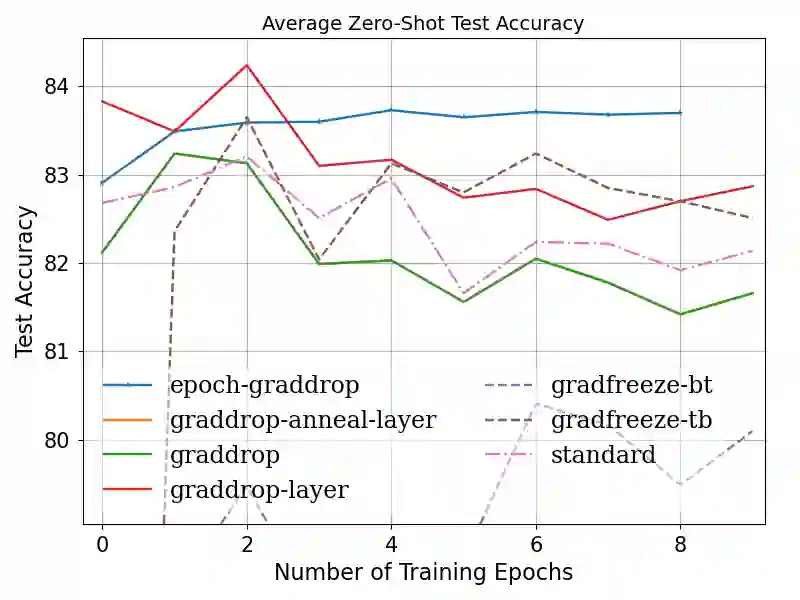
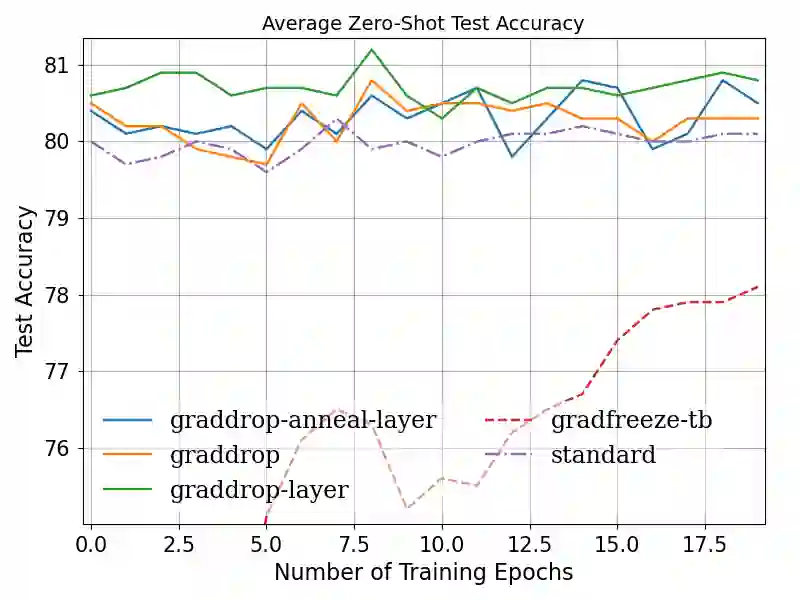
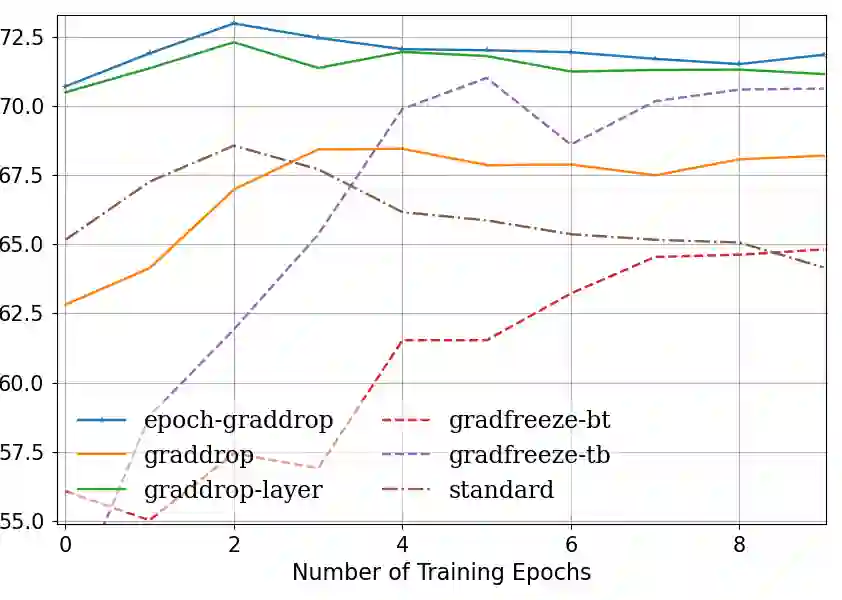
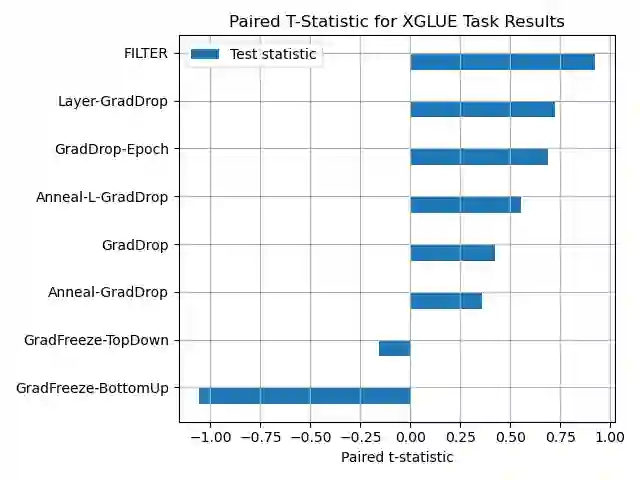
Fine-tuning pretrained self-supervised language models is widely adopted for transfer learning to downstream tasks. Fine-tuning can be achieved by freezing gradients of the pretrained network and only updating gradients of a newly added classification layer, or by performing gradient updates on all parameters. Gradual unfreezing makes a trade-off between the two by gradually unfreezing gradients of whole layers during training. This has been an effective strategy to trade-off between storage and training speed with generalization performance. However, it is not clear whether gradually unfreezing layers throughout training is optimal, compared to sparse variants of gradual unfreezing which may improve fine-tuning performance. In this paper, we propose to stochastically mask gradients to regularize pretrained language models for improving overall fine-tuned