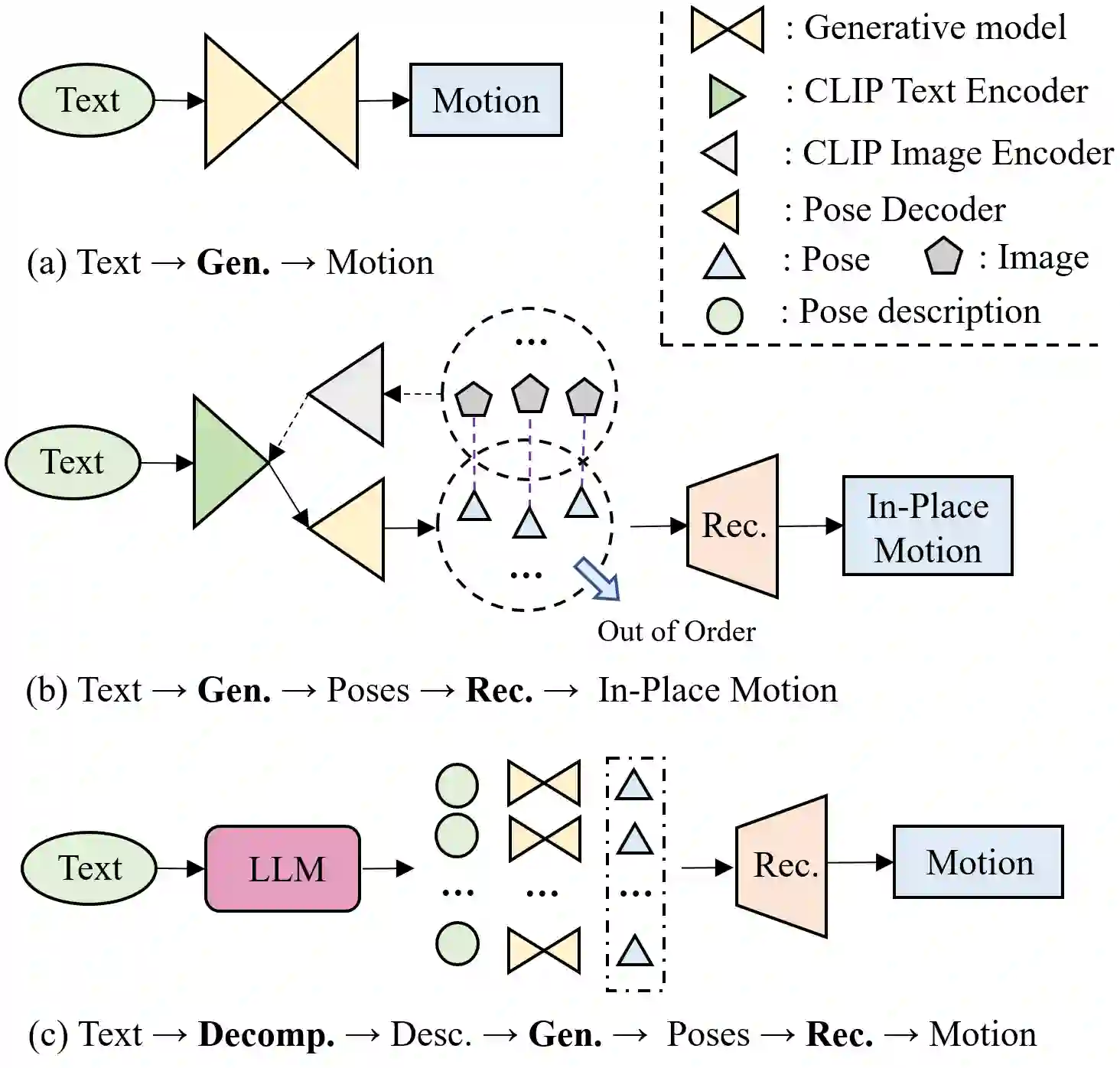
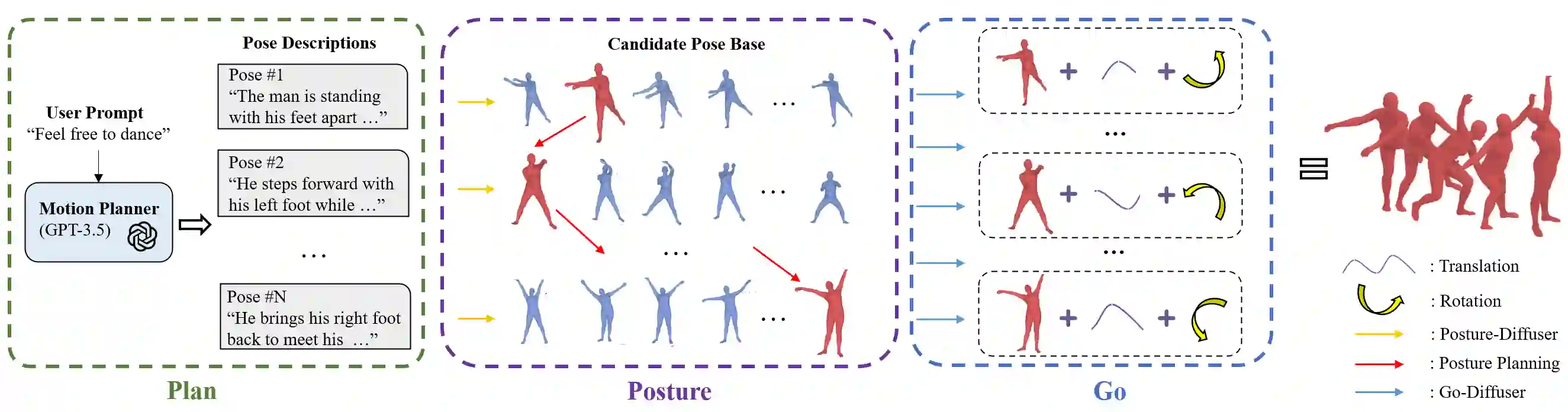
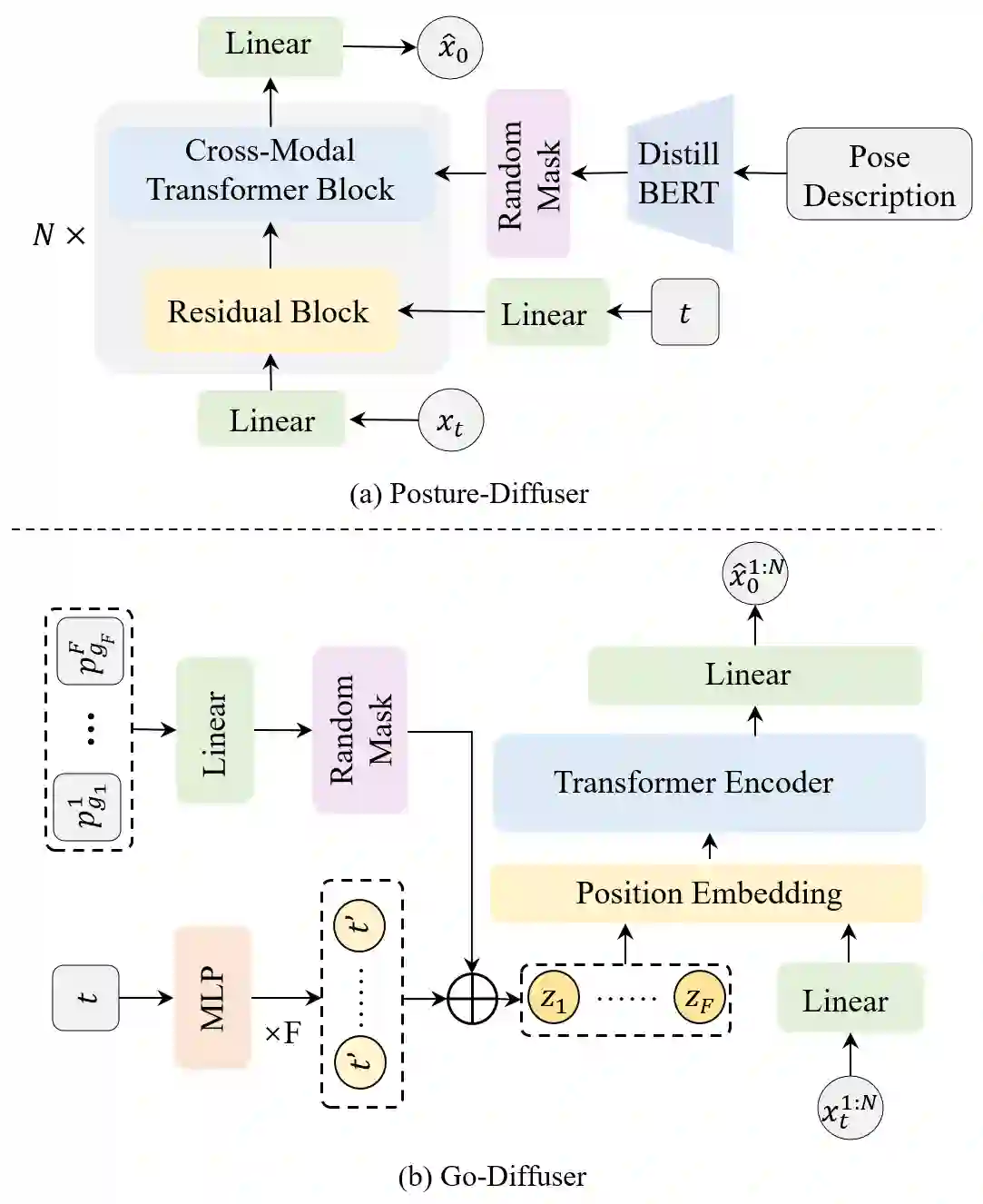
Conventional text-to-motion generation methods are usually trained on limited text-motion pairs, making them hard to generalize to open-world scenarios. Some works use the CLIP model to align the motion space and the text space, aiming to enable motion generation from natural language motion descriptions. However, they are still constrained to generate limited and unrealistic in-place motions. To address these issues, we present a divide-and-conquer framework named PRO-Motion, which consists of three modules as motion planner, posture-diffuser