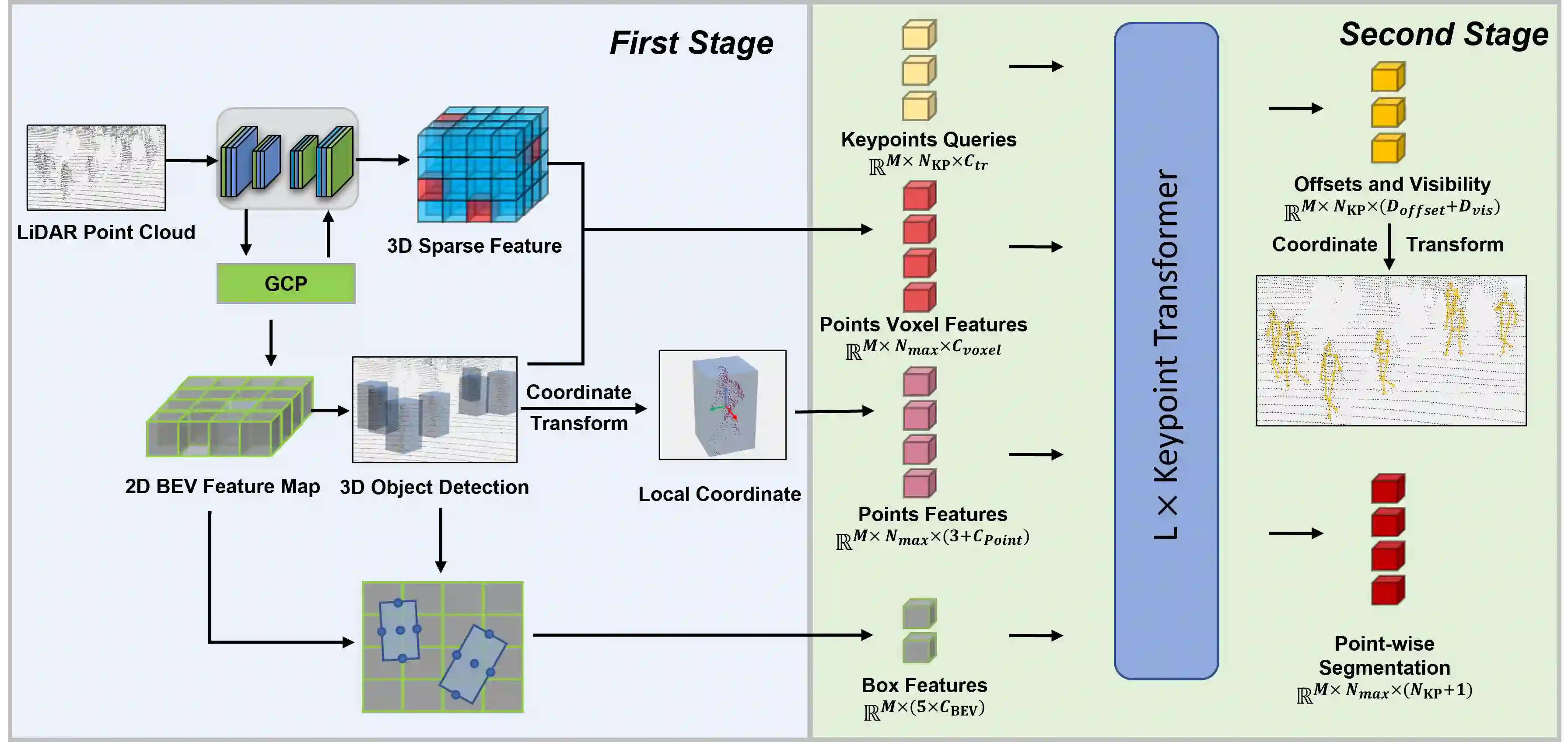
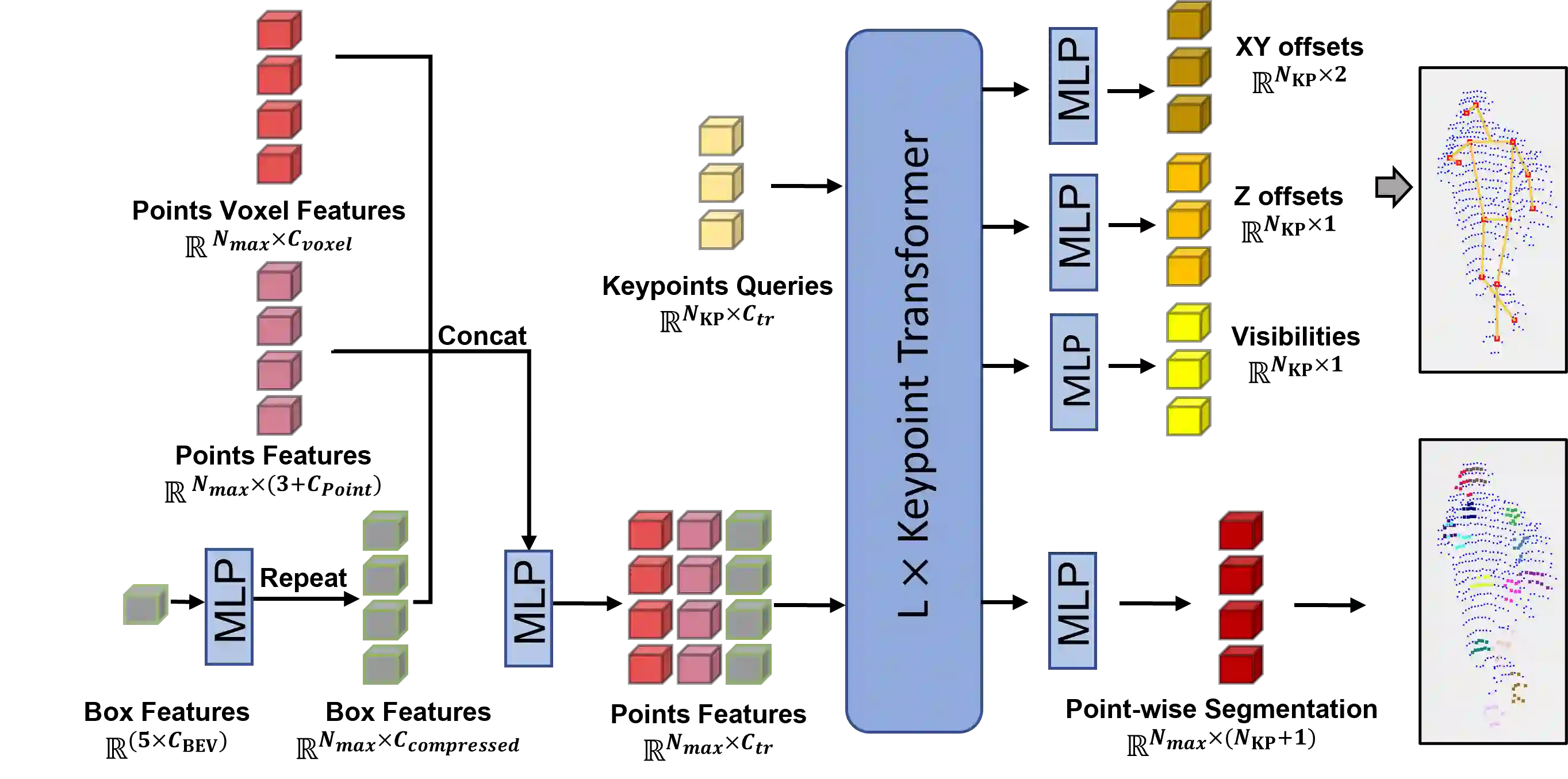
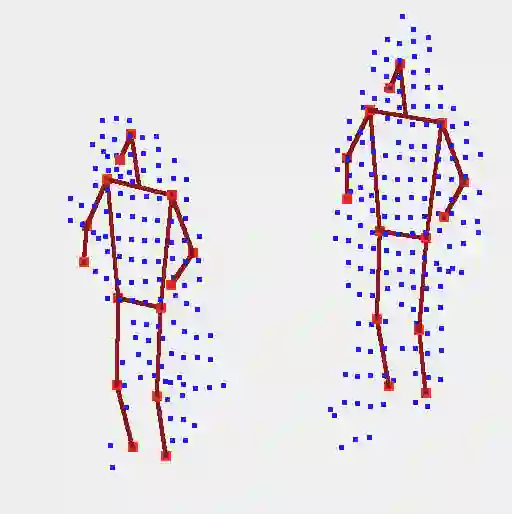
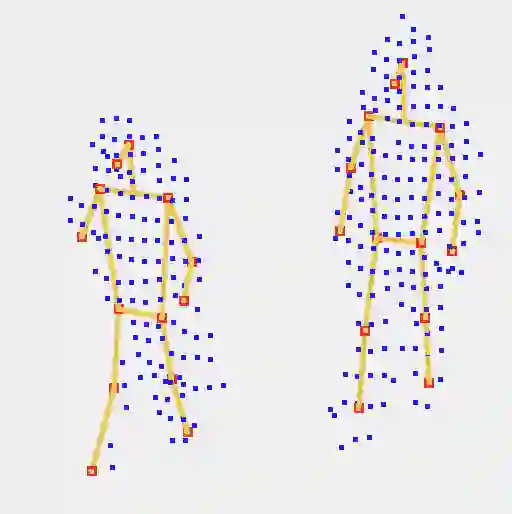
Due to the difficulty of acquiring large-scale 3D human keypoint annotation, previous methods for 3D human pose estimation (HPE) have often relied on 2D image features and sequential 2D annotations. Furthermore, the training of these networks typically assumes the prediction of a human bounding box and the accurate alignment of 3D point clouds with 2D images, making direct application in real-world scenarios challenging. In this paper, we present the 1st framework for end-to-end 3D human pose estimation, named LPFormer, which uses only LiDAR as its input along with its corresponding 3D annotations. LPFormer consists of two stages: firstly, it identifies the human bounding box and extracts multi-level feature representations, and secondly, it utilizes a transformer-based network to predict human keypoints based on these features. Our method demonstrates that 3D HPE can be seamlessly integrated into a strong LiDAR perception network and benefit from the features extracted by the network. Experimental results on the Waymo Open Dataset demonstrate the state-of-the-art performance, and improvements even compared to previous multi-modal solutions.
翻译:由于大规模三维人体关键点标注数据难以获取,以往的三维人体姿态估计方法常依赖二维图像特征及时序二维标注。此外,这些网络的训练通常需要预测人体边界框并精确对齐三维点云与二维图像,导致其在真实场景中难以直接应用。本文提出首个端到端三维人体姿态估计框架LPFormer,该框架仅以LiDAR点云及其对应三维标注作为输入。LPFormer包含两个阶段:首先识别人体边界框并提取多层级特征表征,随后基于这些特征利用Transformer网络预测人体关键点。实验表明,三维人体姿态估计可无缝集成于强健的LiDAR感知网络,并受益于该网络提取的特征。在Waymo公开数据集上的实验结果达到了最先进性能,甚至优于以往的多模态解决方案。