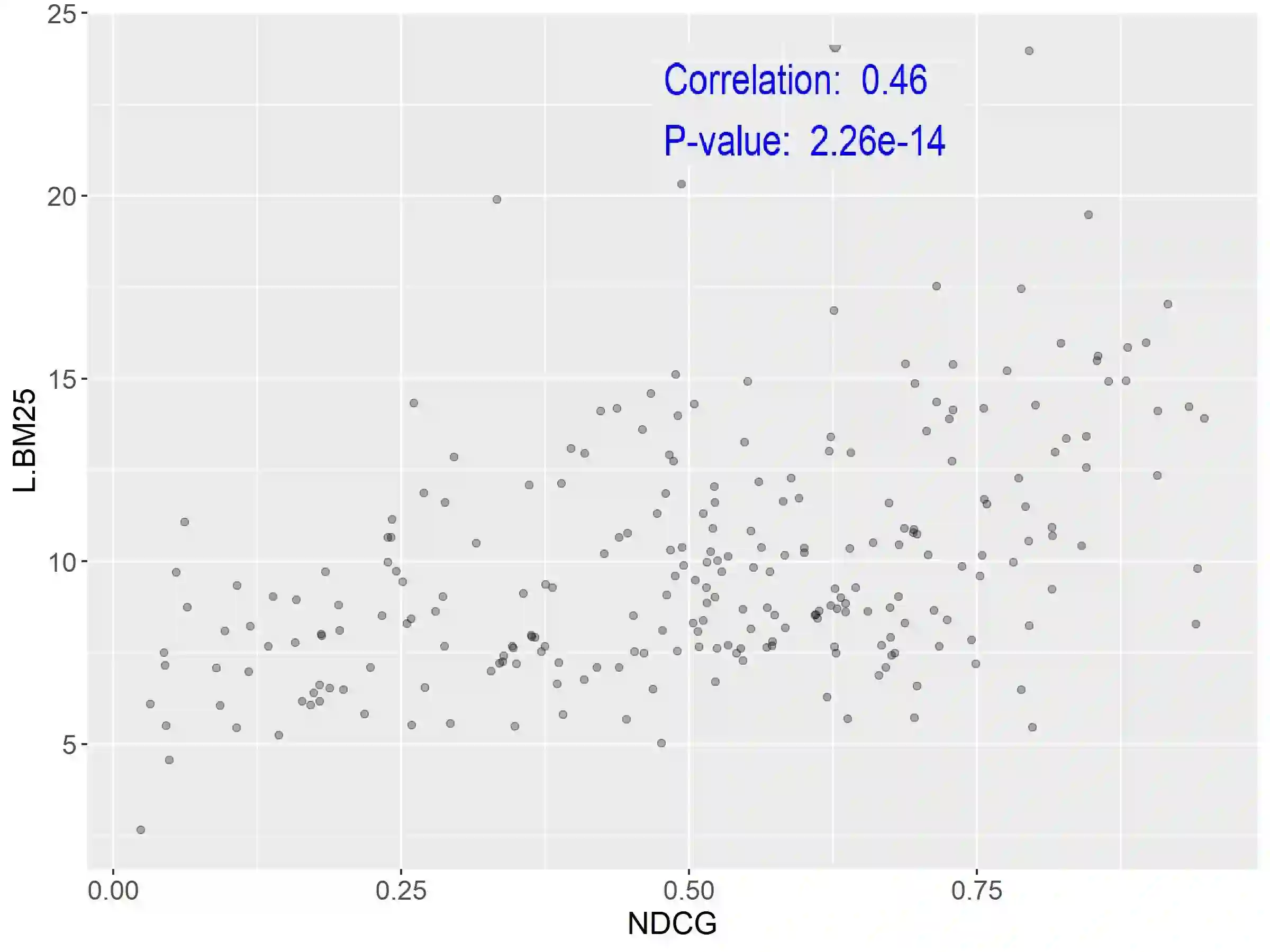
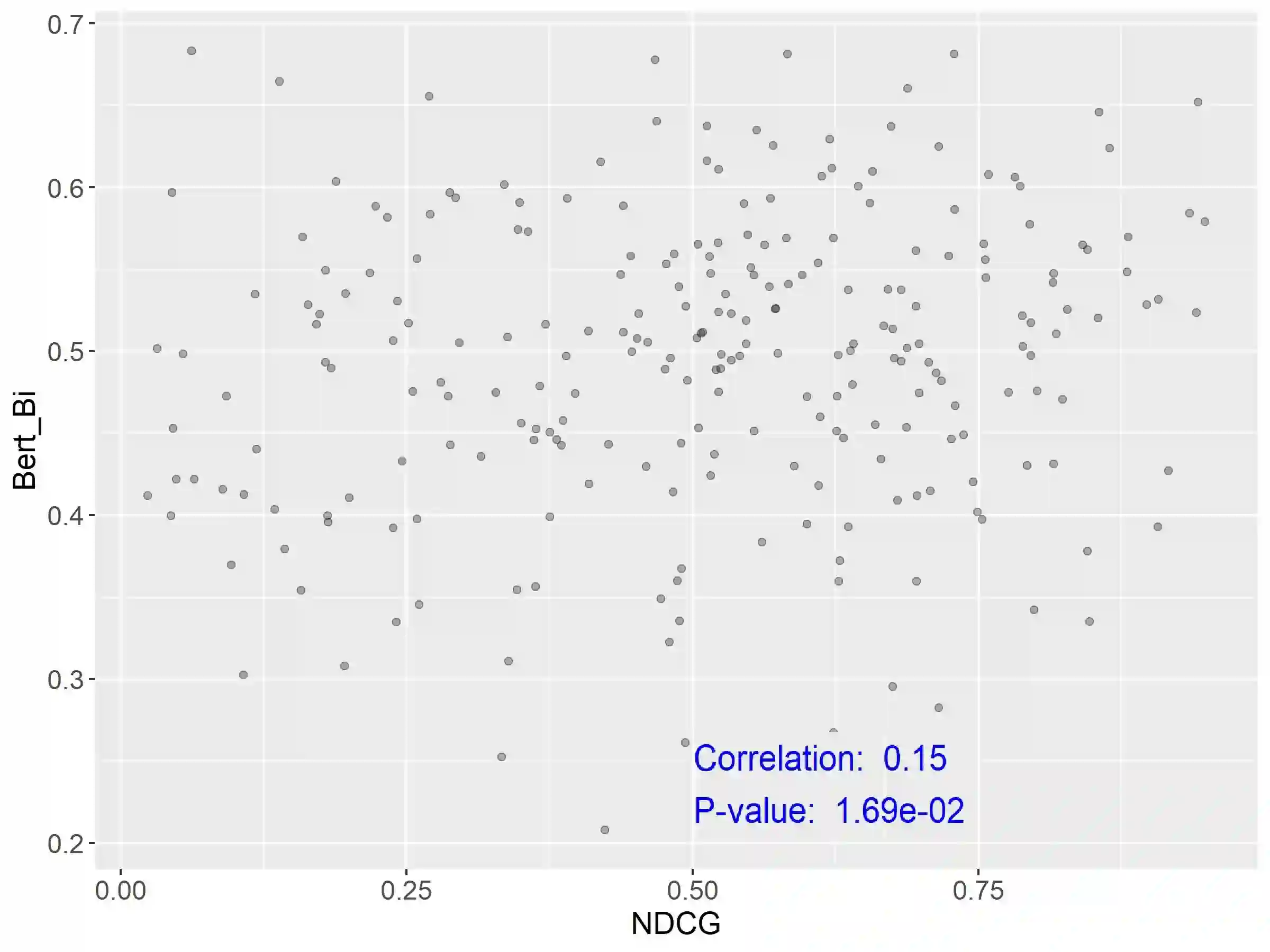
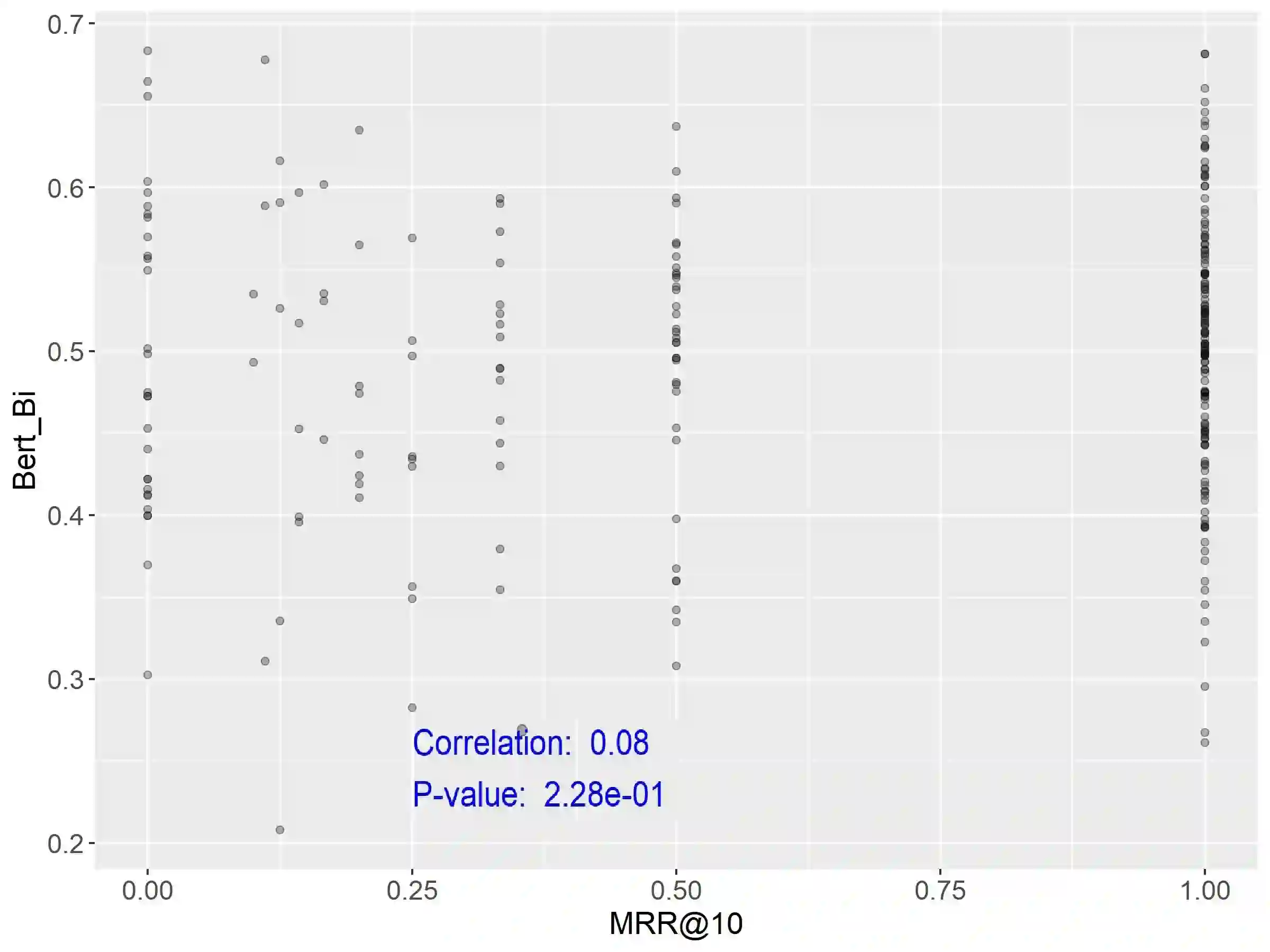
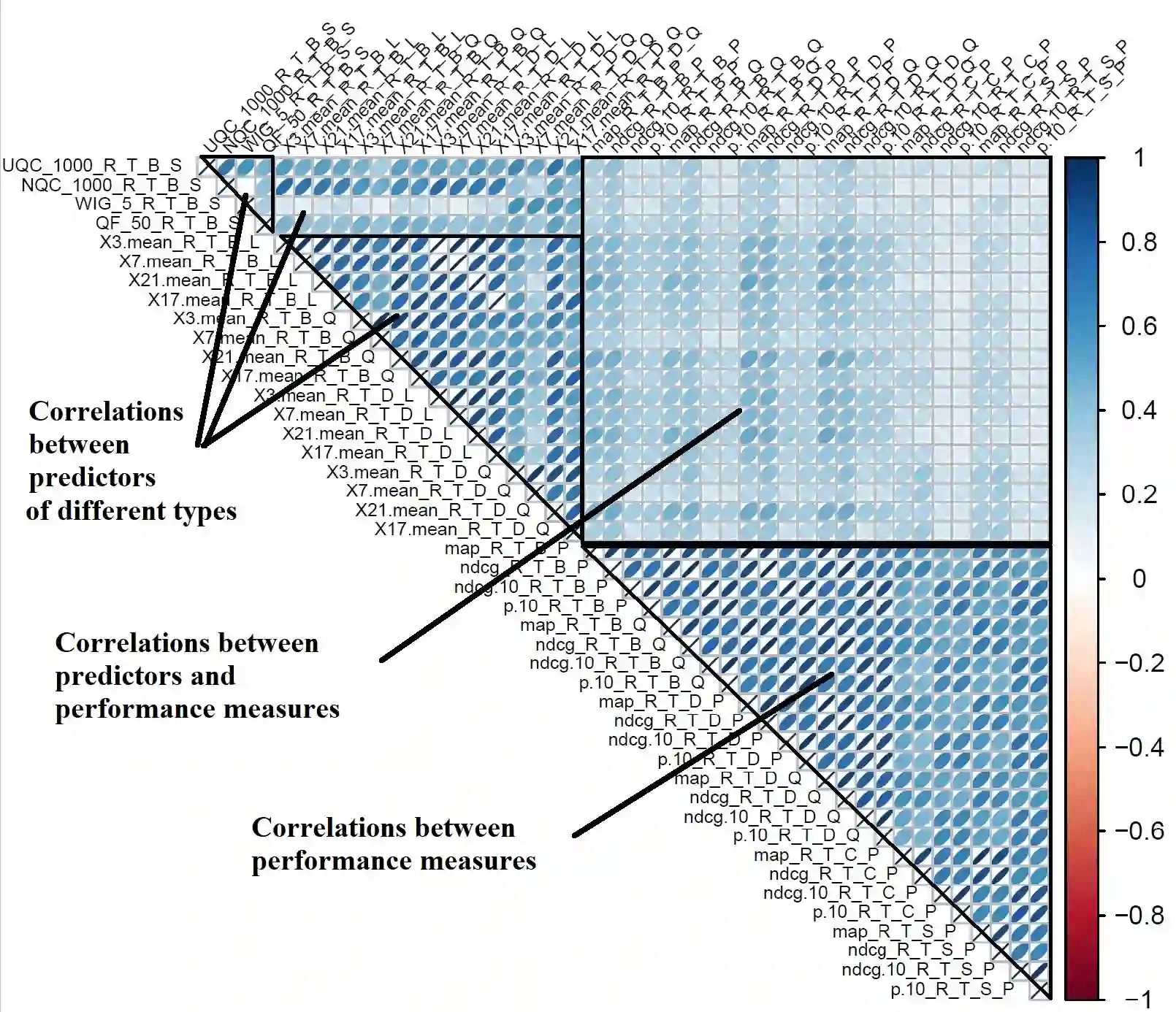
Query Performance Prediction (QPP) estimates retrieval systems effectiveness for a given query, offering valuable insights for search effectiveness and query processing. Despite extensive research, QPPs face critical challenges in generalizing across diverse retrieval paradigms and collections. This paper provides a comprehensive evaluation