performance. We introduce GradDrop and variants thereof, a class of gradient sparsification methods that mask gradients during the backward pass, acting as gradient noise. GradDrop is sparse and stochastic unlike gradual freezing. Extensive experiments on the multilingual XGLUE benchmark with XLMR-Large show that GradDrop is competitive against methods that use additional translated data for intermediate pretraining and outperforms standard fine-tuning and gradual unfreezing. A post-analysis shows how GradDrop improves performance with languages it was not trained on, such as under-resourced languages.
翻译:微调预训练的自监督语言模型被广泛用于下游任务的迁移学习。微调可以通过冻结预训练网络的梯度仅更新新增分类层的梯度实现,也可以对所有参数进行梯度更新。逐步解冻通过在训练过程中逐步解冻整个层的梯度来实现两者之间的权衡。这种策略在存储、训练速度与泛化性能之间取得了有效平衡。然而,相较于可能提升微调性能的逐步解冻稀疏变体,当前尚不明确在整个训练过程中逐层解冻是否最优。本文提出通过随机掩码梯度来正则化预训练语言模型,从而提升整体微调性能。我们引入GradDrop及其变体——一类在反向传播阶段掩码梯度的梯度稀疏化方法,其作用相当于梯度噪声。与逐步解冻不同,GradDrop具有稀疏性和随机性。在多语言XGLUE基准测试中,使用XLMR-Large进行的大量实验表明,GradDrop在利用额外翻译数据进行中间预训练的方法中具有竞争力,并优于标准微调和逐步解冻方法。后续分析显示,GradDrop如何提升模型对未训练语言(如资源匮乏语言)的性能。