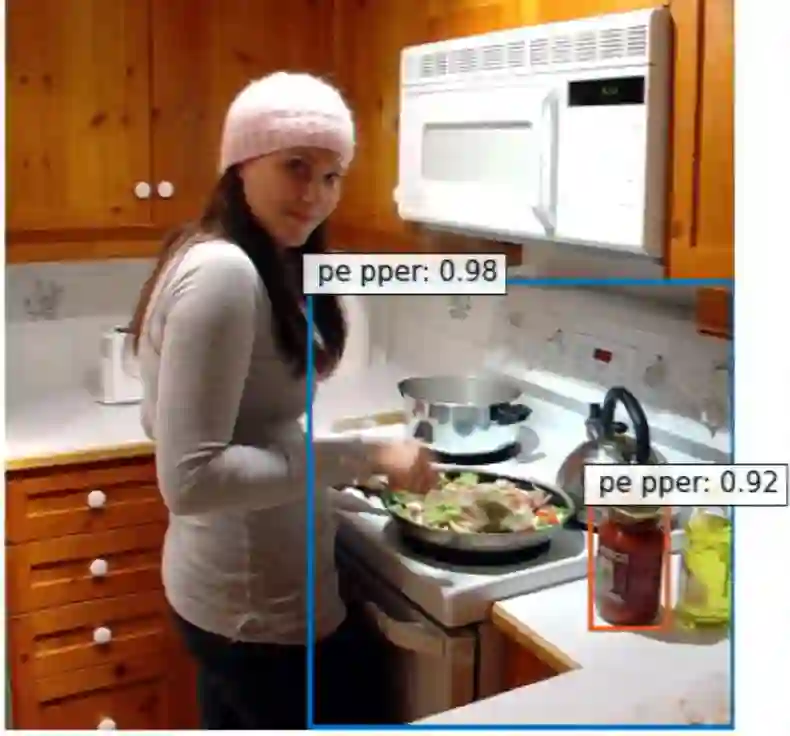
The challenge of visual grounding and masking in multimodal machine translation (MMT) systems has encouraged varying approaches to the detection and selection of visually-grounded text tokens for masking. We introduce new methods for detection of visually and contextually relevant (concrete) tokens from source sentences, including detection with natural language processing (NLP), detection with object detection, and a joint detection-verification technique. We also introduce new methods for selection of detected tokens, including shortest $n$ tokens, longest $n$ tokens, and all detected concrete tokens. We utilize the GRAM MMT architecture to train models against synthetically collated multimodal datasets of source images with masked sentences, showing performance improvements and improved usage of visual context during translation tasks over the baseline model.
翻译:多模态机器翻译(MMT)系统中的视觉定位与掩码问题,推动了针对视觉相关文本标记检测与选择方法的研究。本文提出了从源句中检测视觉与语境相关具体标记的新方法,包括基于自然语言处理(NLP)的检测、基于目标检测的方法以及联合检测-验证技术。同时,我们引入了检测标记的选择策略,包括最短n个标记、最长n个标记以及所有检测到的具体标记。基于GRAM多模态机器翻译架构,利用合成拼接的多模态数据集(包含源图像及其掩码句子)训练模型,实验表明,相较于基线模型,该方法在翻译任务中实现了性能提升并增强了对视觉上下文的利用能力。