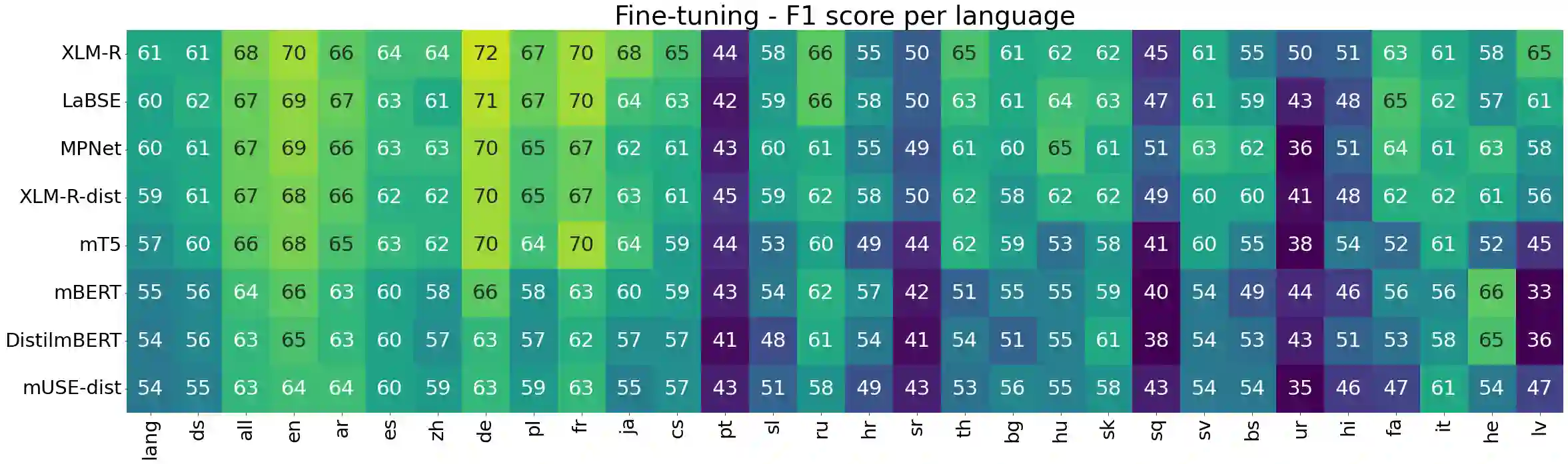
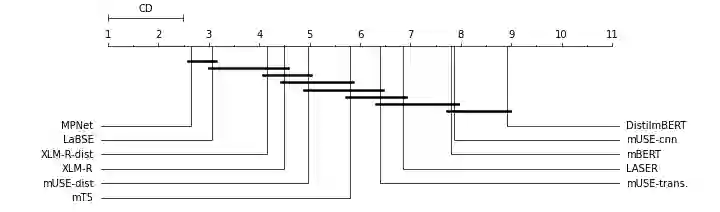
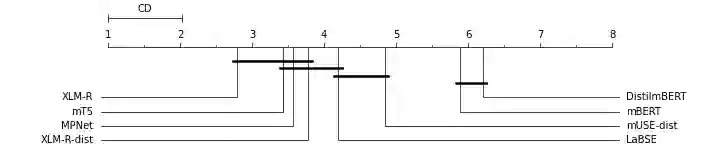
Despite impressive advancements in multilingual corpora collection and model training, developing large-scale deployments of multilingual models still presents a significant challenge. This is particularly true for language tasks that are culture-dependent. One such example is the area of multilingual sentiment analysis, where affective markers can be subtle and deeply ensconced in culture. This work presents the most extensive open massively multilingual corpus of datasets for training sentiment models. The corpus consists of 79 manually selected datasets from over 350 datasets reported in the scientific literature based on strict quality criteria. The corpus covers 27 languages representing 6 language families. Datasets can be queried using several linguistic and functional features. In addition, we present a multi-faceted sentiment classification benchmark summarizing hundreds of experiments conducted on different base models, training objectives, dataset collections, and fine-tuning strategies.
翻译:尽管在多语言语料库收集和模型训练方面取得了令人瞩目的进展,但开发大规模多语言模型的部署仍然面临重大挑战,尤其是对于依赖文化的语言任务而言。多语言情感分析便是其中一例,其情感标记可能微妙且深植于文化之中。本研究提出了迄今为止最广泛的开放大规模多语言情感模型训练数据集语料库。该语料库包含依据严格质量标准从科学文献中报道的350多个数据集中人工筛选的79个数据集,覆盖27种语言,分属6个语系。数据集可通过多种语言和功能特征进行查询。此外,我们还提出了一个多层面情感分类基准,总结了在不同基础模型、训练目标、数据集集合和微调策略上开展的数百项实验。