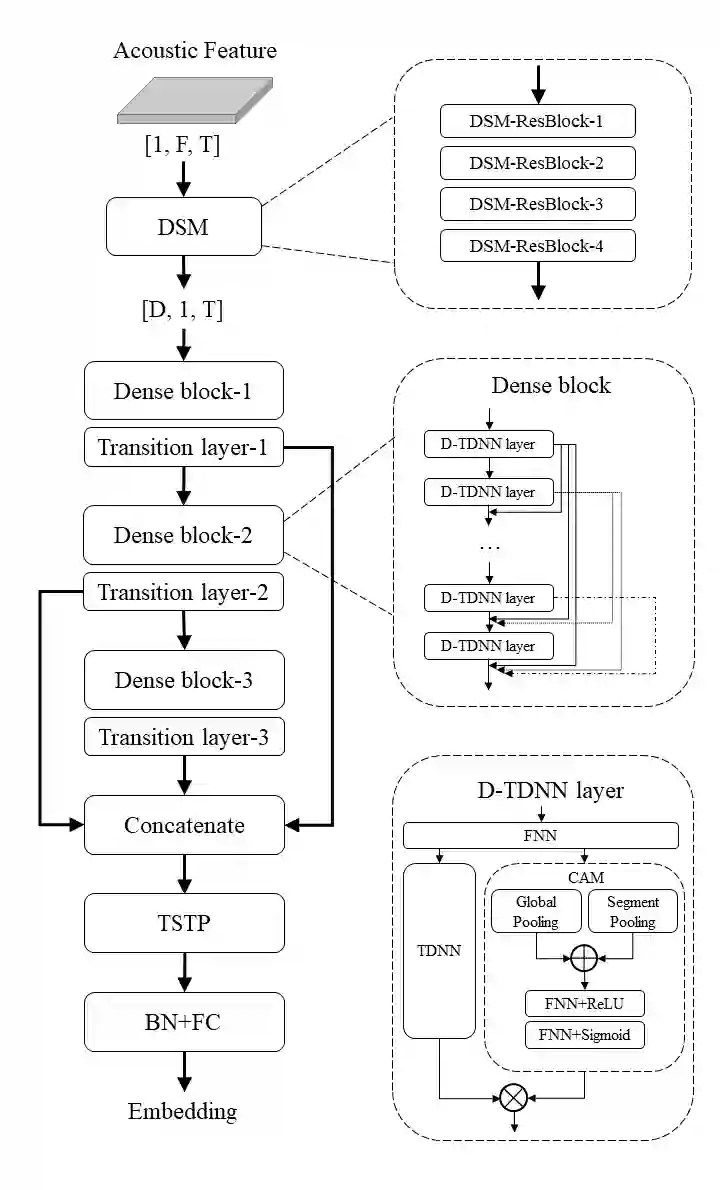
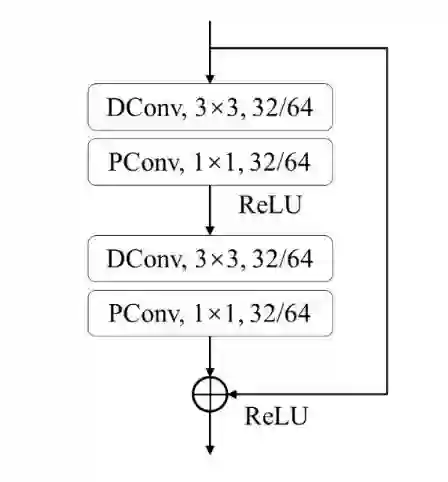
Traditional Time Delay Neural Networks (TDNN) have achieved state-of-the-art performance at the cost of high computational complexity and slower inference speed, making them difficult to implement in an industrial environment. The Densely Connected Time Delay Neural Network (D-TDNN) with Context Aware Masking (CAM) module has proven to be an efficient structure to reduce complexity while maintaining system performance. In this paper, we propose a fast and lightweight model, LightCAM, which further adopts a depthwise separable convolution module (DSM) and uses multi-scale feature aggregation (MFA) for feature fusion at different levels. Extensive experiments are conducted on VoxCeleb dataset, the comparative results show that it has achieved an EER of 0.83 and MinDCF of 0.0891 in VoxCeleb1-O, which outperforms the other mainstream speaker verification methods. In addition, complexity analysis further demonstrates that the proposed architecture has lower computational cost and faster inference speed.
翻译:传统时延神经网络(TDNN)虽以高计算复杂度和较慢推理速度实现了最优性能,却难以在工业环境中部署。带有上下文感知掩码(CAM)模块的密集连接时延神经网络(D-TDNN)已被证明是一种在保持系统性能的同时降低复杂度的有效结构。本文提出了一种快速轻量级模型LightCAM,该模型进一步采用深度可分离卷积模块(DSM),并利用多尺度特征聚合(MFA)进行不同层级特征融合。基于VoxCeleb数据集的大量实验表明,该方法在VoxCeleb1-O测试集上实现了0.83%的等错误率(EER)和0.0891的最小检测代价函数(MinDCF),优于其他主流说话人验证方法。此外,复杂度分析进一步证实该架构具有较低的计算成本和更快的推理速度。