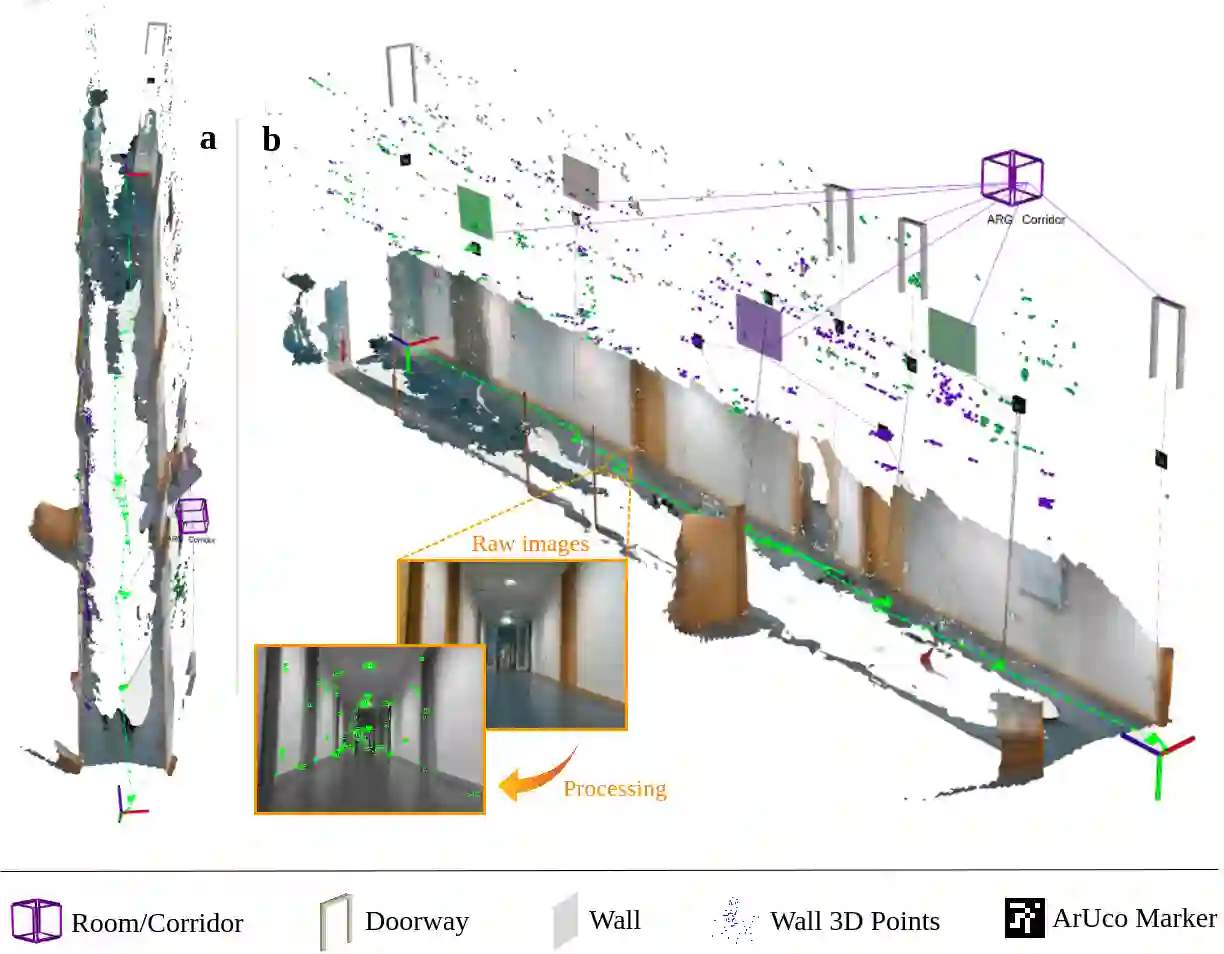
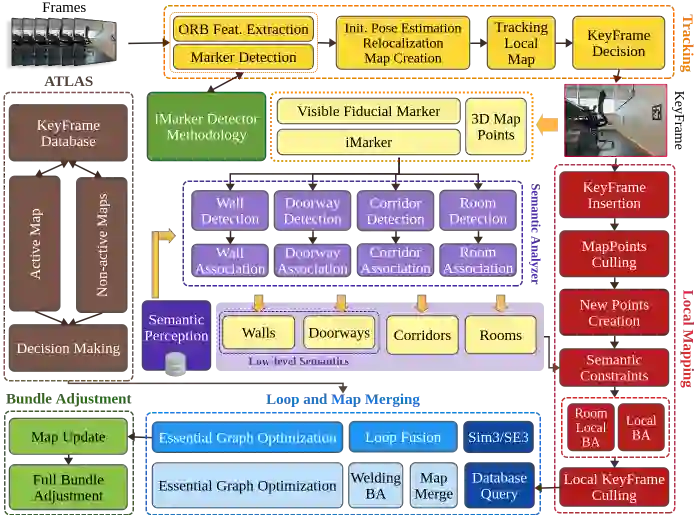
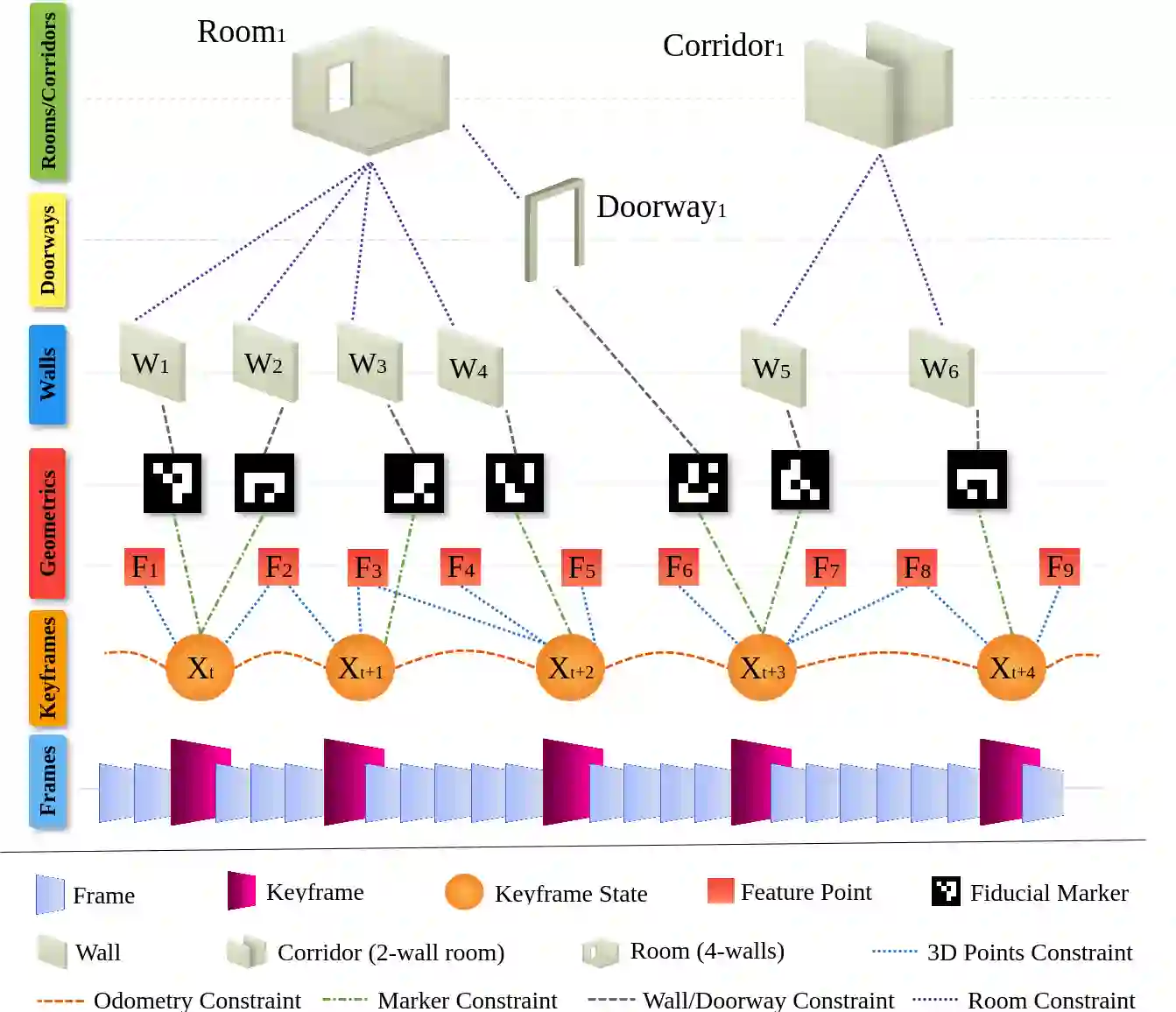
Situational Graphs (S-Graphs) merge geometric models of the environment generated by Simultaneous Localization and Mapping (SLAM) approaches with 3D scene graphs into a multi-layered jointly optimizable factor graph. As an advantage, S-Graphs not only offer a more comprehensive robotic situational awareness by combining geometric maps with diverse hierarchically organized semantic entities and their topological relationships within one graph, but they also lead to improved performance of localization and mapping on the SLAM level by exploiting semantic information. In this paper, we introduce a vision-based version of S-Graphs where a conventional \ac{VSLAM} system is used for low-level feature tracking and mapping. In addition, the framework exploits the potential of fiducial markers (both visible as well as our recently introduced transparent or fully invisible markers) to encode comprehensive information about environments and the objects within them. The markers aid in identifying