and go-diffuser. The motion planner instructs Large Language Models (LLMs) to generate a sequence of scripts describing the key postures in the target motion. Differing from natural languages, the scripts can describe all possible postures following very simple text templates. This significantly reduces the complexity of posture-diffuser, which transforms a script to a posture, paving the way for open-world generation. Finally, go-diffuser, implemented as another diffusion model, estimates whole-body translations and rotations for all postures, resulting in realistic motions. Experimental results have shown the superiority of our method with other counterparts, and demonstrated its capability of generating diverse and realistic motions from complex open-world prompts such as "Experiencing a profound sense of joy". The project page is available at https://moonsliu.github.io/Pro-Motion.
翻译:传统的文本生成动作方法通常仅在有限的文本-动作对上进行训练,因此难以泛化到开放世界场景。部分研究利用CLIP模型对齐动作空间与文本空间,旨在从自然语言动作描述中生成动作。然而,这些方法仍受限于生成有限且不真实的原地动作。为解决这些问题,我们提出了一种分治框架PRO-Motion,该框架包含三个模块:运动规划器、姿势扩散器与运动扩散器。运动规划器引导大语言模型(LLMs)生成描述目标动作中关键姿势的脚本序列。与自然语言不同,这些脚本可依据极简文本模板描述所有可能的姿势,显著降低了姿势扩散器的复杂性——后者将脚本转化为具体姿势,为开放世界生成奠定基础。最后,作为另一个扩散模型的运动扩散器,可为所有姿势估计全身平移与旋转参数,从而生成逼真动作。实验结果表明,我们的方法优于现有同类方法,并能从复杂开放世界提示(如"体验深刻的愉悦感")中生成多样化且逼真的动作。项目页面详见 https://moonsliu.github.io/Pro-Motion。