信用分配。本文提出一种通用的扩散遗忘强化学习框架,将去噪过程视为序列决策问题,并引入具有噪声步奖励的时序感知评论家。具体而言,我们在噪声潜变量上训练基于CLIP的奖励预测器,利用其逐步信号计算优势估计值,以执行反向扩散核的策略梯度更新。该算法实现简单,支持离策略数据复用,并可嵌入标准文本到图像主干模型。在多种概念上的实验表明,本方法在保持图像质量与良性提示保真度的同时,实现了优于或可比拟强基线的遗忘效果;消融研究证实:(1)逐步评论家与(2)噪声条件奖励是算法稳定性与有效性的关键。我们公开了代码与评估脚本,以促进基于强化学习的扩散遗忘研究的可复现性与未来发展。