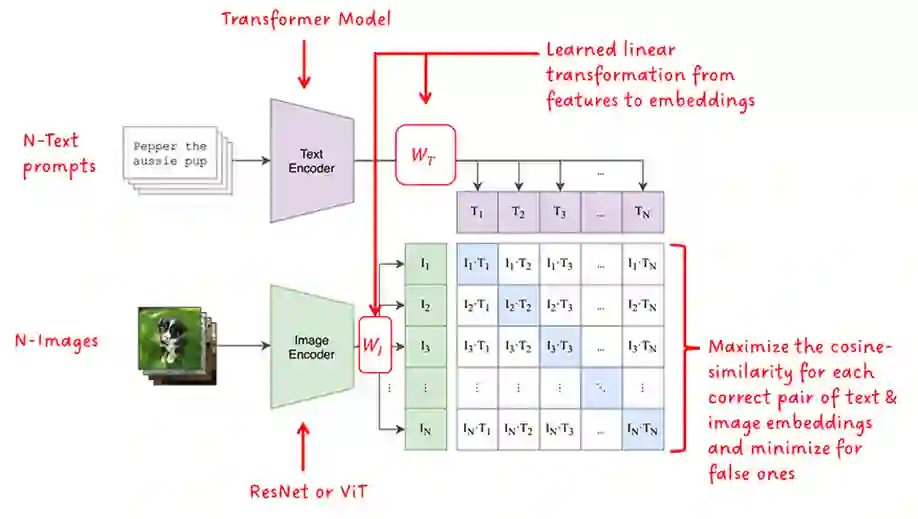
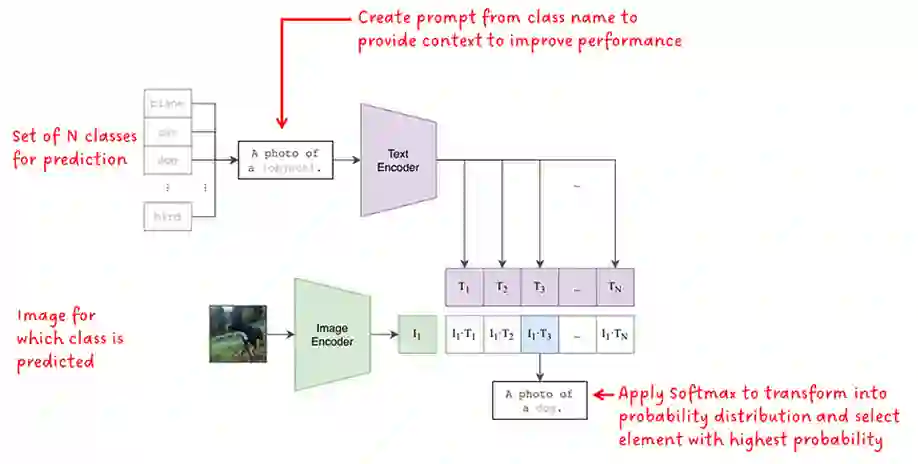
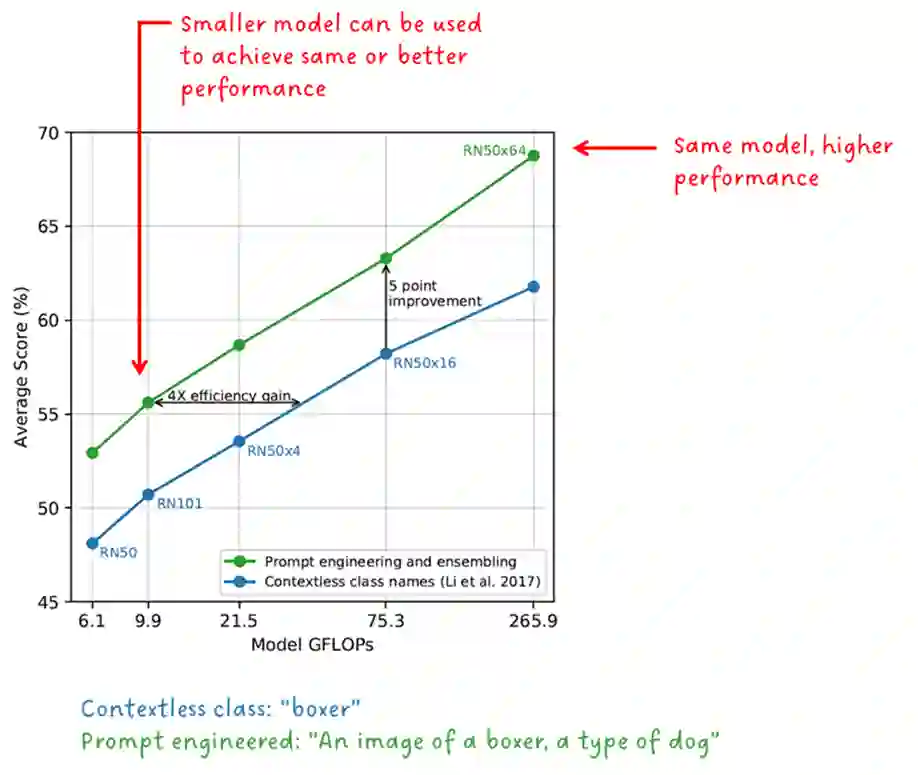
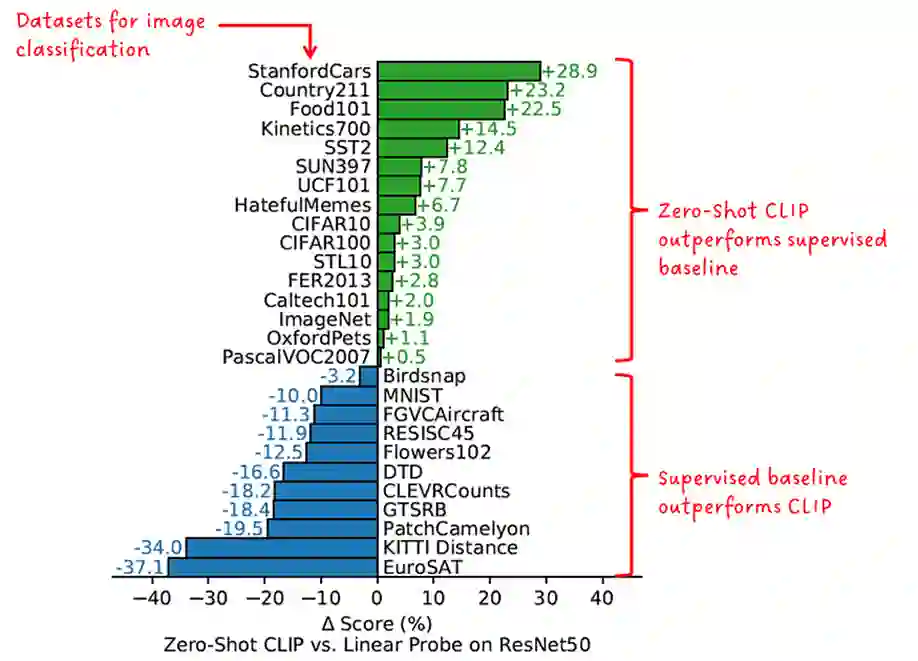
Photo search, the task of retrieving images based on textual queries, has witnessed significant advancements with the introduction of CLIP (Contrastive Language-Image Pretraining) model. CLIP leverages a vision-language pre training approach, wherein it learns a shared representation space for images and text, enabling cross-modal understanding. This model demonstrates the capability to understand the semantic relationships between diverse image and text pairs, allowing for efficient and accurate retrieval of images based on natural language queries. By training on a large-scale dataset containing images and their associated textual descriptions, CLIP achieves remarkable generalization, providing a powerful tool for tasks such as zero-shot learning and few-shot classification. This abstract summarizes the foundational principles of CLIP and highlights its potential impact on advancing the field of photo search, fostering a seamless integration of natural language understanding and computer vision for improved information retrieval in multimedia applications
翻译:照片搜索,即根据文本查询检索图像的任务,随着CLIP(对比语言-图像预训练)模型的引入取得了显著进展。CLIP采用视觉-语言预训练方法,学习图像与文本的共享表征空间,从而实现跨模态理解。该模型能够理解多样化图像与文本对之间的语义关系,支持基于自然语言查询的高效精准图像检索。通过在包含图像及其关联文本描述的大规模数据集上进行训练,CLIP实现了卓越的泛化能力,为零样本学习和少样本分类等任务提供了强大工具。本文摘要总结了CLIP的基本原理,并强调了其在推动照片搜索领域发展方面的潜在影响,促进了自然语言理解与计算机视觉的无缝集成,以改善多媒体应用中的信息检索效果。