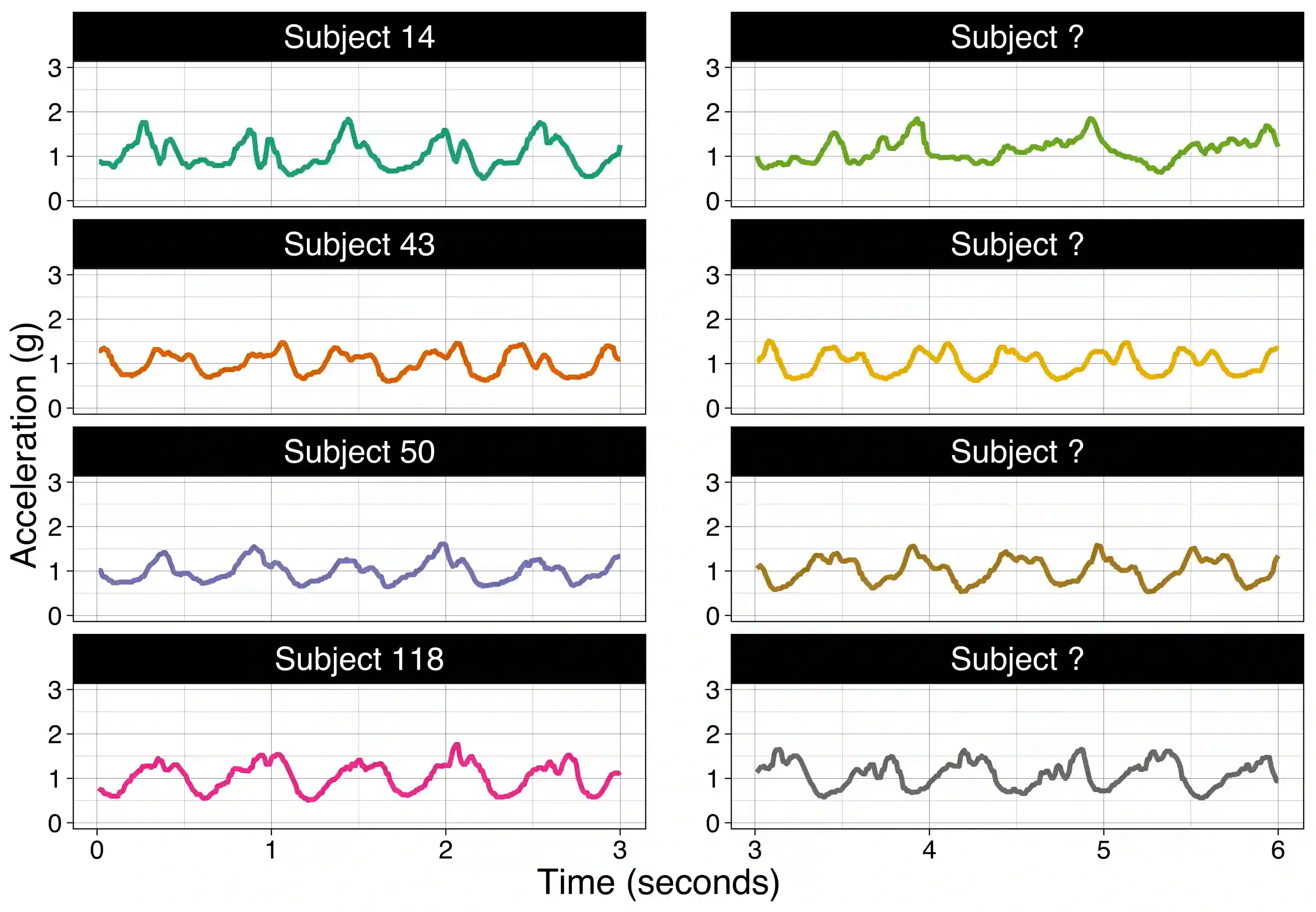
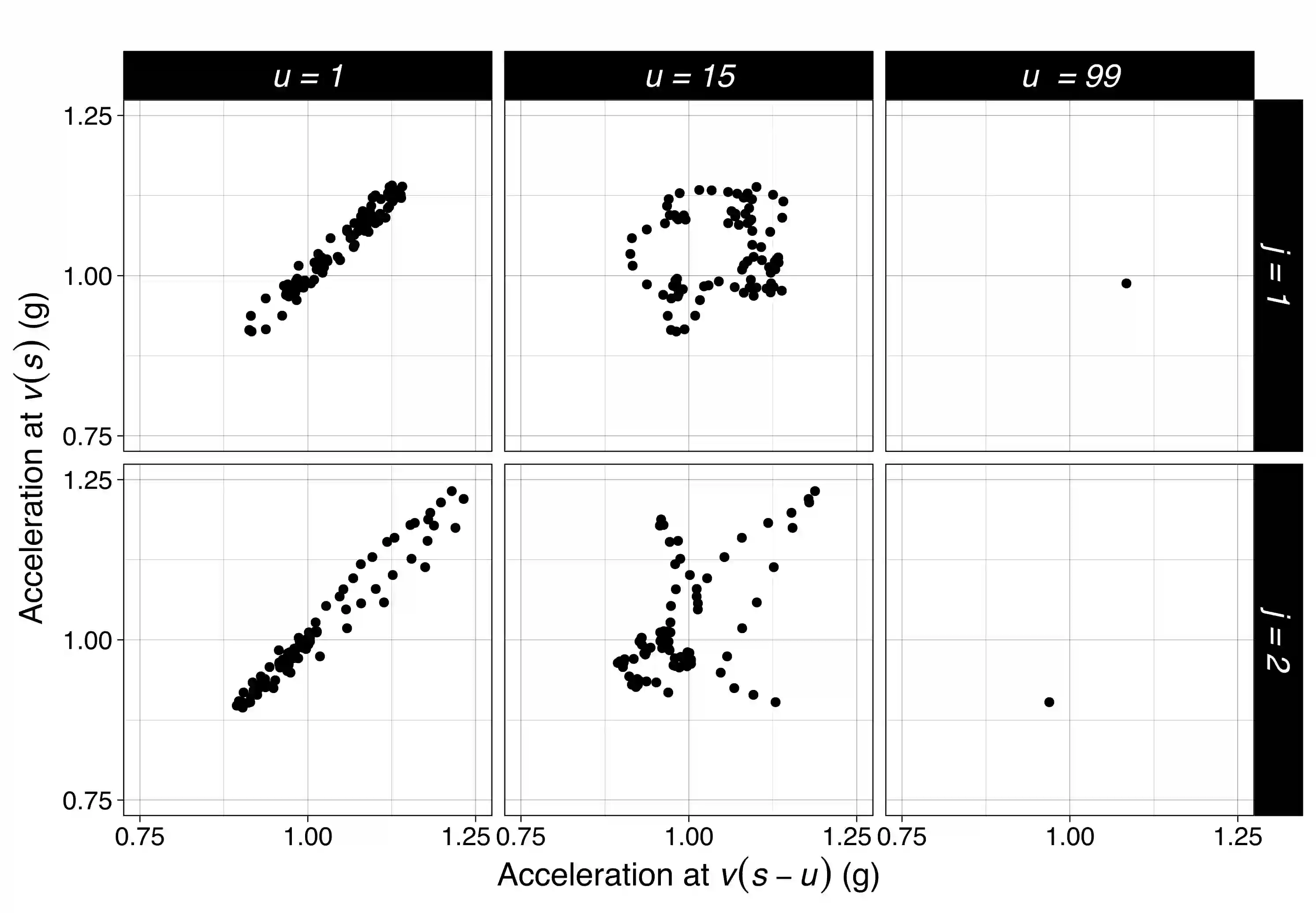
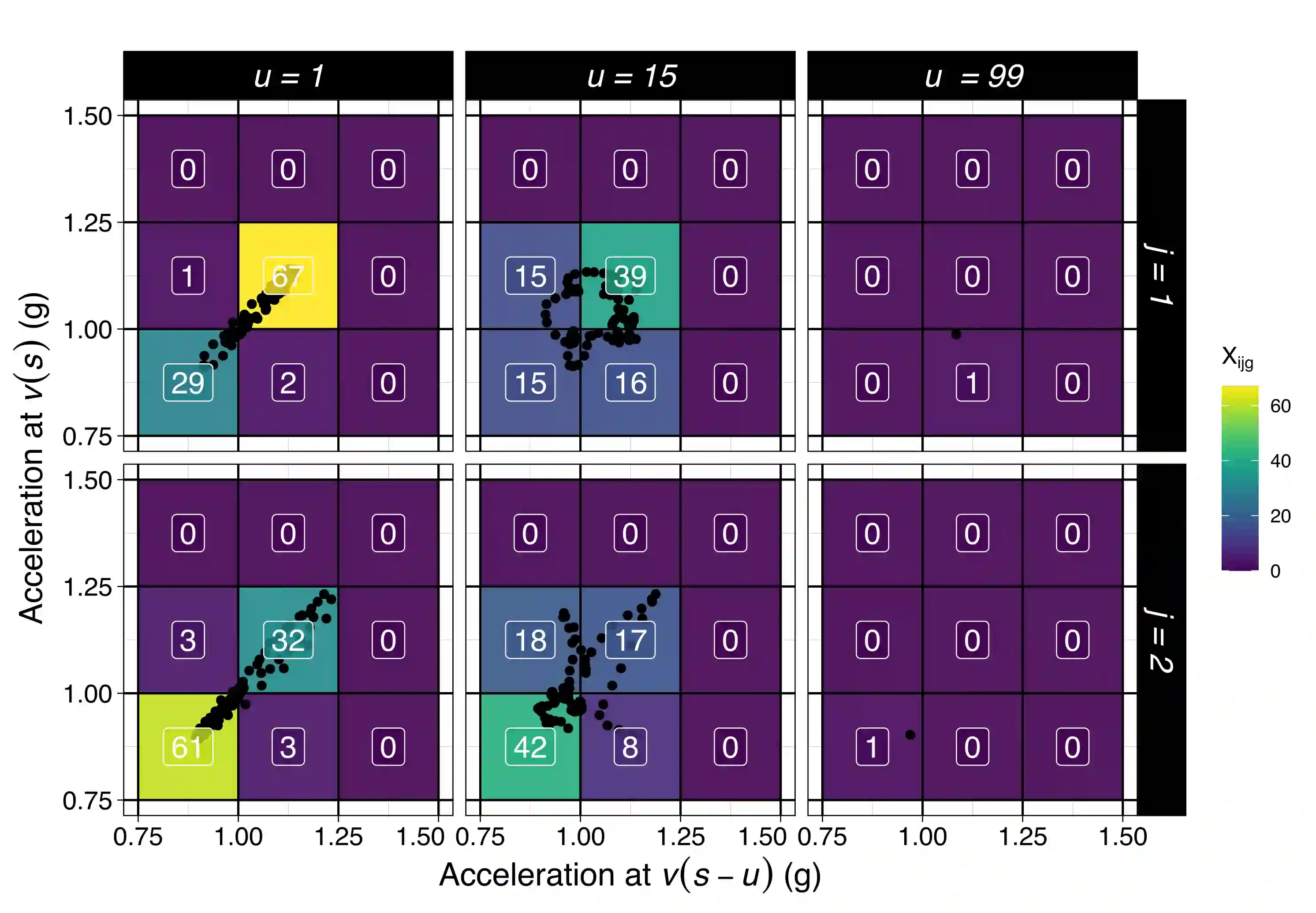
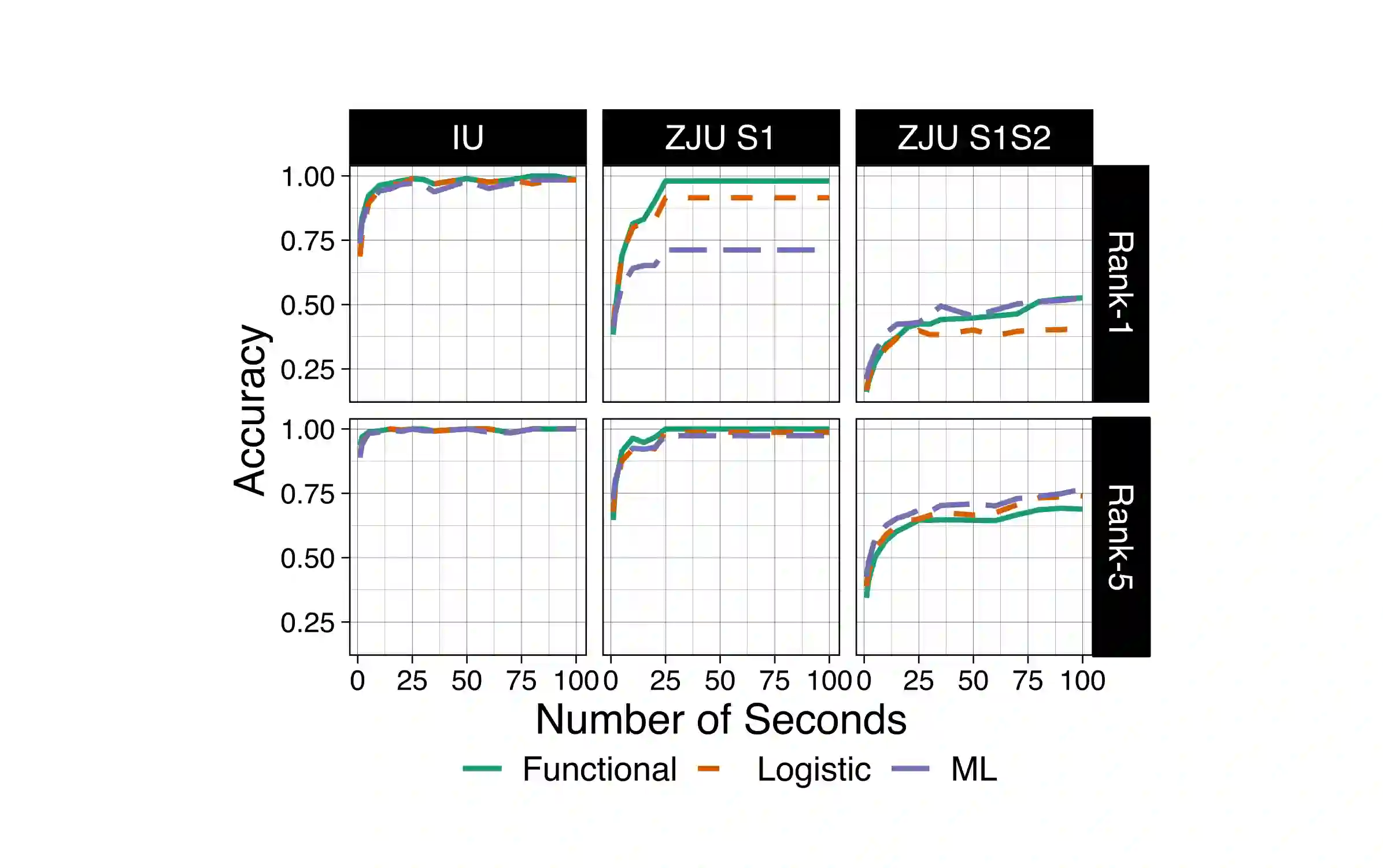
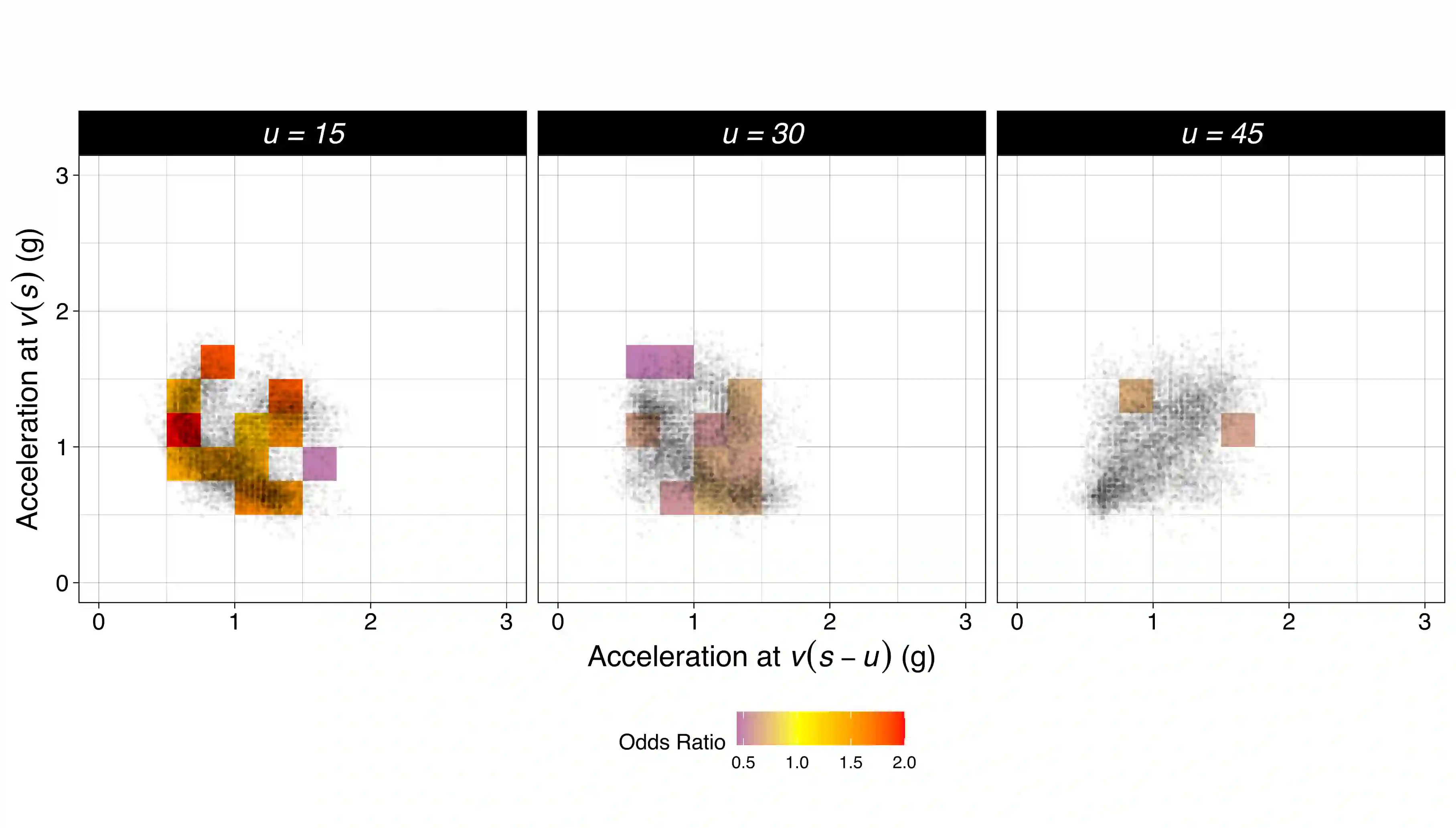
We consider the problem of predicting an individual's identity from accelerometry data collected during walking. In a previous paper we introduced an approach that transforms the