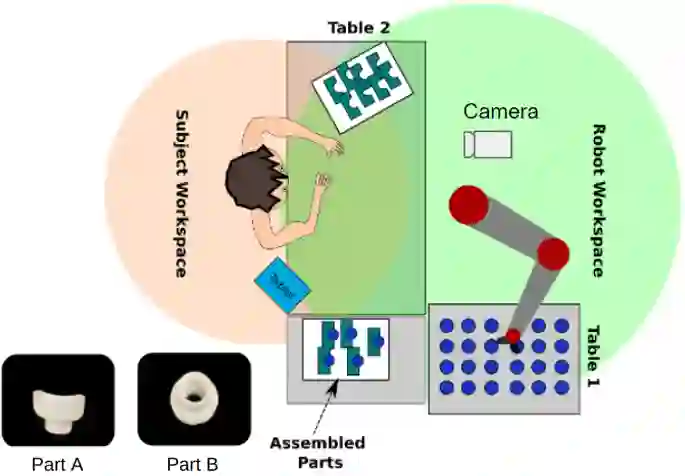
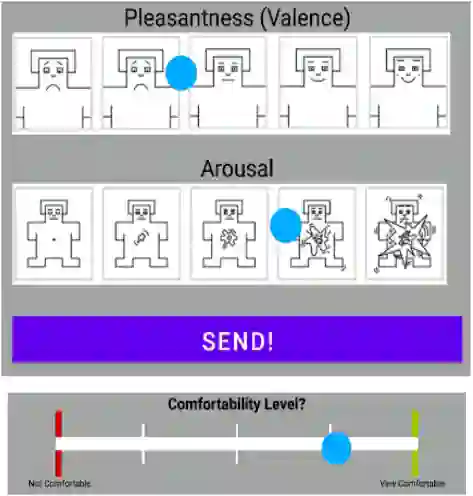
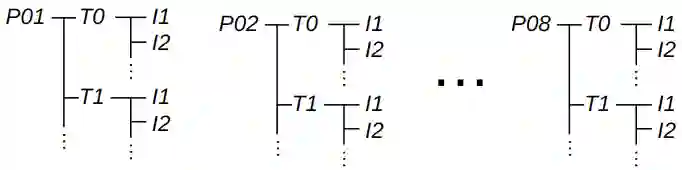
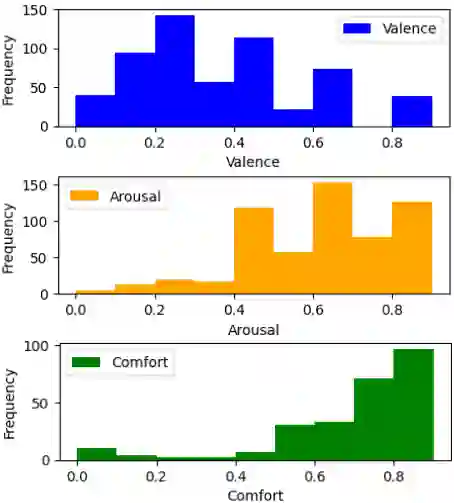
Many attempts have been made at estimating discrete emotions (calmness, anxiety, boredom, surprise, anger) and continuous emotional measures commonly used in psychology, namely `valence' (The pleasantness of the emotion being displayed) and `arousal' (The intensity of the emotion being displayed). Existing methods to estimate arousal and valence rely on learning from data sets, where an expert annotator labels every image frame. Access to an expert annotator is not always possible, and the annotation can also be tedious. Hence it is more practical to obtain self-reported arousal and valence values directly from the human in a real-time Human-Robot collaborative setting. Hence this paper provides an emotion data set (HRI-AVC) obtained while conducting a human-robot interaction (HRI) task. The self-reported pair of labels in this data set is associated with a set of image frames. This paper also proposes a spatial and temporal attention-based network to estimate arousal and valence from this set of image frames. The results show that an attention-based network can estimate valence and arousal on the HRI-AVC data set even when Arousal and Valence values are unavailable per frame.
翻译:许多研究尝试估计离散情绪(平静、焦虑、无聊、惊讶、愤怒)以及心理学中常用的连续情感度量,即“效价”(所表现情感的愉悦度)和“唤醒度”(所表现情感的强度)。现有的效价和唤醒度估计方法依赖于从数据集中学习,其中专家标注者需对每一帧图像进行标注。然而,获取专家标注者并不总是可行,且标注过程可能繁琐耗时。因此,在实时人机协作场景中,直接通过人类自我报告获取效价和唤醒度值更为实用。为此,本文提供了一个在执行人机交互任务过程中收集的情感数据集(HRI-AVC)。该数据集中自我报告的情感标签对与一组图像帧相关联。本文还提出了一种基于空间与时间注意力的网络,用于从这组图像帧中估计效价和唤醒度。结果表明,即使每帧图像缺乏独立的唤醒度和效价值,基于注意力的网络仍能在HRI-AVC数据集上有效估计效价和唤醒度。