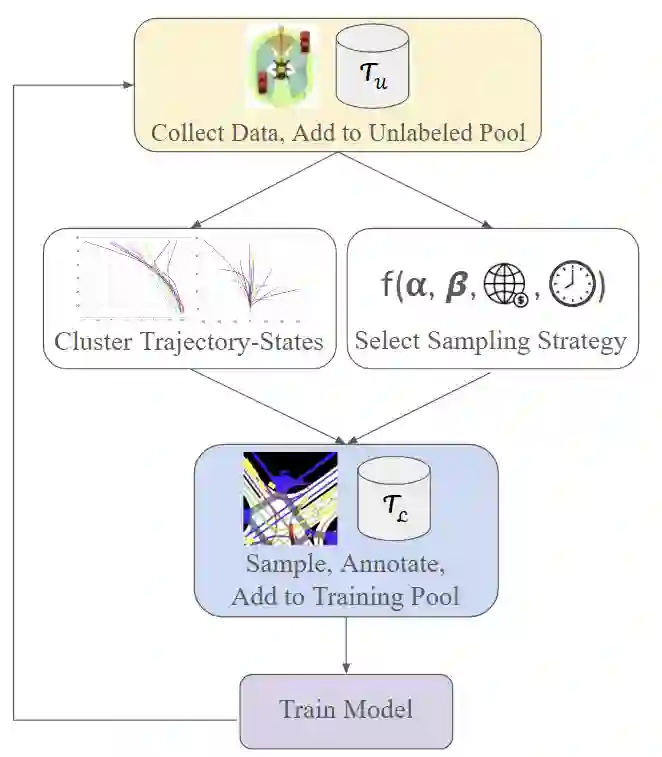
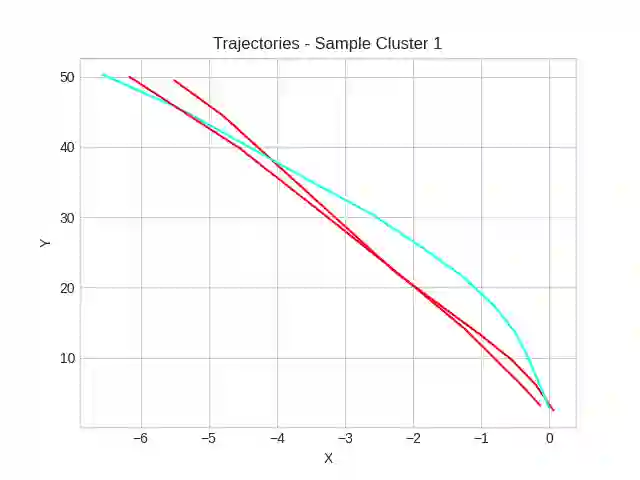
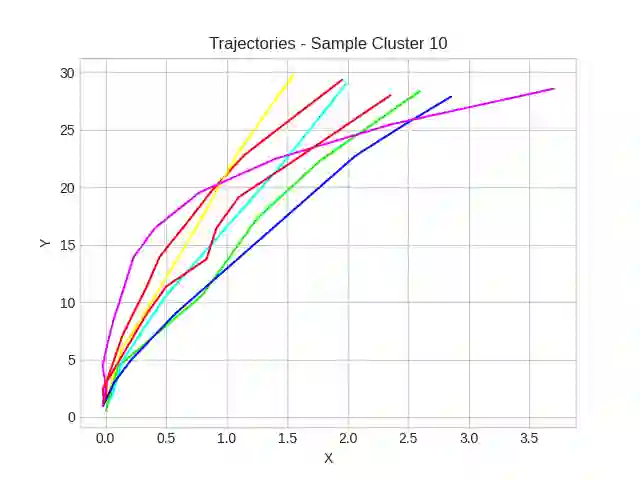
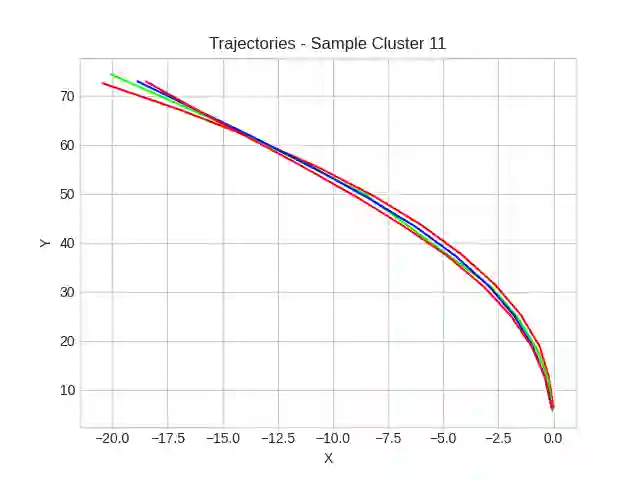
This study investigates the use of trajectory and dynamic state information for efficient data curation in autonomous driving machine learning tasks. We propose methods for clustering trajectory-states and sampling strategies in an active learning framework, aiming to reduce annotation and data costs while maintaining model performance. Our approach leverages trajectory information to guide data selection, promoting diversity in the training data. We demonstrate the effectiveness of our methods on the trajectory prediction task using the nuScenes dataset, showing consistent performance gains over random sampling across different data pool sizes, and even reaching sub-baseline displacement errors at just 50% of the data cost. Our results suggest that sampling typical data initially helps overcome the ''cold start problem,'' while introducing novelty becomes more beneficial as the training pool size increases. By integrating trajectory-state-informed active learning, we demonstrate that more efficient and robust autonomous driving systems are possible and practical using low-cost data curation strategies.
翻译:本研究探讨了在自动驾驶机器学习任务中,利用轨迹与动态状态信息实现高效数据筛选的方法。我们提出了轨迹状态聚类方法及主动学习框架中的采样策略,旨在降低标注与数据成本的同时保持模型性能。该方法通过轨迹信息引导数据选择,增强训练数据的多样性。我们基于nuScenes数据集在轨迹预测任务上验证了方法的有效性,结果表明:在不同数据池规模下,该方法持续优于随机采样,且仅需50%的数据成本即可达到低于基线水平的位移误差。实验结果揭示,初始阶段采样典型数据有助于克服“冷启动问题”,而随着训练池规模增大,引入新颖数据将更具效益。通过集成轨迹状态信息的主动学习,我们证实了利用低成本数据筛选策略构建更高效、鲁棒的自动驾驶系统具有可行性。