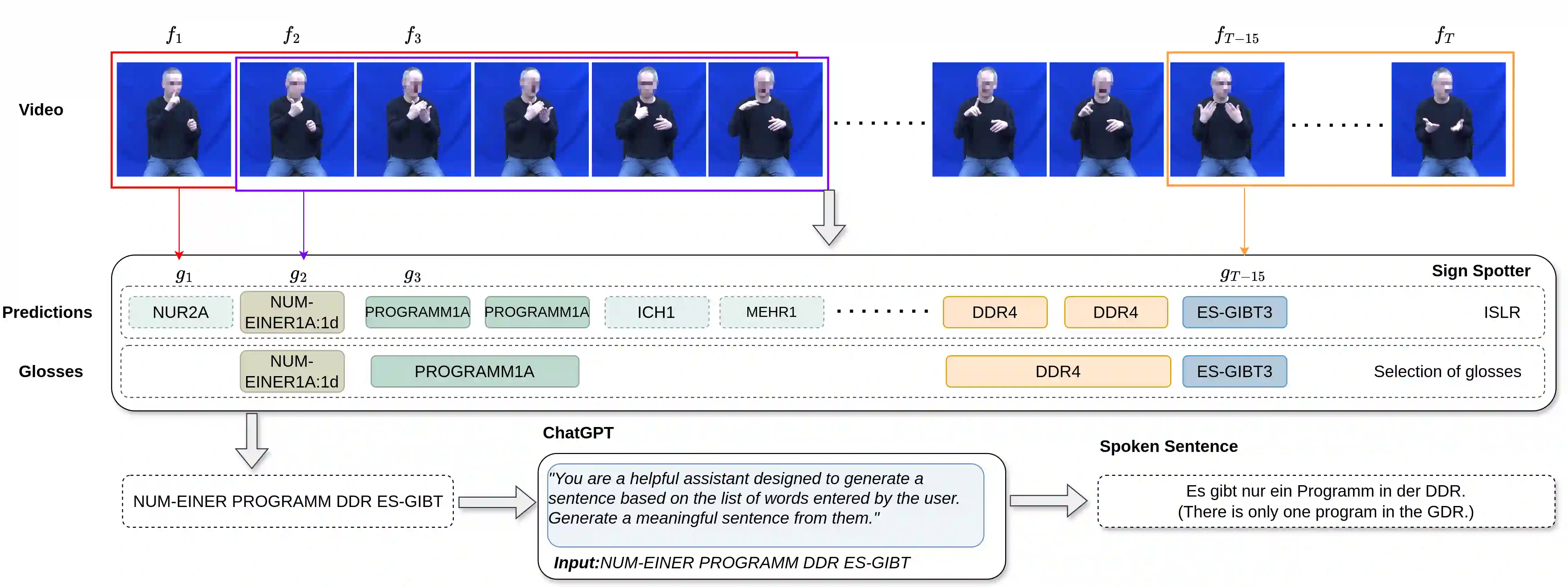
Sign Language Translation (SLT) is a challenging task that aims to generate spoken language sentences from sign language videos. In this paper, we introduce a hybrid SLT approach, Spotter+GPT, that utilizes a sign spotter and a pretrained large language model to improve SLT performance. Our method builds upon the strengths of both components. The videos are first processed by the spotter, which is trained on a linguistic sign language dataset, to identify individual signs. These spotted signs are then passed to the powerful language model, which transforms them into coherent and contextually appropriate spoken language sentences.
翻译:手语翻译(Sign Language Translation, SLT)是一项具有挑战性的任务,旨在从手语视频生成口语语句。本文提出了一种混合SLT方法——Spotter+GPT,该方法利用手语识别器与预训练的大型语言模型来提升SLT性能。我们的方法融合了这两类组件的优势。首先,视频由经过语言学手语数据集训练的识别器处理,以识别单个手语词汇。随后,这些识别出的手语词汇被传递给强大的语言模型,由该模型将其转化为连贯且符合语境的口语语句。