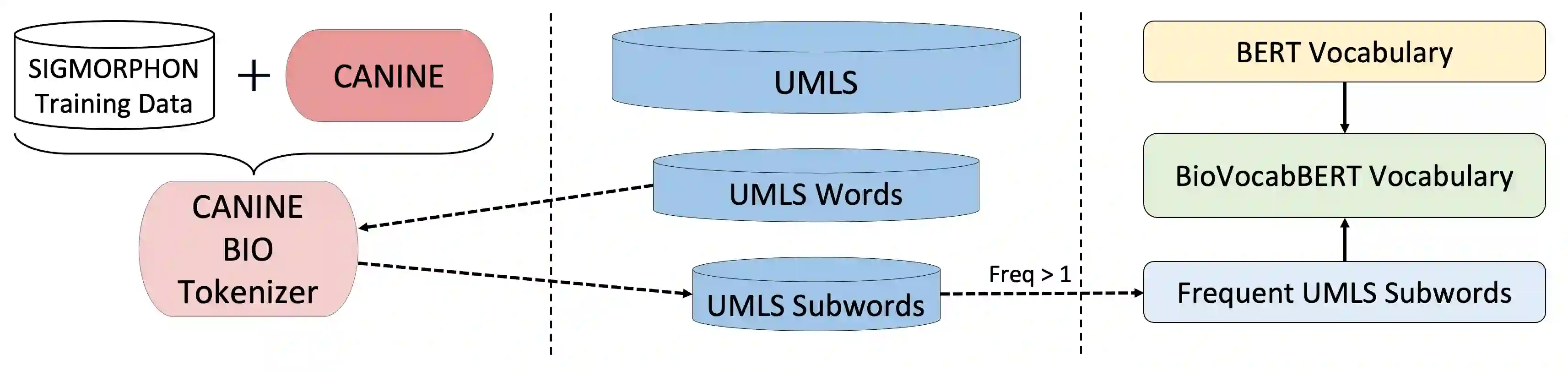
As opposed to general English, many concepts in biomedical terminology have been designed in recent history by biomedical professionals with the goal of being precise and concise. This is often achieved by concatenating meaningful biomedical morphemes to create new semantic units. Nevertheless, most modern biomedical language models (LMs) are pre-trained using standard domain-specific tokenizers derived from large scale biomedical corpus statistics without explicitly leveraging the agglutinating nature of biomedical language. In this work, we first find that standard open-domain and biomedical tokenizers are largely unable to segment biomedical terms into meaningful components. Therefore, we hypothesize that using a tokenizer which segments biomedical terminology more accurately would enable biomedical LMs to improve their performance on downstream biomedical NLP tasks, especially ones which involve biomedical terms directly such as named entity recognition (NER) and entity linking. Surprisingly, we find that pre-training a biomedical LM using a more accurate biomedical tokenizer does not improve the entity representation quality of a language model as measured by several intrinsic and extrinsic measures such as masked language modeling prediction (MLM) accuracy as well as NER and entity linking performance. These quantitative findings, along with a case study which explores entity representation quality more directly, suggest that the biomedical pre-training process is quite robust to instances of sub-optimal tokenization.
翻译:与通用英语不同,生物医学术语中的许多概念是由生物医学专业人士在近代设计而成,其目标在于精确且简洁。这通常通过组合有意义的生物医学词素来创建新的语义单元来实现。然而,大多数现代生物医学语言模型(LMs)在预训练时,使用的是基于大规模生物医学语料库统计得出的标准领域特定分词器,并未显式利用生物医学语言的粘着特性。本研究首先发现,标准的开放域和生物医学分词器在很大程度上无法将生物医学术语切分为有意义的组成部分。因此,我们假设,采用更准确地分割生物医学术语的分词器,能够提升生物医学LMs在下游生物医学自然语言处理任务(尤其是直接涉及生物医学术语的任务,如命名实体识别(NER)和实体链接)上的性能。令人惊讶的是,我们发现使用更精确的生物医学分词器预训练生物医学LM,并未提升语言模型的实体表征质量——无论是通过掩码语言建模预测(MLM)准确性等内在指标,还是通过NER和实体链接性能等外在指标来衡量。这些定量发现,结合一项更直接探究实体表征质量的案例研究,表明生物医学预训练过程对次优分词实例具有较强的鲁棒性。