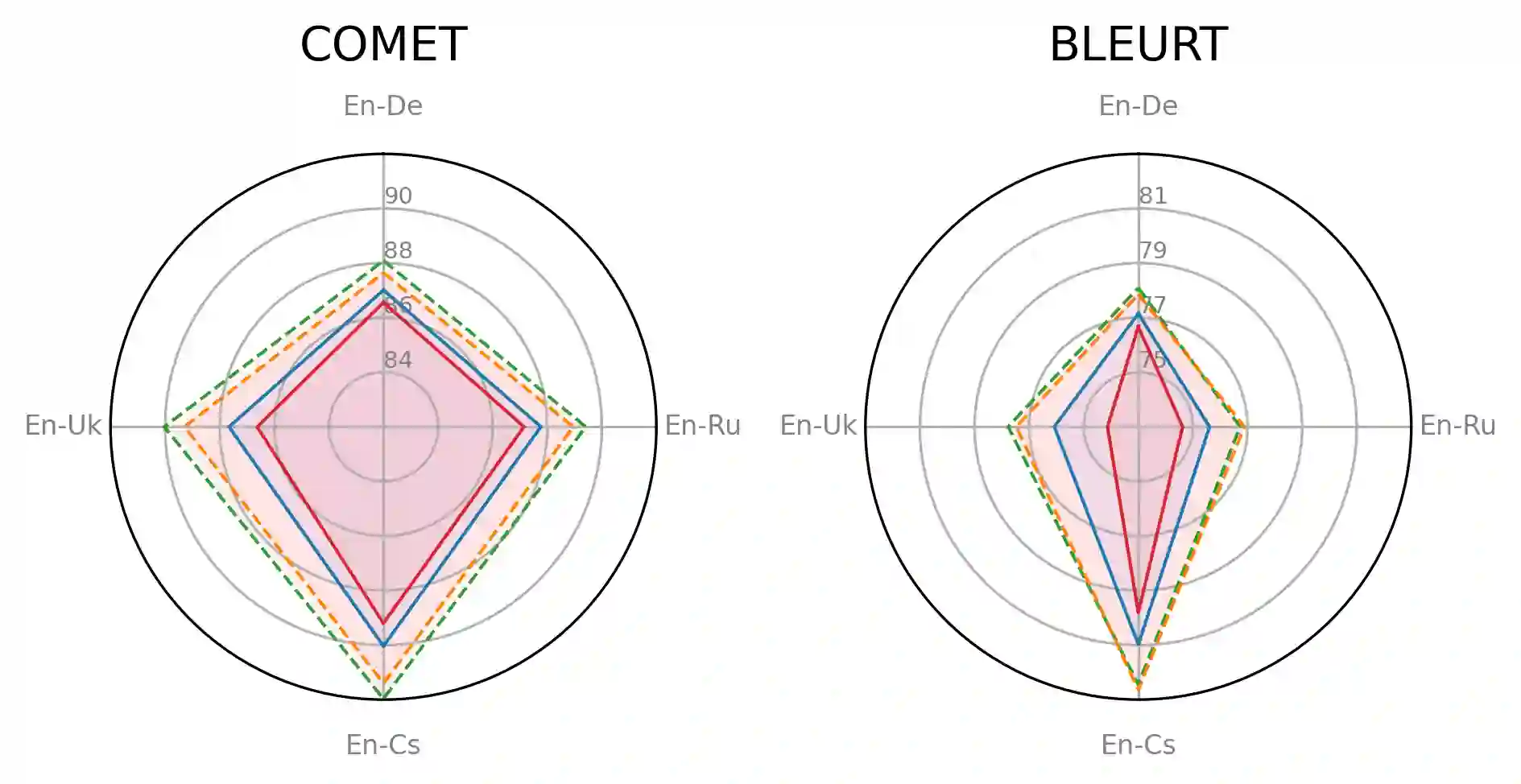
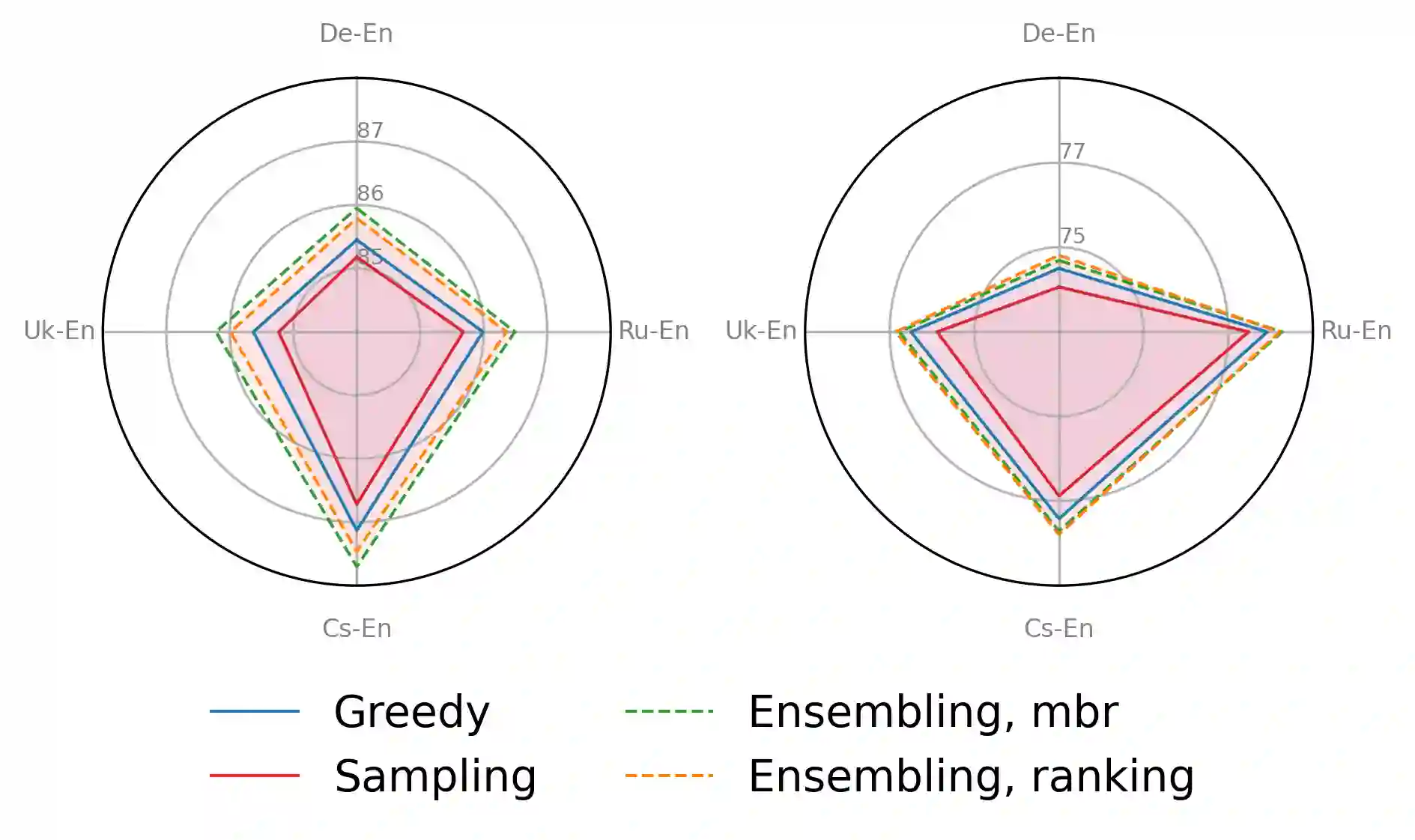
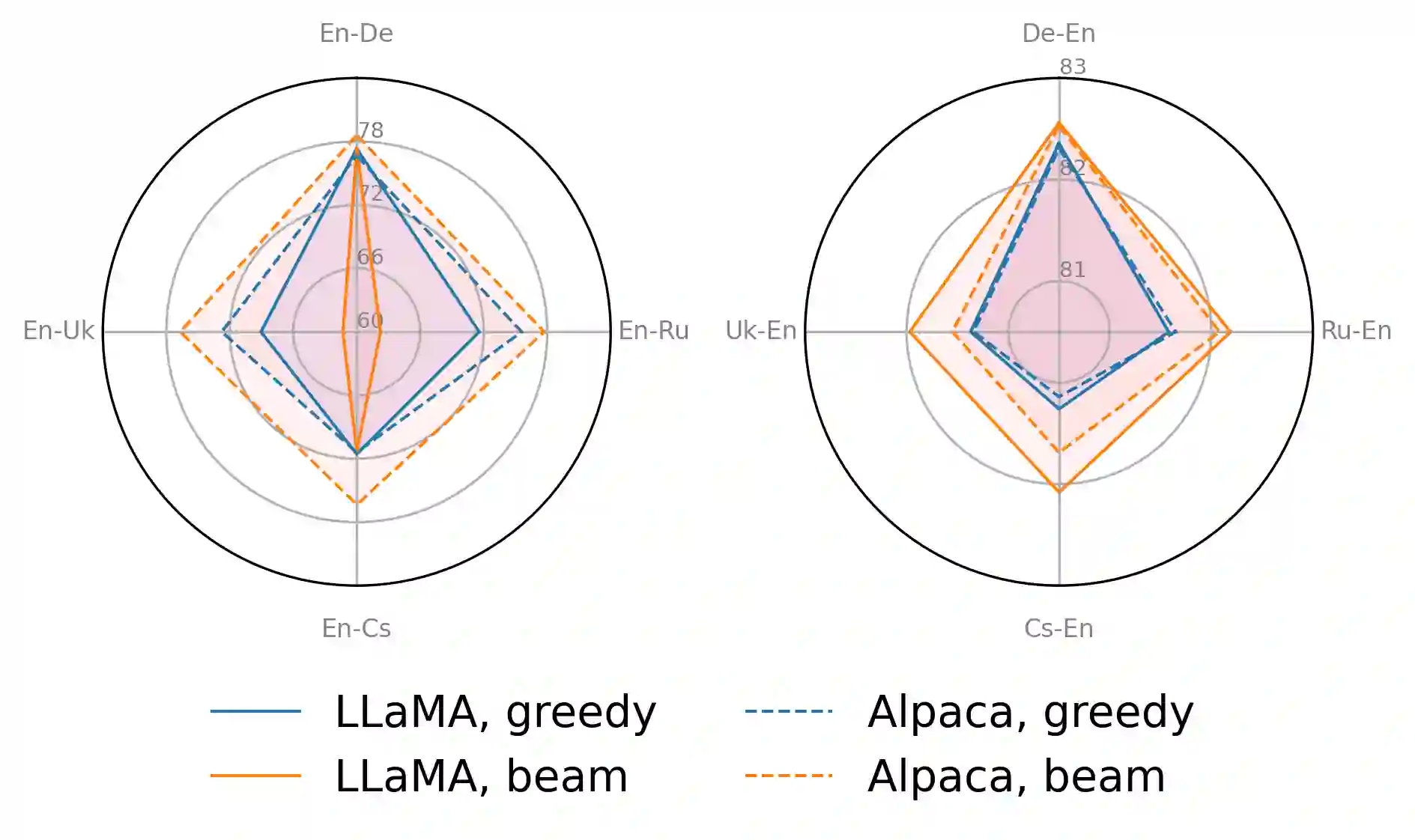
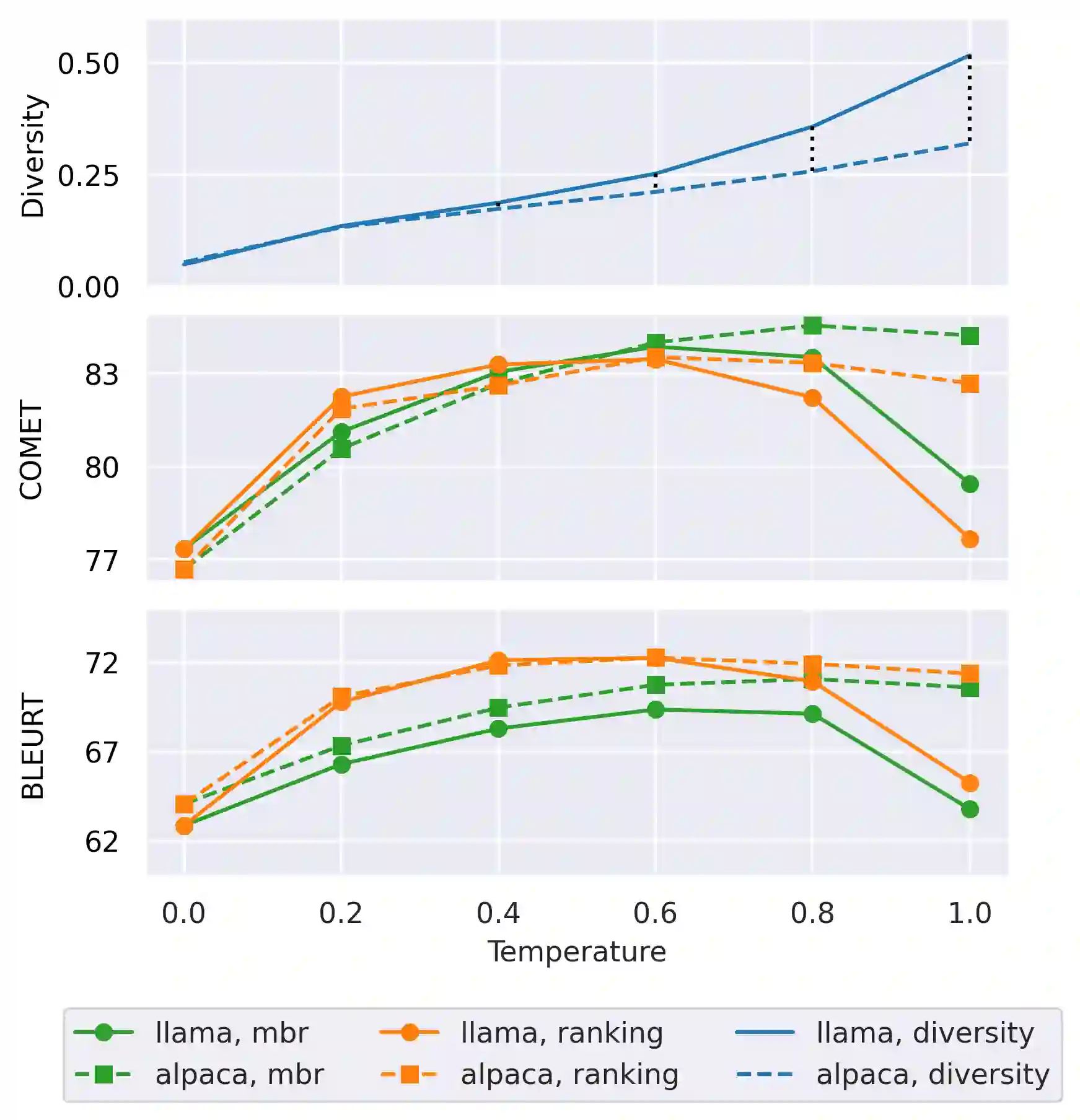
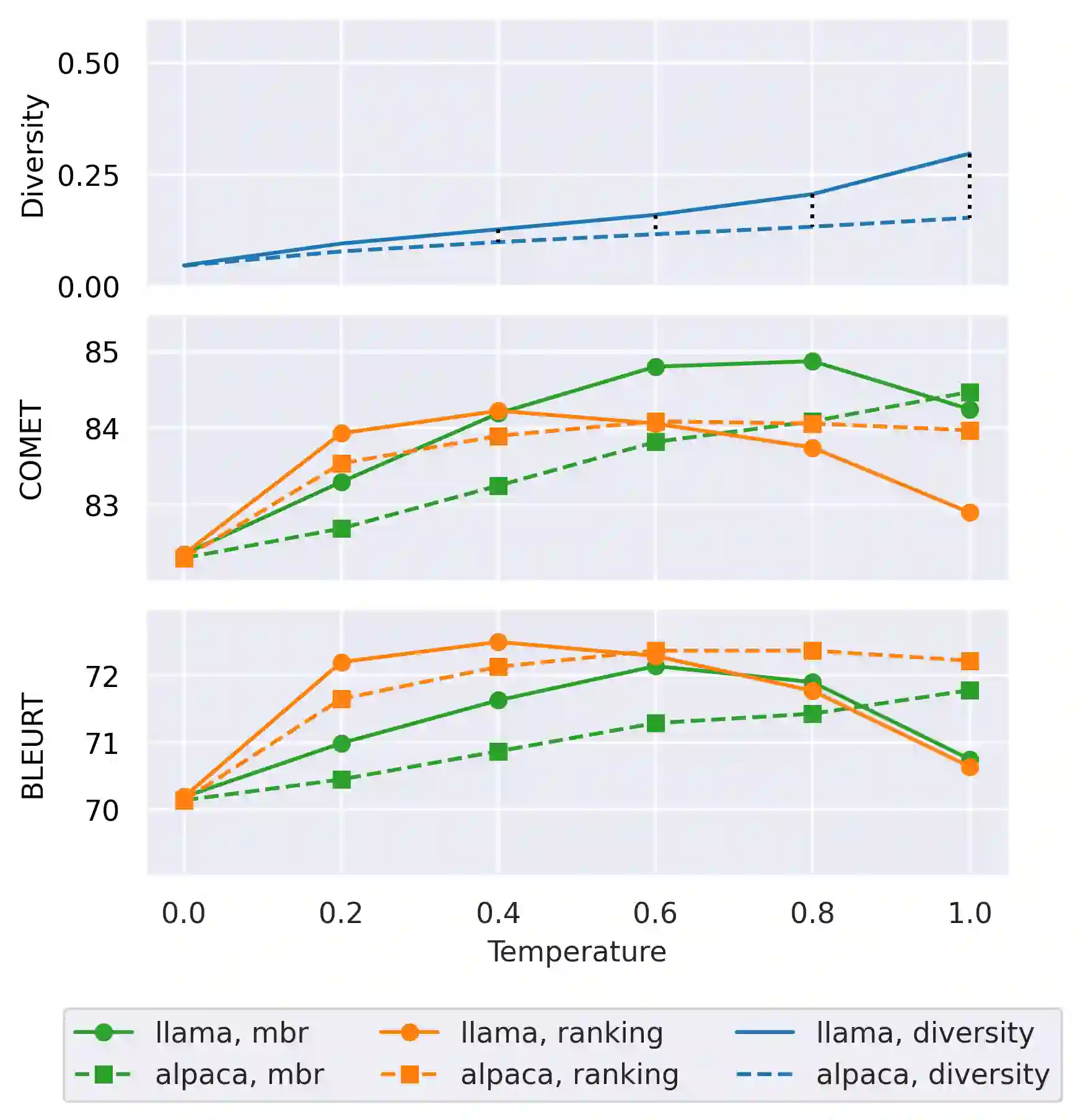
Large language models (LLMs) are becoming a one-fits-many solution, but they sometimes