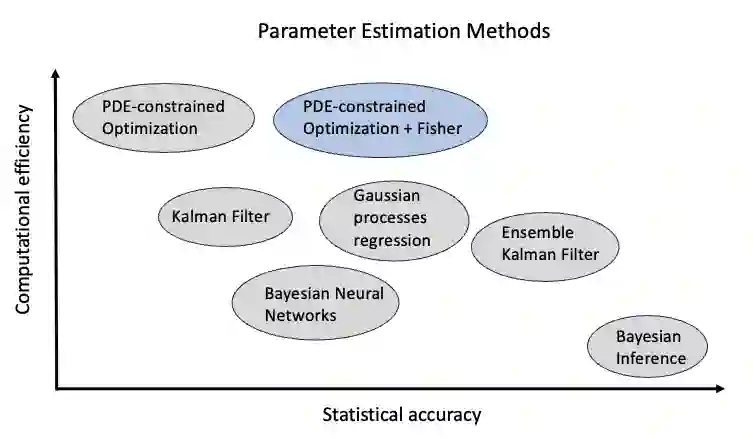
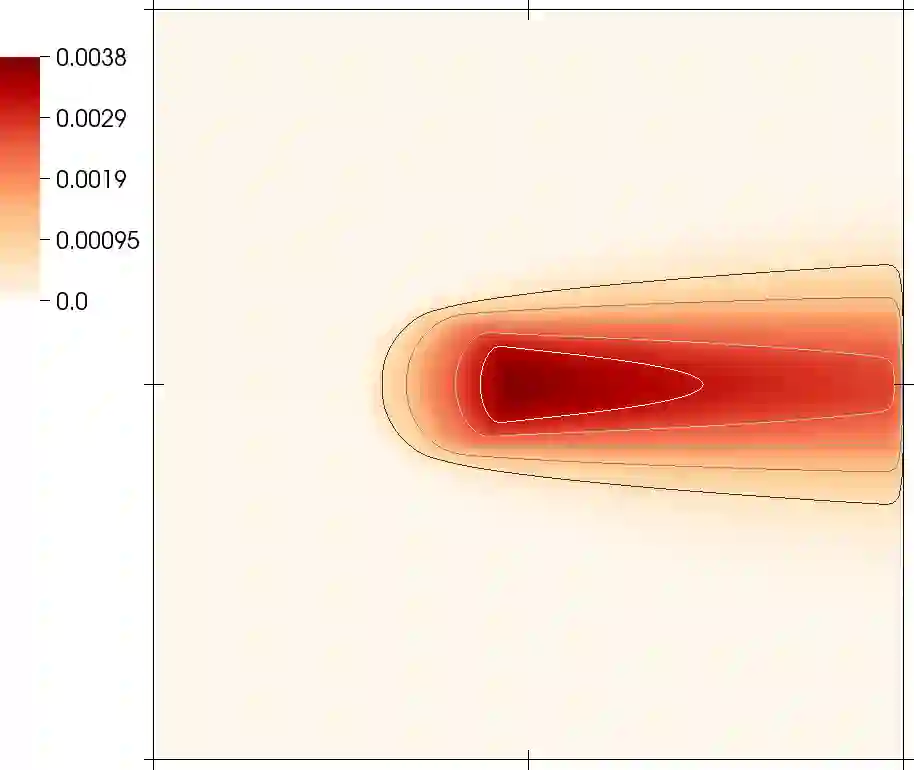
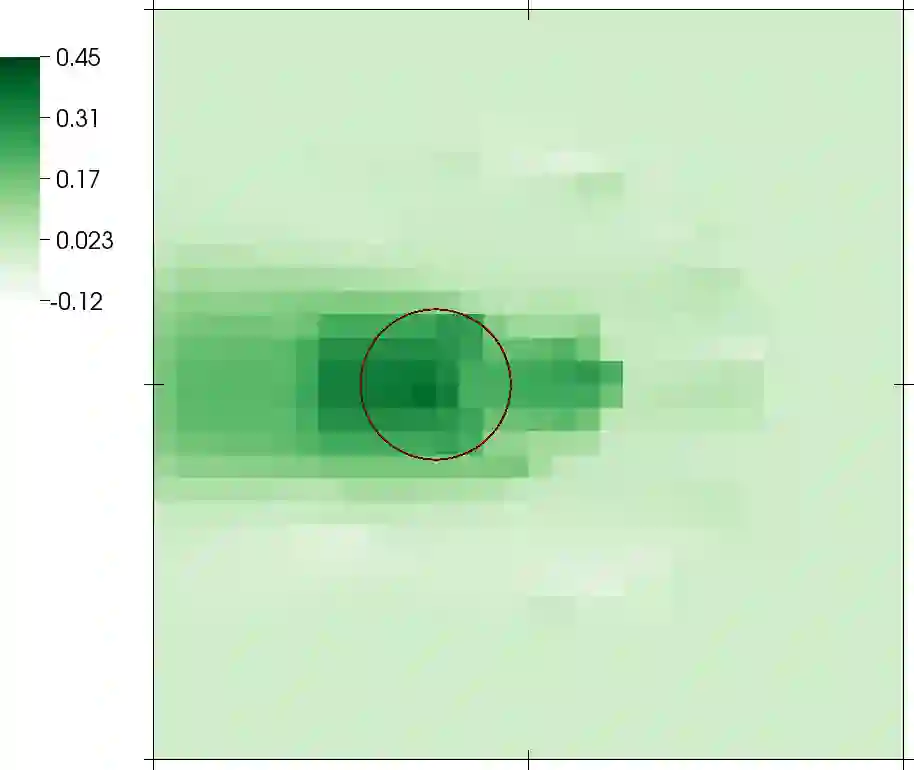
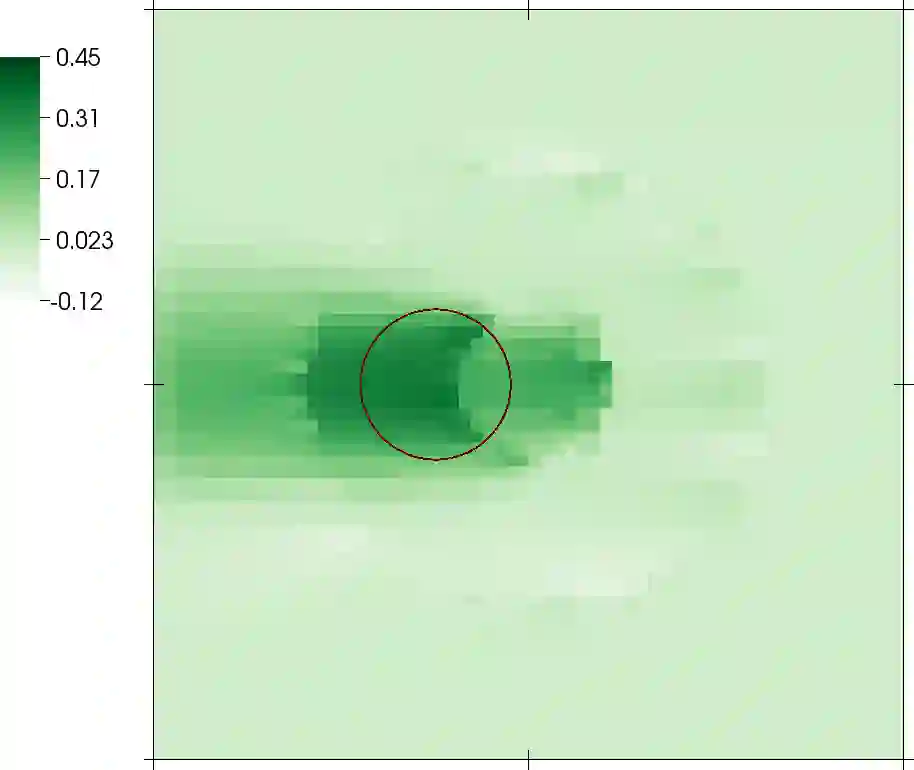
In inverse problems, one attempts to infer spatially variable functions from indirect measurements of a system. To practitioners of inverse problems, the concept of "information" is familiar when discussing key questions such as which parts of the function can be inferred accurately and which cannot. For example, it is generally understood that we can identify system parameters accurately only close to detectors, or along ray paths between sources and detectors, because we have "the most information" for these places. Although referenced in many publications, the "information" that is invoked in such contexts is not a well understood and clearly defined quantity. Herein, we present a definition of information density that is based on the variance of coefficients as derived from a Bayesian reformulation of the inverse problem. We then discuss three areas in which this information density can be useful in practical algorithms for the solution of inverse problems, and illustrate the usefulness in one of these areas -- how to choose the discretization mesh for the function to be reconstructed -- using numerical experiments.
翻译:在逆问题中,我们试图从对系统的间接测量中推断空间变化的函数。对于逆问题的研究者而言,在讨论哪些函数部分可以被精确推断、哪些无法被准确推断等关键问题时,“信息”这一概念并不陌生。例如,人们普遍认为只有靠近探测器、或沿源与探测器之间的射线路径才能准确识别系统参数,因为我们在这些区域拥有“最多信息”。尽管这一概念在多篇文献中被引用,但此类语境中提及的“信息”并非一个认知清晰且定义明确的量。本文基于逆问题的贝叶斯重构推导出的系数方差,提出了一种信息密度的定义。随后我们讨论了该信息密度在逆问题求解实用算法中三个可能的应用方向,并通过数值实验展示了其中一个方向的应用价值——如何选择待重构函数的离散化网格。