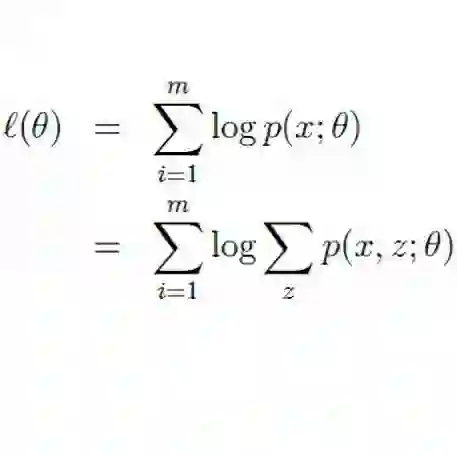Data heterogeneity has been a long-standing bottleneck in studying the convergence rates of Federated Learning algorithms. In order to better understand the issue of data heterogeneity, we study the convergence rate of the Expectation-Maximization (EM) algorithm for the Federated Mixture of $K$ Linear Regressions model (FMLR). We completely characterize the convergence rate of the EM algorithm under all regimes of number of clients and number of data points per client, with partial limits in the number of clients. We show that with a signal-to-noise-ratio (SNR) that is atleast of order $\sqrt{K}$, the well-initialized EM algorithm converges to the ground truth under all regimes. We perform experiments on synthetic data to illustrate our results. In line with our theoretical findings, the simulations show that rather than being a bottleneck, data heterogeneity can accelerate the convergence of iterative federated algorithms.
翻译:数据异质性一直是研究联邦学习算法收敛速度的核心瓶颈。为深入理解数据异质性问题,我们研究了联邦K线性回归混合模型(FMLR)下期望最大化(EM)算法的收敛速度。我们完整刻画了在客户端数量与每客户端数据点数量的所有配置下EM算法的收敛特性,并分析了客户端数量部分受限时的情形。研究表明,当信噪比(SNR)至少达到$\sqrt{K}$量级时,良好初始化的EM算法在所有配置下均能收敛至真实参数。我们通过合成数据实验验证了理论结果。与理论发现一致,仿真表明数据异质性非但不会成为瓶颈,反而能加速迭代式联邦算法的收敛。