hallucinate or produce unreliable output. In this paper, we investigate how hypothesis ensembling can improve the quality of the generated text for the specific problem of LLM-based machine translation. We experiment with several techniques for ensembling hypotheses produced by LLMs such as ChatGPT, LLaMA, and Alpaca. We provide a comprehensive study along multiple dimensions, including the method to generate hypotheses (multiple prompts, temperature-based sampling, and beam search) and the strategy to produce the final translation (instruction-based, quality-based reranking, and minimum Bayes risk (MBR) decoding). Our results show that MBR decoding is a very effective method, that translation quality can be improved using a small number of samples, and that instruction tuning has a strong impact on the relation between the diversity of the hypotheses and the sampling temperature.
翻译:大语言模型(LLMs)正逐渐成为一种通用解决方案,但它们有时会产生幻觉或不可靠的输出。本文针对基于LLM的机器翻译这一特定问题,研究假设集成如何提升生成文本的质量。我们实验了多种集成由LLM(如ChatGPT、LLaMA和Alpaca)产生的假设的技术。我们从多个维度进行了全面的研究,包括生成假设的方法(多提示、基于温度的采样和束搜索)以及产生最终翻译的策略(基于指令、基于质量的重排序和最小贝叶斯风险(MBR)解码)。结果表明:MBR解码是一种非常有效的方法,使用少量样本即可提升翻译质量,并且指令调优对假设多样性与采样温度之间的关系具有显著影响。