and mapping structural-level semantic entities, including walls and doors in the environment, with reliable poses in the global reference, subsequently establishing meaningful associations with higher-level entities, including corridors and rooms. However, in addition to including semantic entities, the semantic and geometric constraints imposed by the fiducial markers are also utilized to improve the reconstructed map's quality and reduce localization errors. Experimental results on a real-world dataset collected using legged robots show that our framework excels in crafting a richer, multi-layered hierarchical map and enhances robot pose accuracy at the same time.
翻译:情境图(S-Graphs)将同步定位与建图(SLAM)方法生成的环境几何模型与三维场景图融合为一个多层联合可优化因子图。其优势在于,S-Graphs不仅通过将几何地图与多种层次化组织的语义实体及其拓扑关系整合于单一图结构中,提供了更全面的机器人环境态势感知能力,同时还能利用语义信息提升SLAM层面的定位与建图性能。本文提出一种基于视觉的S-Graphs框架,其中采用传统视觉SLAM系统进行底层特征跟踪与建图。此外,该框架充分利用基准标记(包括可见标记及我们近期提出的透明或完全不可见标记)的潜力,以编码环境及其内部物体的综合信息。这些标记有助于识别和建图结构级语义实体(如环境中的墙壁和门),并在全局参考系中获得可靠位姿,进而与走廊、房间等高层级实体建立有意义的关联。除引入语义实体外,本文还利用基准标记提供的语义与几何约束来提升重建地图的质量并降低定位误差。基于腿式机器人采集的真实世界数据集的实验结果表明,该框架能够构建更丰富的多层级地图,同时显著提高机器人位姿估计精度。