accelerometry time series into an image by constructing its complete empirical autocorrelation distribution. Predictors derived by partitioning this image into grid cells were used in logistic regression to predict individuals. Here we: (1) implement machine learning methods for prediction using the grid cell-derived predictors; (2) derive inferential methods to screen for the most predictive grid cells; and (3) develop a novel multivariate functional regression model that avoids partitioning of the predictor space into cells. Prediction methods are compared on two open source data sets: (1) accelerometry data collected from $32$ individuals walking on a $1.06$ kilometer path; and (2) accelerometry data collected from six repetitions of walking on a $20$ meter path on two separate occasions at least one week apart for $153$ study participants. In the $32$-individual study, all methods achieve at least $95$% rank-1 accuracy, while in the $153$-individual study, accuracy varies from $41$% to $98$%, depending on the method and prediction task. Methods provide insights into why some individuals are easier to predict than others.
翻译:我们考虑从行走过程中收集的加速度计数据预测个体身份的问题。在前期研究中,我们提出了一种方法,通过构建加速度计时间序列的完整经验自相关分布,将其转化为图像。通过将该图像划分为网格单元得到的预测因子被用于逻辑回归以预测个体身份。本研究:(1)使用基于网格单元的预测因子,实现机器学习方法进行预测;(2)推导推断性方法以筛选最具预测性的网格单元;(3)开发了一种新颖的多变量泛函回归模型,避免了对预测变量空间进行分区。预测方法在两个开源数据集上进行了比较:(1)从32名个体在1.06公里路径上行走时收集的加速度计数据;(2)从153名研究参与者在至少相隔一周的两次测试中,每次在20米路径上重复行走六次收集的加速度计数据。在32名个体的研究中,所有方法均达到至少95%的排序首位准确率,而在153名个体的研究中,准确率因方法和预测任务而异,范围从41%到98%。这些方法揭示了为何某些个体比其他个体更易预测的原因。