of state-of-the-art QPPs (e.g. NQC, UQC), LETOR-based features, and newly explored dense-based predictors. Using diverse sparse rankers (BM25, DFree without and with query expansion) and hybrid or dense (SPLADE and ColBert) rankers and diverse test collections ROBUST, GOV2, WT10G, and MS MARCO; we investigate the relationships between predicted and actual performance, with a focus on generalization and robustness. Results show significant variability in predictors accuracy, with collections as the main factor and rankers next. Some sparse predictors perform somehow on some collections (TREC ROBUST and GOV2) but do not generalise to other collections (WT10G and MS-MARCO). While some predictors show promise in specific scenarios, their overall limitations constrain their utility for applications. We show that QPP-driven selective query processing offers only marginal gains, emphasizing the need for improved predictors that generalize across collections, align with dense retrieval architectures and are useful for downstream applications.
翻译:查询性能预测旨在评估检索系统对给定查询的检索效果,为搜索效果和查询处理提供有价值的见解。尽管已有大量研究,但QPP在泛化到不同检索范式和数据集方面仍面临严峻挑战。本文对当前最先进的QPP方法(如NQC、UQC)、基于LETOR的特征以及新探索的基于稠密表示的预测器进行了全面评估。通过使用多种稀疏排序器(BM25、DFree及其查询扩展版本)、混合/稠密排序器(SPLADE和ColBert)以及多样化测试集(ROBUST、GOV2、WT10G和MS MARCO),我们研究了预测性能与实际性能之间的关系,重点关注泛化能力和鲁棒性。结果表明预测器准确率存在显著差异,其中数据集是主要影响因素,排序器次之。部分稀疏预测器在特定数据集(TREC ROBUST和GOV2)上表现尚可,但无法泛化到其他数据集(WT10G和MS-MARCO)。虽然某些预测器在特定场景中展现出潜力,但其整体局限性限制了实际应用价值。我们证明基于QPP的选择性查询处理仅能带来边际收益,这凸显了需要开发能够跨数据集泛化、适配稠密检索架构且对下游应用有效的改进型预测器。