
Inverse reinforcement learning (IRL) is computationally challenging, with common approaches requiring the solution of multiple reinforcement learning (RL) sub-problems. This work motivates the use of potential-based reward shaping to reduce the computational burden of each RL sub-problem. This work serves as a proof-of-concept and we hope will inspire future developments towards computationally efficient IRL.
翻译:逆强化学习(IRL)在计算上具有挑战性,常用方法需要求解多个强化学习(RL)子问题。本研究提出利用基于势能的奖励塑造来降低每个RL子问题的计算负担。本文作为概念验证,有望为未来实现计算高效的逆强化学习提供启示。
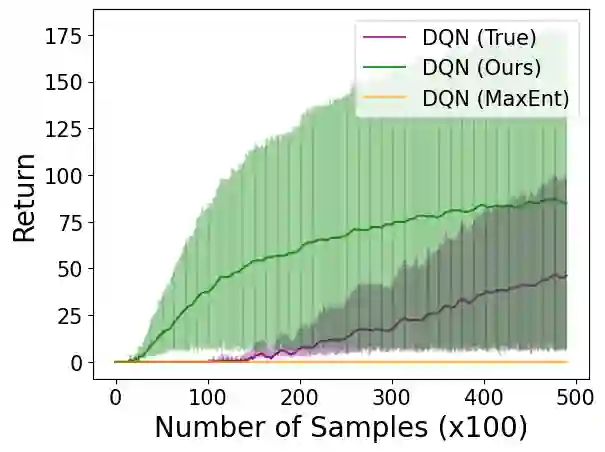
相关内容

专知会员服务
34+阅读 · 2019年10月18日
专知会员服务
36+阅读 · 2019年10月17日


最新内容
相关VIP内容
专知会员服务
34+阅读 · 2019年10月18日
专知会员服务
36+阅读 · 2019年10月17日
相关资讯
相关论文